登录社区云,与社区用户共同成长
邀请您加入社区
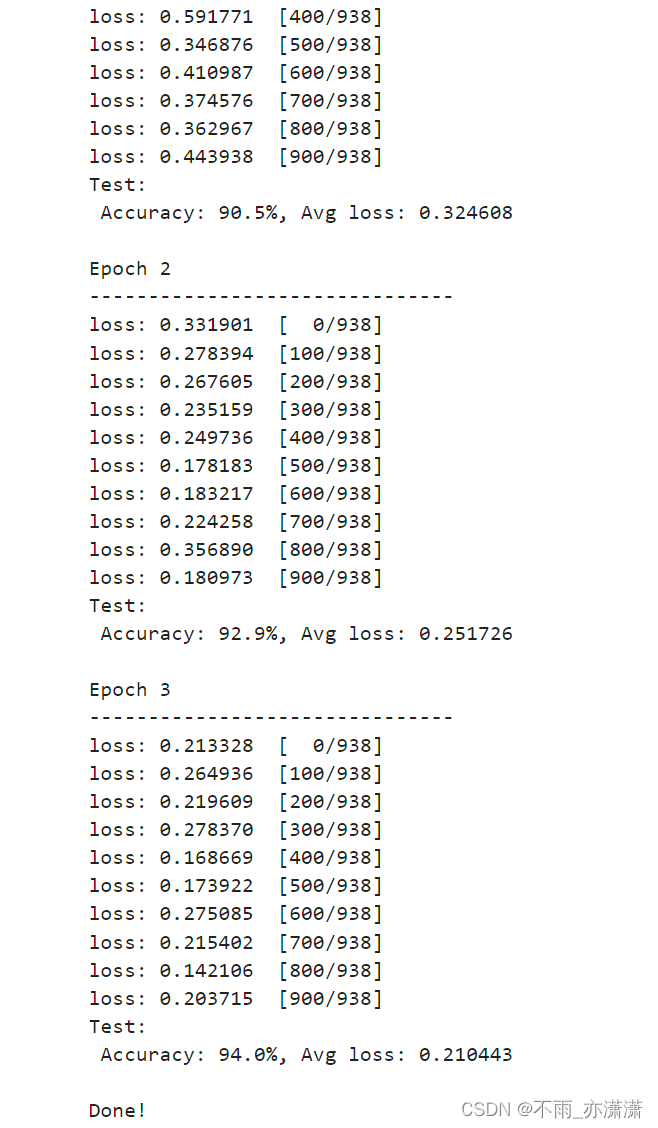
☀️ 第17天学习在实际应用场景中,由于训练数据集不足,所以很少有人会从头开始训练整个网络。普遍的做法是,在一个非常大的基础数据集上训练得到一个预训练模型,然后使用该模型来初始化网络的权重参数或作为固定特征提取器应用于特定的任务中。本章将使用迁移学习的方法对ImageNet数据集中的狼和狗图像进行分类。
情感分类是自然语言处理中的经典任务,是典型的分类问题。本节使用MindSpore实现一个基于RNN网络的情感分类模型,实现如下的效果:输入: This film is terrible正确标签: Negative预测标签: Negative输入: This film is great正确标签: Positive预测标签: Positive。
在官方提供的jupyter AI编程实践样例中,发现了这个项目:ChatGLM4-9B实践样例是智谱 AI 推出的最新一代预训练模型 GLM-4 系列中的开源版本。在语义、数学、推理、代码和知识等多方面的数据集测评中,及其人类偏好对齐的版本均表现出超越 Llama-3-8B 的卓越性能。除了能进行多轮对话,GLM-4-9B-Chat 还具备网页浏览、代码执行、自定义工具调用(Function Ca
通过这次学习与实践,我深刻体会到MindSpore在深度学习模型开发中的强大功能和易用性。从数据处理到模型构建,再到训练与测试,每一步都提供了详细的API支持和文档说明,使得整个流程更加流畅和高效。在未来的学习和研究中,我将继续探索MindSpore的更多高级功能,如分布式训练、自动微分和自定义算子等,进一步提升自己的深度学习能力。同时,也希望能将所学知识应用到实际项目中,为解决实际问题贡献自己的
相较于动态图而言,静态图的特点是将计算图的构建和实际计算分开(Define and run)。有关静态图模式的运行原理,可以参考静态图语法支持。在MindSpore中,静态图模式又被称为Graph模式,在Graph模式下,基于图优化、计算图整图下沉等技术,编译器可以针对图进行全局的优化,获得较好的性能,因此比较适合网络固定且需要高性能的场景。
ModelZoo(模型库):ModelZoo提供可用的深度学习算法网络,也欢迎更多开发者贡献新的网络(ModelZoo地址)。MindSpore Extend(扩展库):昇思MindSpore的领域扩展库,支持拓展新领域场景,如GNN/深度概率编程/强化学习等,期待更多开发者来一起贡献和构建。MindSpore Science(科学计算)
模块提供了一些常用的公开数据集和标准格式数据集的加载API。对于MindSpore暂不支持直接加载的数据集,可以构造自定义数据加载类或自定义数据集生成函数的方式来生成数据集,然后通过接口实现自定义方式的数据集加载。支持通过可随机访问数据集对象、可迭代数据集对象和生成器(generator)构造自定义数据集,下面分别对其进行介绍。
