登录社区云,与社区用户共同成长
邀请您加入社区
@羲凡——只为了更好的活着DolphinScheduler docker-compose安装(配置邮件)前期准备安装 docker安装 docker-compose安装快速试用 Docker 部署 官方文档1.下载mkdir -p /opt/modules/dolphinschedulercd /opt/modules/dolphinschedulerwget https://mirrors.tu
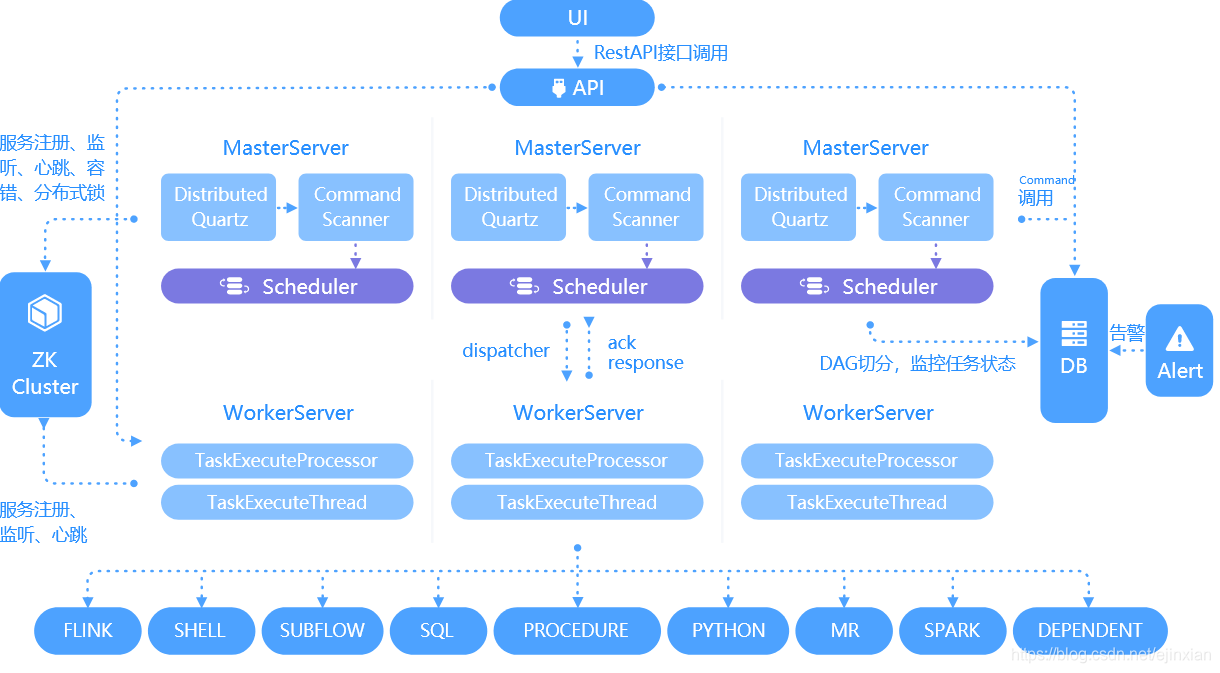
Apache DolphinScheduler 是一个分布式易扩展的可视化DAG工作流任务调度开源系统。适用于企业级场景,提供了一个可视化操作任务、工作流和全生命周期数据处理过程的解决方案。Apache DolphinScheduler 旨在解决复杂的大数据任务依赖关系,并为应用程序提供数据和各种 OPS 编排中的关系。解决数据研发ETL依赖错综复杂,无法监控任务健康状态的问题。
Apache DolphinScheduler 分布式易扩展的可视化DAG工作流任务调度系统Apache DolphinScheduler是一个分布式去中心化,易扩展的可视化DAG工作流任务调度系统。致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程中开箱即用Apache DolphinScheduler 架构Apache DolphinScheduler 特性以DAG图的方式将
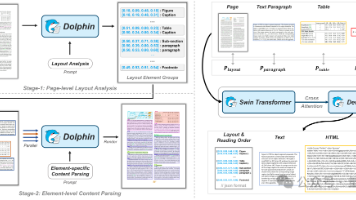
字节跳动刚刚开源一款全新文档解析模型——Dolphin。与目前市面上各类大模型相比,这款轻量级模型不仅体积小、速度快,并且取得了令人惊艳的性能突破,解析效率提升近2倍。测试结果显示,Dolphin在文档解析任务上解析准确率超越了GPT-4.1、Claude3.5-Sonnet、Gemini2.5-pro、Qwen2.5-VL等通用多模态大模型,以及最近推出的号称最强OCR大模型的Mistral-O
Apache DolphinScheduler是一个分布式易扩展的可视化DAG工作流任务调度开源系统,旨在解决复杂的大数据任务依赖关系,并为应用程序提供数据和各种 OPS 编排中的关系。DolphinScheduler 以 DAG(Directed Acyclic Graph,DAG)流式方式组装任务,可以及时监控任务的执行状态,支持重试、指定节点恢复失败、暂停、恢复、终止任务等操作。解决数据研发
Dolphin
——Dolphin
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net




 腾讯云开发者社区
腾讯云开发者社区

 魔乐社区
魔乐社区



 火山引擎 ADG 社区
火山引擎 ADG 社区

 DAMO开发者矩阵
DAMO开发者矩阵

