




- @weixin_43960370
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
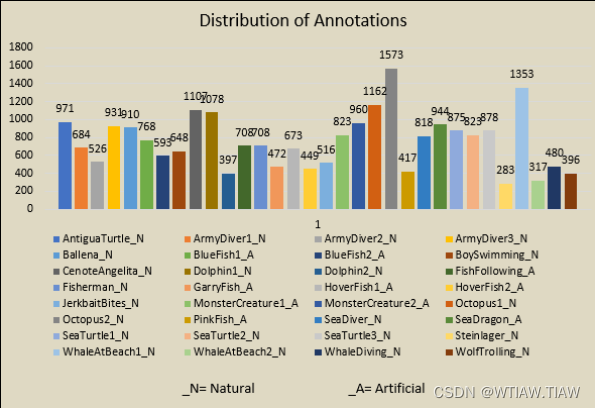
作者联系方式: landrykezebou@gmail.com, panettavisonsensinglab@gmail.com。MOTChallenge Underwater:该数据集包含了水下目标追踪的视频序列和相应的注释,视频序列来自于不同的场景和视角。The PETS 2009 dataset:该数据集包含了水下目标检测和追踪的视频序列,视频序列来自于一个水下实验室。The CoLin
这个工具可以非常方便的画出各种类型的图,是下面这位小哥哥开发的,来自于麻省理工学院弗兰克尔生物工程实验室, 该实验室开发可视化和机器学习工具用于分析生物数据。可以绘制的图包括以节点形式展示的FCNN style,这个特别适合传统的全连接神经网络的绘制。以平铺网络结构展示的LeNet style,用二维的方式,适合查看每一层featuremap的大小和通道数目。以三维block形式展现的AlexNe

由于其固有的特性,小目标在多次下采样后的特征表示较弱,甚至在背景中消失。FPN简单的特征拼接在信息传递中引入了不相关的上下文,进一步降低了小物体的检测性能。为了解决上述问题,我们提出了简单但有效的FE-YOLOv5。(1) 我们设计了来捕捉小目标更具辨别力的特征。全局注意力 和 高级全局上下文信息用于指导浅层的高分辨率特征。全局注意力与跨维度特征交互,减少信息丢失。高级上下文通过非局部网络对全局关

余弦退火算法是一种优化算法,通常用于训练神经网络等模型。它的主要思想是动态调整学习率,使得模型可以更快地收敛并获得更好的性能。余弦退火算法的原理比较简单,其核心在于使用余弦函数来动态地调整学习率。具体地,算法将学习率从初始值逐步降低到最小值,并在此后保持不变。通过这种方式,余弦退火算法可以在训练过程中缓慢降低学习率,从而避免在训练过程中出现梯度下降过快导致的震荡现象,进而提高模型的训练稳定性和泛化

这个工具可以非常方便的画出各种类型的图,是下面这位小哥哥开发的,来自于麻省理工学院弗兰克尔生物工程实验室, 该实验室开发可视化和机器学习工具用于分析生物数据。可以绘制的图包括以节点形式展示的FCNN style,这个特别适合传统的全连接神经网络的绘制。以平铺网络结构展示的LeNet style,用二维的方式,适合查看每一层featuremap的大小和通道数目。以三维block形式展现的AlexNe
(从公众号转发过来发现图片不能引用,直接点上面链接吧)昨天的文章介绍了在学习Deep Learning过程中必须背熟的十几条知识点,主要让大家有个对深度学习的整体认识,有了对知识点的认识,然后可以针对不理解或不熟悉的point再单个的深入挖掘。今天想给大家分享一下DeepLearning常见的十大深度学习架构,这十个架构中,大家有见过或没见过的,见过的回顾一下,没见过的可以有个初步的认识,再有针对
深度迁移学习(Deep Transfer Learning)是一种在深度学习领域中应用的迁移学习方法,旨在通过利用从一个领域学习到的知识来改善在另一个相关但数据较少的领域上的学习任务。深度迁移学习常常使用预训练的深度神经网络模型,通过迁移已学习到的知识和特征来加快和优化在目标领域上的学习过程。深度迁移学习的优势在于它能够利用源领域丰富的数据和已学习到的知识来改善目标领域上的学习性能。**迁移知识:
域迁移的目标是通过迁移源域中学到的知识和特征,在目标域上实现更好的泛化性能。在目标域中,通常有较少的标记样本可供学习,因此模型需要通过迁移学习来利用源域中学到的知识和特征,以便在目标任务上获得良好的性能表现。通过从源域到目标域的知识迁移,模型可以更好地适应目标域的特征和数据分布,从而提高在目标任务上的效果。因此,我们需要通过迁移学习的方式,将从源域学到的知识和特征应用到目标域上,以提高在目标域上的
算法的特性 :有穷性 :算法的有穷性是指算法必须能在执行有限个步骤之后终止;确切性:算法的每一步骤必须有确切的定义;输入项:一个算法有0个或多个输入,以刻画运算对象的初始情况,所谓0个输入是指算法本身定出了初始条件;输出项:一个算法有一个或多个输出,以反映对输入数据加工后的结果。没有输出的算法是毫无意义的;可行性:算法中执行的任何计算步骤都是可以被分解为基本的可执行的操作步骤,即每个计算...
由于其固有的特性,小目标在多次下采样后的特征表示较弱,甚至在背景中消失。FPN简单的特征拼接在信息传递中引入了不相关的上下文,进一步降低了小物体的检测性能。为了解决上述问题,我们提出了简单但有效的FE-YOLOv5。(1) 我们设计了来捕捉小目标更具辨别力的特征。全局注意力 和 高级全局上下文信息用于指导浅层的高分辨率特征。全局注意力与跨维度特征交互,减少信息丢失。高级上下文通过非局部网络对全局关