- @xiao_ling_yun
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
python spark 处理数据时,经常使用pandas DataFrame这样的数据格式,这里解析常见的函数explode()

将onnx模型部署为接口后,使用 onnxruntime-gpu 进行持续推理,运行时间久显存逐渐递增无法减少
自然语言领域中语言模型一般划分为两类:AR(AutoRegressive Language Modeling)和AE(AutoEncoding Language Modeling),两类模型的定义、数学表示、代表作以及优缺点
我们知道很多NLP模型(Transformer, Bert)输入的其中一部分是句子的token,然后结合位置编码进入到Mutil-Head Self Attention Layer,后者大家都很熟悉,但如何获得token,却很少有人讲解,这一部分也一度令我疑惑。获得句子的token,操作被称为:tokenization。是NLP任务中最基础、最先需要进行的一步,该操作的目的是将输入文本分割成单独的
1. 批量归一化(BN)(1) 一般来说在CV深度学习模型训练中,我们是要在卷积层后加入BN层的,原因来于Feature map在经过卷积层后,特征分布可能会有变化,BN就是为了解决这个问题加入的,它使得feature map的分布重新归于均值0和方差1,但是一般的归一化就是分子减去均值,分母是方差的开跟,这有一个严重的问题,见(2)。(2) 如果对feature map使用单纯的归一化操作,就可
自然语言领域中语言模型一般划分为两类:AR(AutoRegressive Language Modeling)和AE(AutoEncoding Language Modeling),两类模型的定义、数学表示、代表作以及优缺点
说实话ResNet的网络结构参数真没有什么可以解读的,在本博客中我们主要了解(1)传统深度学习网络的退化问题(2)残差结构(3)残差结构如何解决退化问题(4)残差结构还有什么其他作用
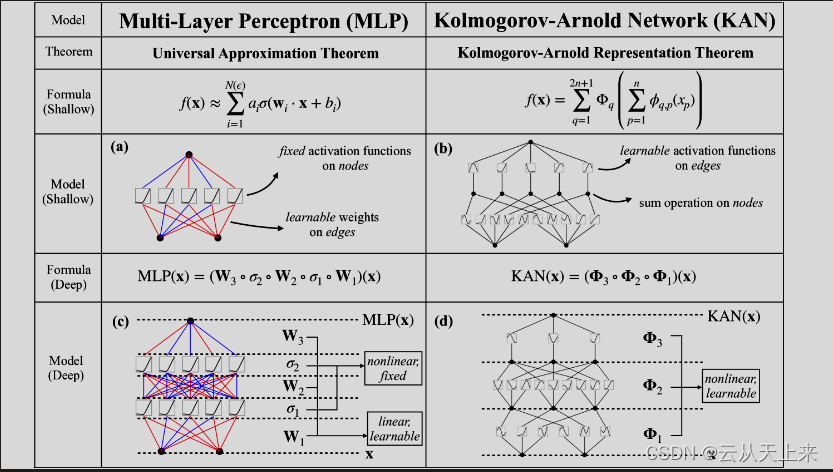
24年新神经网络结构KAN论文学习 + 解析,KAN有望作为MLP的更优平替