




- @Demonslzh
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
文章目录数据介绍&分析目标数据分析〇、导入需要的库一、合并数据读表获取每个房间的设备信息合并所有表格二、数据清洗查看数据开关状态判断三、用电时间段频率统计(时间序列聚合)1、结果可视化2、统计每个用户一天中不同时间段的用电频率数据集+源码获取数据介绍&分析目标数据介绍这里先简单描述一下数据集文件。这里有6个用户的用电数据。以1号用户为例,点进building1内会有meter1-m
使用Docker搭建4核8G的服务器丝滑开玩

文章目录数据介绍&分析目标数据分析〇、导入需要的库一、合并数据读表获取每个房间的设备信息合并所有表格二、数据清洗查看数据开关状态判断三、用电时间段频率统计(时间序列聚合)1、结果可视化2、统计每个用户一天中不同时间段的用电频率数据集+源码获取数据介绍&分析目标数据介绍这里先简单描述一下数据集文件。这里有6个用户的用电数据。以1号用户为例,点进building1内会有meter1-m
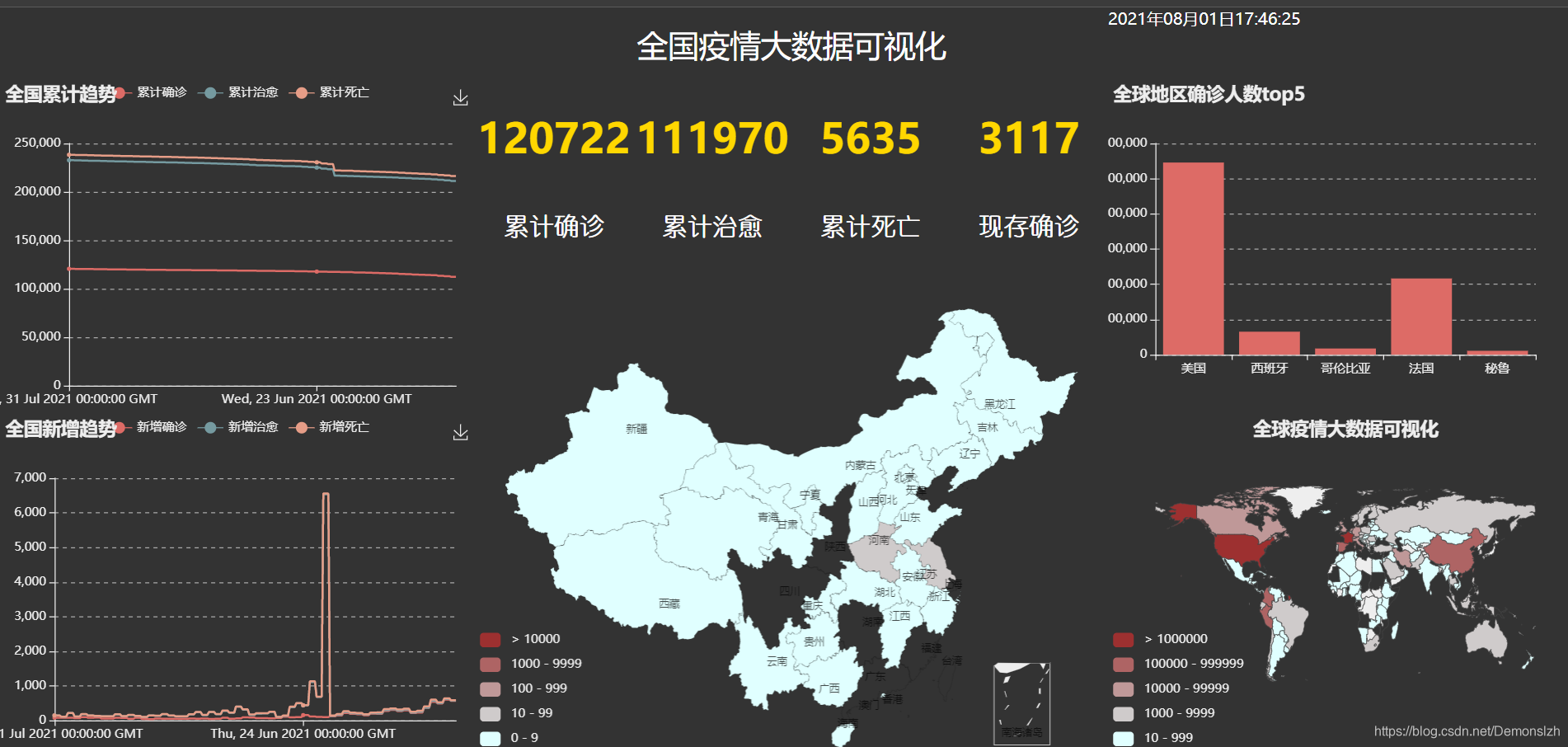
文章目录一、实现效果二、编写工具类utils从数据库中获取数据三、编写app.py四、ajax实现数据交互五、完整项目获取Python+Flask实现全国、全球疫情大数据可视化(二):爬取数据并保存至mysql数据库一、实现效果最近简单学习了一下flask,决定来做一个疫情大数据的网页出来。话不多说先上效果图。还是比较喜欢这样的排版的。二、编写工具类utils从数据库中获取数据我们首先要明确每个部
文章目录一、摸鱼思路二、阅读器实现思路三、实现1、拆分章节2、翻页4、完整代码四、效果展示& 源码(测试数据——诡秘之主)获取一、摸鱼思路在命令行中进行小说阅读,可以通过我们IDE编码界面做掩护,通过IDE开启一个小的终端以命令行的方式进行阅读,这样可以表现得正在努力调试代码的样子。二、阅读器实现思路准备好测试数据(小说的txt文件)将小说的源文档按章节进行拆分– 按章节阅读,上下章翻页每
