- @weixin_51455837
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要: 本文针对Windows用户使用Ollama时C盘空间不足的问题,提供两种迁移方案: 全新安装方案:通过安装命令参数指定D盘路径,并设置OLLAMA_MODELS环境变量强制模型存储到D盘; 已有数据迁移方案:通过复制.ollama目录到D盘并创建符号链接,实现零数据丢失迁移。两种方法均需管理员权限,强调路径规范(纯英文无空格),并详细解释了符号链接机制与环境变量的持久性。最终帮助用户在不影
依存分析(Dependency Parsing)是自然语言处理(NLP)中的一项任务,目的是确定句子中单词之间的依存关系,并将这些关系表示为一个有向图,通常称为依存树。在依存树中,每个节点代表一个单词,而有向边表示单词之间的语法关系,如主谓关系、动宾关系等。依存分析与短语结构分析(Phrase Structure Parsing)不同,它不关注短语的组合,而是直接关注单词之间的直接关系。依存分析的
在深度学习和其他机器学习任务中,F1分数和F2分数是评估分类模型性能的指标,特别是在二分类问题中。它们都是基于精确率(Precision)和召回率(Recall)的,但权重不同。
除了上述方法,还有一些其他的NER方法,如基于词典的方法、基于规则的方法、基于机器学习的方法(如隐马尔可夫模型HMM、条件随机场CRF等),以及基于深度学习的方法(如RNN-CRF、CNN-CRF、BiLSTM-CRF等)。:这是最基本的序列标注方法,使用三个标签:B(Begin)表示实体的开始,I(Inside)表示实体内部的词,O(Outside)表示非实体部分。命名实体识别(NER)是自然语
标注过程中可能需要使用多种工具和方法,完成后还需进行质量检查和验收,最终将数据转换为适合模型使用的格式并进行交付。整个过程需要细致的态度和严谨的流程,以确保数据的质量和模型的性能。文本数据标注是机器学习和人工智能领域中的一个重要环节,它涉及将文本中的信息进行分类、识别和标记,以便机器学习模型能够更好地理解和处理这些数据。标注后的数据通常用于训练机器学习模型,如自然语言处理(NLP)模型,以提高模型
在深度学习中,归一化和批量归一化是两种常用的技术,它们有助于提高模型的训练效率和性能。
例如,使用PyTorch实现TextCNN进行中文文本分类的案例中,首先需要对中文文本进行分词和词向量转换,然后构建TextCNN模型,包括卷积层、池化层和分类层。它将卷积神经网络(CNN)应用于文本数据,通过使用不同大小的卷积核来提取文本中的局部特征,类似于捕捉不同长度的n-gram信息,从而有效地捕捉局部相关性。在实际案例中,可以通过配置文件设置训练参数,如批量大小、学习率、优化器类型等,然后
这是因为较大的批次大小提供了更稳定但可能较不精确的梯度估计,而较大的学习率可以帮助模型在优化过程中迈出更大的步伐。较大的数据集可能允许使用较大的批次大小,而较小的数据集可能需要较小的批次大小以确保模型能够从每个批次中学习到有效的信息。最终,确定最佳学习率和批次大小通常需要结合具体任务、数据集和模型的特点,并通过实验来不断调整和优化。:在训练过程中,可能需要使用学习率调度策略,如学习率衰减或warm
Ollama作为一个大模型的部署工具,为了提高它的运行效率,把一些配置参数固定死了。因此,不能完整的使用到大模型的真正的功能,例如:有32k上下文的大模型,通过Ollama部署运行后,若输入的文本超过2048K,模型就会返回文本摘要。其实不是大模型本身会对超长文本进行自动摘要,是因为Ollama内置了默认的2048K的上下文窗口,限制了大模型对于长文本的能力。
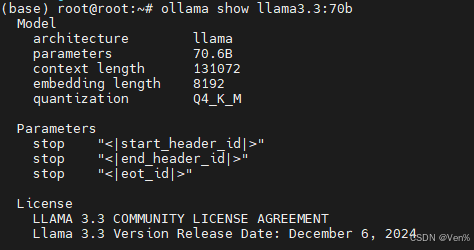
下载好了ollama,也run了模型,跑起来。但是不知道ollama拉下来的模型到底放在哪里了?如果需要使用不同的目录,将环境变量OLLAMA_MODELS设置为您选择的目录。