mindspore.ops模块提供的grad和value_and_grad接口可以生成网络模型的梯度。grad计算网络梯度,value_and_grad同时计算网络的正向输出和梯度。本文主要介绍如何使用grad接口的主要功能,包括一阶、二阶求导,单独对输入或网络权重求导,返回辅助变量,以及如何停止计算梯度。
昇思大模型入门学习
打卡的第一天,了解并初步认识昇思,从介绍文档知道:昇思MindSpore是一个全场景深度学习框架,旨在实现易开发、高效执行、全场景统一部署三大目标。其中,易开发表现为API友好、调试难度低;高效执行包括计算效率、数据预处理效率和分布式训练效率;全场景则指框架同时支持云、边缘以及端侧场景。经过对昇思的了解,迈入了大模型学习的第一步。
近些年,随着基于自注意(Self-Attention)结构的模型的发展,特别是Transformer模型的提出,极大地促进了自然语言处理模型的发展。由于Transformers的计算效率和可扩展性,它已经能够训练具有超过100B参数的空前规模的模型。ViT则是自然语言处理和计算机视觉两个领域的融合结晶。在不依赖卷积操作的情况下,依然可以在图像分类任务上达到很好的效果。本案例完成了一个ViT模型在I
平台给资源好评。
最近报名参加了,希望能掌握MindSpore的一些基础应用。第一天从 初学入门 / 初学教程 / 02-快速入门 开始。
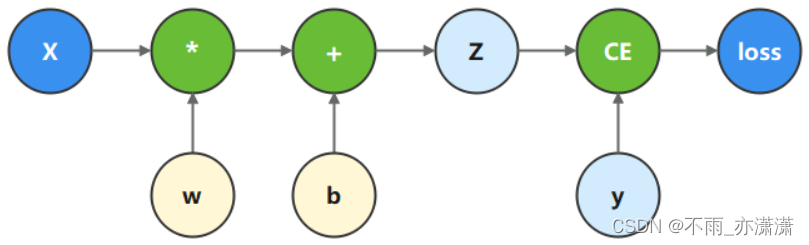
神经网络的训练主要使用反向传播算法,模型预测值(logits)与正确标签(label)送入损失函数(loss function)获得loss,然后进行反向传播计算,求得梯度(gradients),最终更新至模型参数(parameters)。自动微分能够计算可导函数在某点处的导数值,是反向传播算法的一般化。自动微分主要解决的问题是将一个复杂的数学运算分解为一系列简单的基本运算,该功能对用户屏蔽了大量
上一章节主要介绍了如何调整超参数,并进行网络模型训练。在训练网络模型的过程中,实际上我们希望保存中间和最后的结果,用于微调(fine-tune)和后续的模型推理与部署,本章节我们将介绍如何保存与加载模型。
从网络构建中加载代码,构建一个神经网络模型。nn.ReLU(),nn.ReLU(),超参(Hyperparameters)是可以调整的参数,可以控制模型训练优化的过程,不同的超参数值可能会影响模型训练和收敛速度。目前深度学习模型多采用批量随机梯度下降算法进行优化,随机梯度下降算法的原理如下:公式中, 𝑛 是批量大小(batch size), η 是学习率(learning rate)。另外, ?