文章目录一、关于基金定投数据来源接口规范常见指数基金/股票代码二、分析目标三、代码实现1、定义获取数据、清洗数据的函数2、定义定投策略函数3、计算2019年对**沪深300指数**基金进行定投的收益率4、假设定投的金额是500元,每周定投一次,据此**分别**计算从2002年开始到2019年,每年定投**沪深300指数基金**的收益率并将结果可视化5、实现"慧定投"(支付宝中的智能定投策略)定义定
一、数据来源整理之前的代码,发现了之前使用plotly做数据可视化的代码,贴上来做个记录。数据集为美国不同地区各个超市的不同商品的销量数据。需要这份数据集的可以见文末的下载地址。二、导入数据import pandas as pdimport plotly as pyimport plotly.graph_objs as goimport numpy as npdata=pd.read_excel(
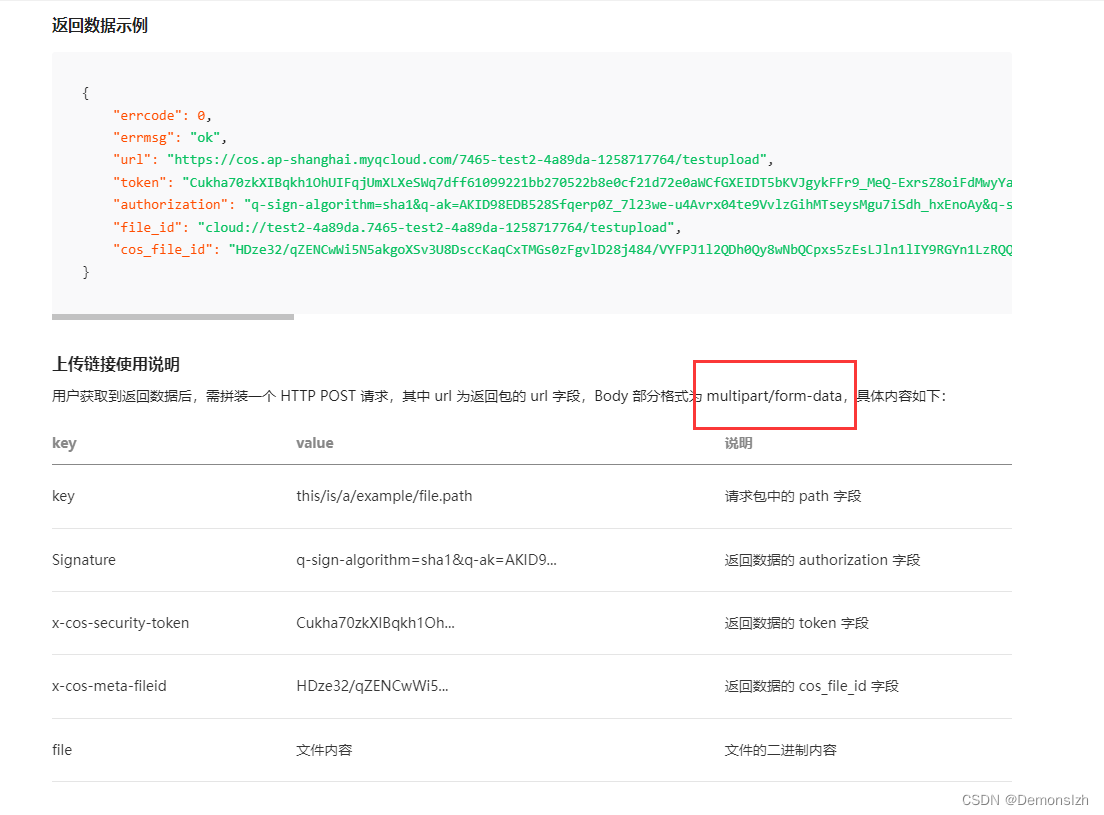
最近开发了一个进行源码展示的小程序。每次新增一个项目信息都会展示项目效果的演示图。因此在新增数据之前,需要把演示图先上传到云存储。基于此通过python实现文件的上传。
文章目录一、摸鱼思路二、阅读器实现思路三、实现1、拆分章节2、翻页4、完整代码四、效果展示& 源码(测试数据——诡秘之主)获取一、摸鱼思路在命令行中进行小说阅读,可以通过我们IDE编码界面做掩护,通过IDE开启一个小的终端以命令行的方式进行阅读,这样可以表现得正在努力调试代码的样子。二、阅读器实现思路准备好测试数据(小说的txt文件)将小说的源文档按章节进行拆分– 按章节阅读,上下章翻页每
背景介绍开发一款基于户外监控摄像头的山火/非法焚烧秸秆的预防系统。希望能够在最短的时间内基于监控画面确定是否有烟火发生,然后人工快速介入,确定是否是山火/非法焚烧秸秆的事件。最终交由当地的联防/公安/森林等部门进行快速响应。我们因此采集到了海量的户外图像,其中大致分为两类:没有任何烟火的图像,有明显的烟/火出现的图像。图像的获得是基于经过培训的人工判断然后直接从监控画面上截图。基于提供的图像,获得