- @weixin_47505105
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
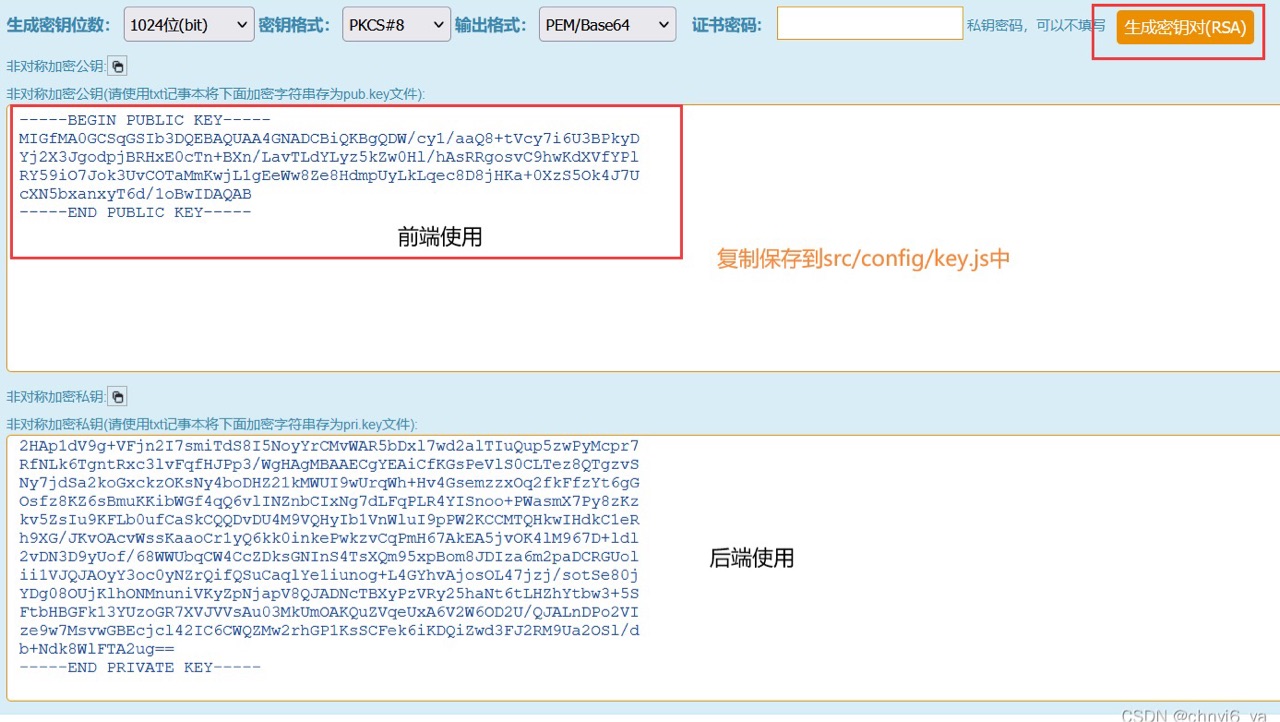
原来功能的不足:当登录成功之后,打开调试面板,找到“网络”,在请求体中会看到密码,这是不安全的。这是因为:http协议是明文传输,只要别人一抓包就可以获取到传输的报文。本文介绍了如何使用RSA加解密的流程,包括前端和后台的修改。
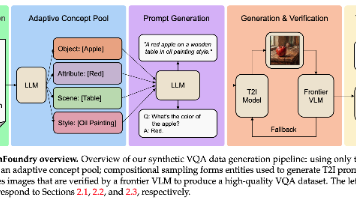
Benchmark来源测什么设计思路MMVPVLM 的视觉感知盲区找 CLIP 编码器认为相似、但视觉内容实际不同的图像对出题,排除模型靠语言先验猜答案的可能。pair 模式要求一对都答对才算对,single 模式单张独立评分深度排序与 3D 空间理解把经典 CV 数据集(COCO、Omni3D 等)改造成 VQA 格式,利用已有的 3D 标注生成精确 ground truth,测"哪个物体离镜头
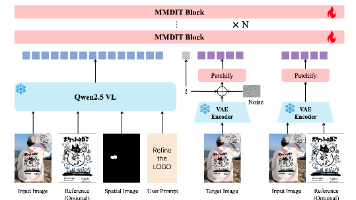
本文提出RefineAnything,一种针对图像局部细节修复的多模态区域精细化方法。针对现有模型在区域可控性、微细节恢复和背景漂移方面的问题,作者设计了Focus-and-Refine机制:通过区域裁剪-聚焦生成-无缝粘贴的三步策略,显著提升局部修复质量。方法基于Qwen-Image构建,结合多模态编码器和VAE潜空间表示,仅需LoRA微调。为支持训练,构建了包含30K样本的Refine-30K
尝试了很多方法,即使从本地删掉也没有用,问gpt说是因为虽然从本地删掉,但是已经提交到Git的历史记录了。是要从历史记录中删掉的文件。就能成功传到远程仓库了。

在 Git 中,origin 是默认的远程仓库名称。这个命令会列出所有配置的远程仓库及其名称,其中 origin 通常是克隆时自动设置的默认远程仓库名称。将<new-url>替换为你想设置的新远程仓库 URL。

下面的代码我把导入第三方包相关的代码都省略了。

核心思想:PPO是OpenAI提出的强化学习算法,通过来保证训练稳定。

在Llava1.5-7b进行微调,微调数据是Imagenet-1.28M 和原始665K LLAVA 的instruction-tuning数据,能够显著提高Llava1.5-7b在ImageNet上的分类能力,以及在ImageWikiQA的表现。作者发现:prompt的变化、减少context中的 label set size、让VLM执行概率推断(probabilistic inference

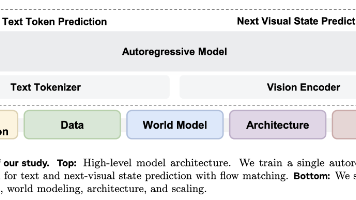
论文信息:Shengbang Tong, David Fan, John Nguyen 等 (FAIR, Meta & NYU),2026年3月。