




- @yeez_tech007
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
该数据集包含10,796条智能体运行轨迹,涵盖安全(Security)和内容安全(Safety)两大维度,提供防御机制启用/未启用的对比数据。数据集采用Open Telemetry标准,记录完整攻击元数据、风险评分及调用链信息,支持分析智能体在XSS注入、隐私泄露等攻击场景下的脆弱性。安全数据包含5类攻击(DIO/IIO/ADD等),66.85%为高风险;内容安全数据覆盖7个子类(如暴力、仇恨言论

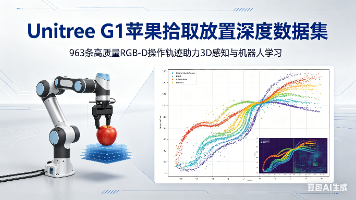
Unitree G1苹果拾取放置深度数据集提供了963条高质量RGB-D操作轨迹,包含同步的深度图像和RGB视频数据。该数据集基于MuJoCo和RoboCasa仿真平台构建,采用CuRobo运动规划生成无碰撞轨迹,包含28-DOF双臂机器人完整关节控制数据。数据集特点包括:256×256像素深度图像(共277,592帧)、多模态同步数据、100%无碰撞轨迹,支持3D感知、机器人操作学习和Sim-t
TCM-Vision是一个包含7204条中医药多模态问答对的数据集,涵盖中药饮片、中药材、舌诊、手诊等7大类别。每条数据包含高清图像、问题描述、多选项及答案标注,源自权威中医药典籍。该数据集采用标准化格式,各类别分布均衡,答案选项设计合理,支持中医药AI模型的训练与评测。数据样例展示不同类别的问答对结构,适用于图像分类、视觉问答等多模态任务,为中医智能化研究提供可靠基准。

本文介绍了一个综合机器学习数据集集合,包含基因表达、时间序列、分类等多种数据类型,适用于各类机器学习任务。数据集以R数据文件和文本文件格式提供,总样本量超过7000条,具有高维特征(如golub数据集的7129个特征)和完整标注。数据优势体现在多样性、完整性、可复现性和实用性,能够支持算法开发、性能评估和实际应用。应用场景涵盖癌症诊断、时间序列预测、分类算法评估和回归问题研究。该数据集集合为科研和
本数据集包括了PVDAQ系统提供的两个光伏系统(2105和2107)2017-2023年的运行数据,包含逆变器性能、环境参数等多维度监测指标。数据集具有三大核心优势:数据完整性高(关键字段完整度达99%以上)、时间跨度长(6年连续数据)、系统多样(110kW和893kW两种规模)。报告详细展示了数据字段、时间分布和系统特征,并通过具体样例说明了数据应用价值。该数据集可用于光伏系统性能评估、发电预测

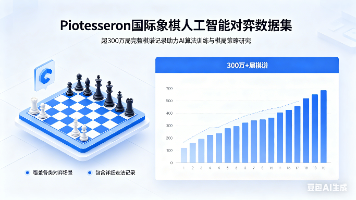
Piotesseron国际象棋AI对弈数据集包含超过300万局完整棋谱记录,为人工智能算法训练和棋局策略研究提供了丰富资源。该数据集记录了AI自我对弈的完整信息,包括游戏基本信息、走棋序列、开局类型、Elo等级评分和学习迭代次数等关键数据。数据覆盖8种主流开局类型,游戏结果呈现均衡分布,Elo等级范围从1000到3500,平均游戏时长3630毫秒。数据集优势在于规模庞大(301万局)、完整性高(核
摘要 本数据集包含10,863张高质量药片图像(训练集9,506张,验证集1,357张),标注了91,579个药片实例,平均每张图像含8.43个目标。数据整合自9个权威来源,涵盖多种拍摄条件和分辨率(300x246至1024x1024),采用标准YOLO格式标注。特点包括:大规模多样化样本、完整原始图像、精确边界框标注、负样本支持及预划分训练/验证集。该数据集专为医疗AI应用设计,可直接用于药片检

波斯手写数字识别数据集包含15万张高质量阿拉伯数字手写体图像,涵盖0-9共10个类别,训练集10万张、测试集5万张。所有图像均为28×28像素的灰度JPEG格式,采用目录结构标注,类别分布均衡。该数据集填补了波斯数字识别研究空白,具有标准化、大规模、高质量等特点,适用于深度学习模型训练、多语言识别系统构建等应用场景,对推动波斯文字识别技术发展具有重要价值。

本文介绍了一个包含1100张图像的农作物识别数据集,涵盖小麦、甘蔗、黄麻、玉米和水稻五大类。数据集特点包括:类别均衡分布(每类约200张)、四种数据增强方式(原始、移位、翻转、旋转)、完整结构化标注。该数据集适用于深度学习模型训练、农业遥感分析、移动端识别应用和农业机器人开发等场景,能有效提升作物分类精度和模型泛化能力。所有图像已预处理为标准格式,可直接用于计算机视觉算法研发。

本研究构建了一个包含1460张PNG格式图像的炸香蕉片真假识别数据集,为食品真伪鉴别和计算机视觉研究提供高质量数据支撑。数据集包含真实和虚假两类样本各730张,采用平衡设计确保训练公平性。图像涵盖224×224和422×422两种尺寸,平均文件大小约129KB,总存储量187MB。所有样本经过严格筛选,保留了原始细节信息,并包含多样化拍摄场景。该数据集具有类别均衡、格式无损、标注清晰等特点,适用于