第1天初步学习了MindSpore的基本操作。第2天初步学习了张量Tensor。第3天初步学习了数据集Dataset。第4天学习 初学入门 / 初学教程 / 05-数据变换 Transforms通常情况下,直接加载的原始数据并不能直接送入神经网络进行训练,此时我们需要对其进行数据预处理。MindSpore提供不同种类的数据变换(Transforms),配合数据处理Pipeline来实现数据预处理。
数据是深度学习的基础,高质量的数据输入将在整个深度神经网络中起到积极作用。MindSpore提供基于Pipeline的数据引擎,通过数据集(Dataset)和数据变换(Transforms)实现高效的数据预处理。其中Dataset是Pipeline的起始,用于加载原始数据。mindspore.dataset提供了内置的文本、图像、音频等数据集加载接口,并提供了自定义数据集加载接口。此外MindSp
最近报名参加了昇思25天学习打卡训练营。昨天初步学习了MindSpore的基本操作。第二天学习 初学入门 / 初学教程 / 03-张量 Tensor1. 代码跑通流程张量(Tensor)是一个可用来表示在一些矢量、标量和其他张量之间的线性关系的多线性函数,这些线性关系的基本例子有内积、外积、线性映射以及笛卡儿积。其坐标在 𝑛 维空间内,有 𝑛^𝑟 个分量的一种量,其中每个分量都是坐标的函数
本文深入解析了MobileNetV2的倒残差结构设计思想,并详细介绍了如何在昇思(MindSpore)框架中为26类垃圾分类任务定制轻量级模型。通过深度可分离卷积、倒残差结构和线性瓶颈层等技术,在保持模型轻量化的同时提升识别精度。文章还提供了垃圾分类数据集处理、模型微调策略及边缘部署实战技巧,帮助开发者在智能垃圾桶等边缘设备上实现高效实时识别。
众所周知,开源模式是降低创新门槛的和激发技术创新活力最为有效方式,而智谱GLM-Image开源,已经受到Hugging Face等知名平台的密切关注,未来有望吸纳更多开发者了解和加入到智谱GLM-Image项目之中,从而激发AI生图领域的迭代与创新。当市场充满不确定性时,在人工智能的“无人区”里,本就没有现成的路。GLM-Image模型强大的性能表现,及背后的全栈国产化训练历程,给出了一个极具参考
具体内容:1. 导包2. 创建模型nn.ReLU(),nn.ReLU(),3. 保存模型4. 加载模型要加载模型权重,需要先创建相同模型的实例,然后使用`load_checkpoint`和`load_param_into_net`方法加载参数。5. 保存MindIR除Checkpoint外,MindSpore提供了云侧(训练)和端侧(推理)统一的中间表示。可使用`export`接口直接将模型保存为
蒸馏版模型特点:选用Llama 3.1/3.3和Qwen 2.5的6个开源模型用R1生成80万条高质量推理数据基于监督微调(SFT)而非RL阶段最小规模的DeepSeek蒸馏模型(1.5B参数)
