- @2401_85378759
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
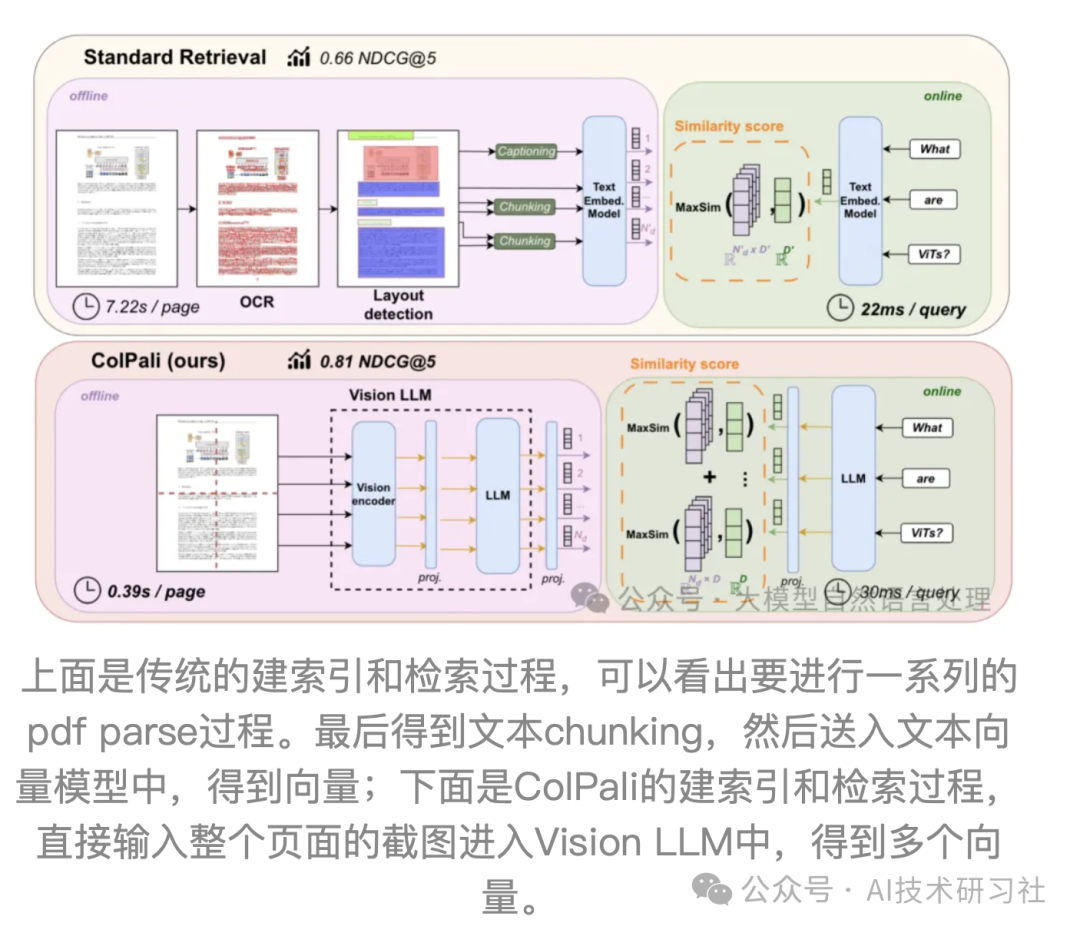
ColPali是一个新型的视觉检索模型,旨在通过视觉语言模型(VLM)实现高效的文档检索。该模型的核心在于利用ColBERT架构和PaliGemma模型,结合视觉信息和文本信息,以提高检索的准确性和效率。演示demo:https://huggingface.co/spaces/manu/ColPali-demo通过我们的新模型 ColPali,我们建议利用 VLM 在视觉空间中构建高效的多向量嵌入
今天给大家介绍一下关于dify和ragflow知识库整合案例,顺便给大家介绍一下ragflow。 话不多说,下面给大家演示一下效果。 我们首先看一下ragflow测试效果
文章分析了Dify v1.11.2版本发布后五天内出现的9个严重缺陷,涵盖性能、安全、功能稳定性和数据处理等多个领域。这些问题包括聊天消息加载异常、云服务执行时间不稳定、XSS安全漏洞、Agent节点配置错误等,严重影响开发者使用体验和工作效率。目前多数问题已被官方确认修复,但尚未发布正式修复版本,给开发者日常使用带来困扰。

