




- @yuange1666
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
当前AI Agent进入规模化落地阶段,企业端部署需求激增,全球市场高速扩容,金融、办公、制造等垂直场景需求旺盛,MCP凭借统一工具调用标准成为行业通用接入规范,大幅降低多模型与异构系统对接成本arXiv。商业模式以AaaS订阅、API按量计费、私有化定制部署、MCP工具集市分成为主,中小企业选用轻量化订阅,大型企业采用私有部署与项目定制收费。技术栈以Claude/GPT等基座大模型为核心,搭配L

当前AI Agent进入规模化落地阶段,企业端部署需求激增,全球市场高速扩容,金融、办公、制造等垂直场景需求旺盛,MCP凭借统一工具调用标准成为行业通用接入规范,大幅降低多模型与异构系统对接成本arXiv。商业模式以AaaS订阅、API按量计费、私有化定制部署、MCP工具集市分成为主,中小企业选用轻量化订阅,大型企业采用私有部署与项目定制收费。技术栈以Claude/GPT等基座大模型为核心,搭配L
当前AI Agent进入规模化落地阶段,企业端部署需求激增,全球市场高速扩容,金融、办公、制造等垂直场景需求旺盛,MCP凭借统一工具调用标准成为行业通用接入规范,大幅降低多模型与异构系统对接成本arXiv。商业模式以AaaS订阅、API按量计费、私有化定制部署、MCP工具集市分成为主,中小企业选用轻量化订阅,大型企业采用私有部署与项目定制收费。技术栈以Claude/GPT等基座大模型为核心,搭配L
当前AI Agent进入规模化落地阶段,企业端部署需求激增,全球市场高速扩容,金融、办公、制造等垂直场景需求旺盛,MCP凭借统一工具调用标准成为行业通用接入规范,大幅降低多模型与异构系统对接成本arXiv。商业模式以AaaS订阅、API按量计费、私有化定制部署、MCP工具集市分成为主,中小企业选用轻量化订阅,大型企业采用私有部署与项目定制收费。技术栈以Claude/GPT等基座大模型为核心,搭配L
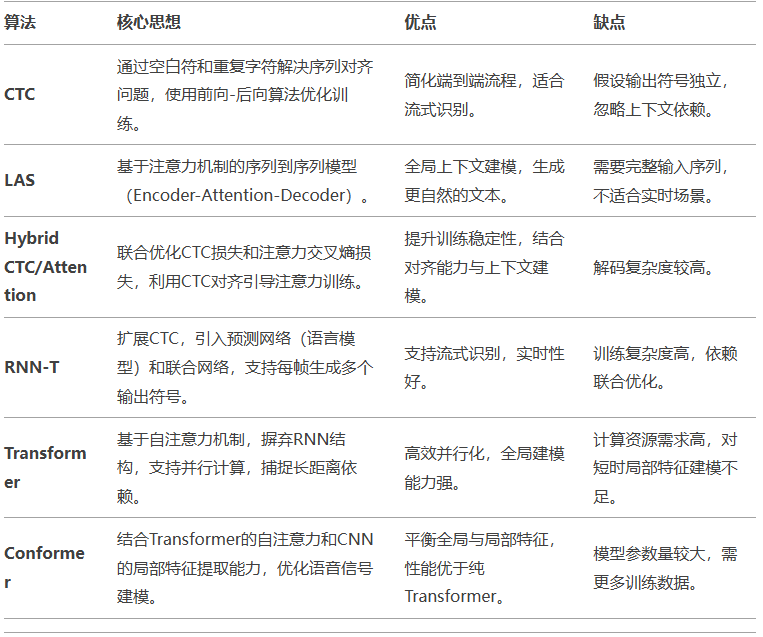
Conformer:在Transformer中嵌入卷积模块(如Convolution Module),利用CNN提取局部声学特征,同时保留自注意力的全局建模能力。技术演进主线:从CTC的序列对齐,到注意力机制的上下文建模,再到Conformer的全局-局部特征融合,语音识别逐步向高效、高精度、低延迟方向发展。RNN-T:在CTC基础上引入预测网络(语言模型)和联合网络,允许每帧生成多个符号,支持实
MCP(Model Context Protocol,模型上下文协议)是由Anthropic公司提出的一种开源协议,旨在让AI模型能够无缝连接外部工具和资源,就像一把“万能钥匙”,打通了AI与现实世界的交互通道。MCP发布于2024年11月,但起初并未引起太多关注,随着今年智能体(Agent)技术的爆发式发展,MCP逐渐成为开发者关注的焦点。今年2月,Cursor宣布支持MCP功能,进一步推动了这

通过这个用ResNet50进行对中药材的种类及品阶进行12分类的项目,学习mindspore AI框架的使用和深度学习任务的一般流程,熟悉如何通过深度学习的方式来拟合数据,处理生产生活中的问题,为AI赋能的时代贡献点滴实践。

现阶段,项目的架构流程已经跑通,接下来重点要做的是模型调优,以及优化前段展示等工作,希望基于本项目,可以带动大家学习人工智能NLP领域的兴趣和积极性,一起完善、共建这个项目,开发一个app来实现个性化的歌词生成!

通过这个用ResNet50进行对中药材的种类及品阶进行12分类的项目,学习mindspore AI框架的使用和深度学习任务的一般流程,熟悉如何通过深度学习的方式来拟合数据,处理生产生活中的问题,为AI赋能的时代贡献点滴实践。

DeepSeek通过其创新的架构设计,为人工智能的发展贡献了显著价值。首先,它引入了多Token预测机制,提高了模型在处理复杂数据时的效率和准确性。其次,DeepSeek的MOE架构无需负载均衡,简化了模型训练流程,降低了计算资源的消耗。最后,通过结合KV Cache的MLA技术,DeepSeek显著提升了推理速度,使得AI应用在实时性要求高的场景下更具可行性。这些创新不仅推动了AI技术的进步,也