生成式对抗网络(Generative Adversarial Networks,GAN)是一种生成式机器学习模型,是近年来复杂分布上无监督学习最具前景的方法之一。生成器的任务是生成看起来像训练图像的“假”图像;判别器需要判断从生成器输出的图像是真实的训练图像还是虚假的图像。GAN通过设计生成模型和判别模型这两个模块,使其互相博弈学习产生了相当好的输出。GAN模型的核心在于提出了通过对抗过程来估计生
序列标注指给定输入序列,给序列中每个Token进行标注标签的过程。序列标注问题通常用于从文本中进行信息抽取,包括分词(Word Segmentation)、词性标注(Position Tagging)、命名实体识别(Named Entity Recognition, NER)等。输入序列清华大学座落于首都北京输出标注BIIIOOOOOBI如上表所示,清华大学和北京是地名,需要将其识别,我们对每个输
中国,杭州,2025年12月25日] 今日,昇思人工智能框架峰会在杭州国际博览中心召开,本次大会以“昇思MindSpore为超节点而生的AI框架 ”为主题,由昇思MindSpore开源社区、全球计算联盟GCC主办,华为技术有限公司和OSCHINA开源中国、AtomGit、Gitee、AITISA新一代人工智能产业技术创新战略联盟、OpenI启智社区、魔乐社区、焕新社区、书生社区、司南社区联合承办。
昇思MindSpore2.0擢升科学计算与全场景能力
流程: 权重加载 -> 启动推理 -> 效果比较与调优 -> 性能测试 -> 性能优化权重加载如微调章节介绍,最终的模型包含两部分:base model 和 LoRA adapter,其中base model的权重在微调时被冻结,推理时加载原权重即可,LoRA adapter可通过PeftModel.from_pretrained进行加载。
昇思人工智能框架峰会的召开将为国内人工智能技术,特别是大模型的发展注入新的动力和活力,为人工智能发展开启新的篇章。本次峰会由昇思MindSpore开源社区、AITISA主办,华为和OpenI启智社区协办,包含1场主题演讲,4场专题论坛,1场闭门圆桌,此外,昇思开源社区将为杰出贡献者进行表彰,为昇思MindSpore模型开发挑战赛金奖、杰出开发者、杰出布道师颁奖。昇思MindSpore 是开源的AI
“第七届·2025 MindSpore量子计算黑客松全国大赛”火热来袭!热身赛、量子组合优化、量子误差缓解、量子启发算法赛道已发布赛题。无论您是初学小白,还是技术达人,参赛即有收获!诚邀报名参赛,勇攀量子世界的高峰,挑战黑客松年度总冠军,赢取属于你的荣誉和机遇!
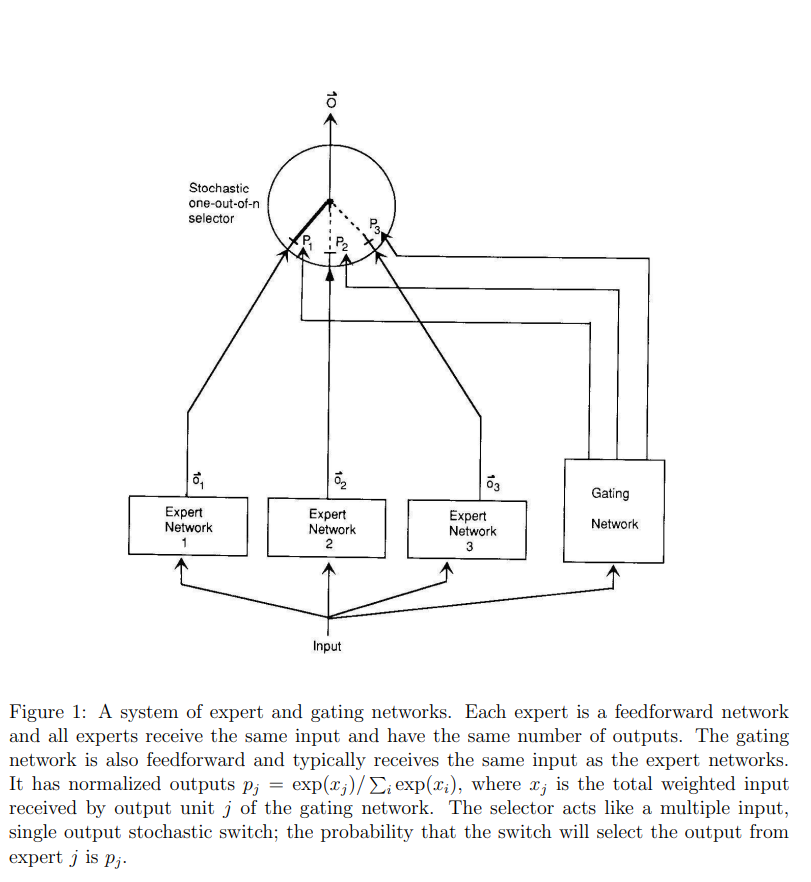
为了实现大模型的高效训练和推理,混合专家模型MoE便横空出世。
昇思
——昇思
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 昇腾开源生态专区
昇腾开源生态专区

























 鲲鹏昇腾开发者社区
鲲鹏昇腾开发者社区


 2048 AI社区
2048 AI社区





 脑启社区
脑启社区


 华为开发者空间
华为开发者空间