摘要: 本教程提供Agent开发的系统性学习路径,涵盖从基础理论到实战项目的16章内容,包括Langchain、RAG、Agentic RL等技术。适合AI开发者、学生及自学者,通过旅行助手、赛博小镇等项目实践,掌握智能体框架设计、Memory系统等核心技能。教程配套完整代码与学习资料,帮助学习者从零构建专属Agent应用,并涵盖求职面试准备。(148字) 注:精简了技术术语堆砌,突出核心价值(系

文章详细介绍了智能体的概念、组成和应用。智能体是能自主决策、行动的"虚拟人"或系统,由大脑(大语言模型)、感知、行动、记忆和工具五部分组成。通过旅行规划智能体的例子,展示了智能体如何像私人助理一样理解模糊指令并自主完成任务。智能体已进入生活各方面,未来将发展为每个人的超级智能助理,同时也面临数据安全等挑战。

面对AI工具对编程行业的冲击,程序员可转型为AI应用工程师,尤其是LLM Agent方向。这一岗位需求年增长率达62.8%,薪资较传统岗位高20-30%。2025年AI代理市场规模预计达31亿美元,企业急需相关人才。建议从学习LLM基础概念和实践项目入手,成为AI的"操控者"而非"受害者",把握AI时代的职业新机遇。
本文系统介绍了AI智能体的概念和设计模式,详细区分了工作流模式(提示链、路由、并行化)和智能体模式(反思、工具使用、规划、多智能体)。文章强调智能体方案并非万能,需权衡成本与收益,并根据任务特性选择合适模式。工作流适用于步骤明确的任务,而智能体则更灵活适应复杂场景。实际应用中,这些模式可灵活组合,通过实证评估不断优化,切忌过度设计。
文章介绍了AI Agent作为AI应用核心的重要性及开发关键技术,包括Function Calling、Agent设计模式、LangChain/LangGraph框架及A2A多智能体协议。针对当前市场供需失衡、人才短缺的机遇,文章提供了从Python基础到平台化开发的系统学习路径,并推荐了《AI Agent开发实战》一书,通过实战项目帮助读者快速掌握模型调用、工具集成及系统构建能力,为抢占AI工程
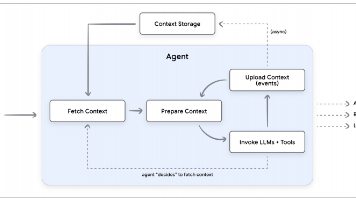
Google发布《Context Engineering》白皮书,宣告AI开发进入上下文工程时代。Context Engineering通过Session和Memory双脑机制,使大模型从无状态变为有状态。Session管理短期对话上下文,Memory负责长期知识存储,二者共同实现Agent的跨会话理解和个性化。生产环境需注意异步生成、用户隔离和防止记忆投毒。未来AI竞争将取决于Context E
本文全面介绍了RAG系统中的文档分块(Chunking)策略,从基础到高级详细解析了各种分块方法及其适用场景。重点讨论了分块对检索质量和生成响应的关键影响,对比了预分块与后分块策略,并详细介绍了固定大小、递归、基于文档、语义、LLM驱动、代理、后期、分层和自适应等多种分块技术。文章提供了选择最佳分块策略的指导原则和工具推荐,帮助开发者根据具体应用场景和数据特征优化RAG系统性能,提高检索准确性和生