




- @weixin_43930865
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
大数据集群运维1:集群扩容均衡1.1:hdfs均衡bash /opt/client/HDFS/hadoop/sbin/start-balancer.sh -threshold 偏差值例如:bash /opt/client/HDFS/hadoop/sbin/start-balancer.sh -threshold 10这个命令中-threshold 参数值是 HDFS 达到平衡状态的磁盘使用率偏差值

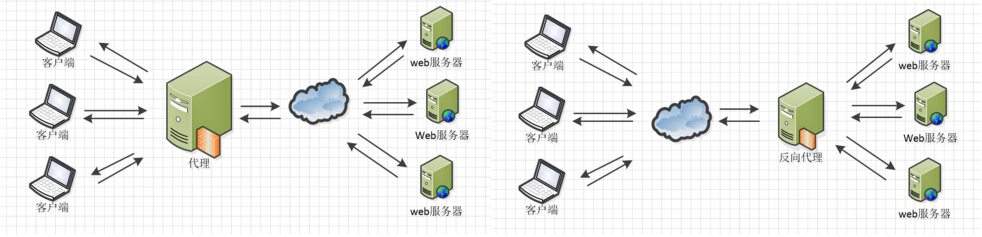
1:安装dockerdocker安装以及使用安装成功后docker verion检查是否安装成功1:启动docker systemctl start docker2:检查docker运行状态systemctl status docker3:利用docker部署nigex2:linux部署nigexNginx相关地址源码:https://trac.nginx.org/nginx/browser官网:
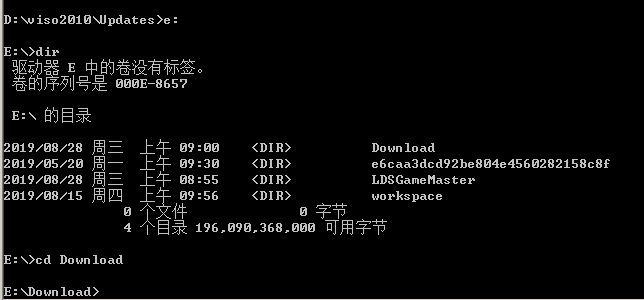
cdm目录切换1:ctrl+r进去cmd2:dir:当前目录文件展示,相当于linux的ll3:目录切换磁盘名。例如:或者f:即可进入目录: cd 路径4:查看ip
大数据集群运维1:集群扩容均衡1.1:hdfs均衡bash /opt/client/HDFS/hadoop/sbin/start-balancer.sh -threshold 偏差值例如:bash /opt/client/HDFS/hadoop/sbin/start-balancer.sh -threshold 10这个命令中-threshold 参数值是 HDFS 达到平衡状态的磁盘使用率偏差值
官网:https://bm.ruankao.org.cn/sign/welcome2004-2020年软考软件设计师考试试题真题解析:链接:https://pan.baidu.com/s/1jvKDSrEKg9Tx3aurJd69OA提取码:2jck考试时间:前半年3月报名5月左右考试,后半年9月报名11月左右程序员进阶路线:初级(程序员)-中级(软件设计师)1:初级:2:中级:中级软件设计师考试

cdm目录切换1:ctrl+r进去cmd2:dir:当前目录文件展示,相当于linux的ll3:目录切换磁盘名。例如:或者f:即可进入目录: cd 路径4:查看ip
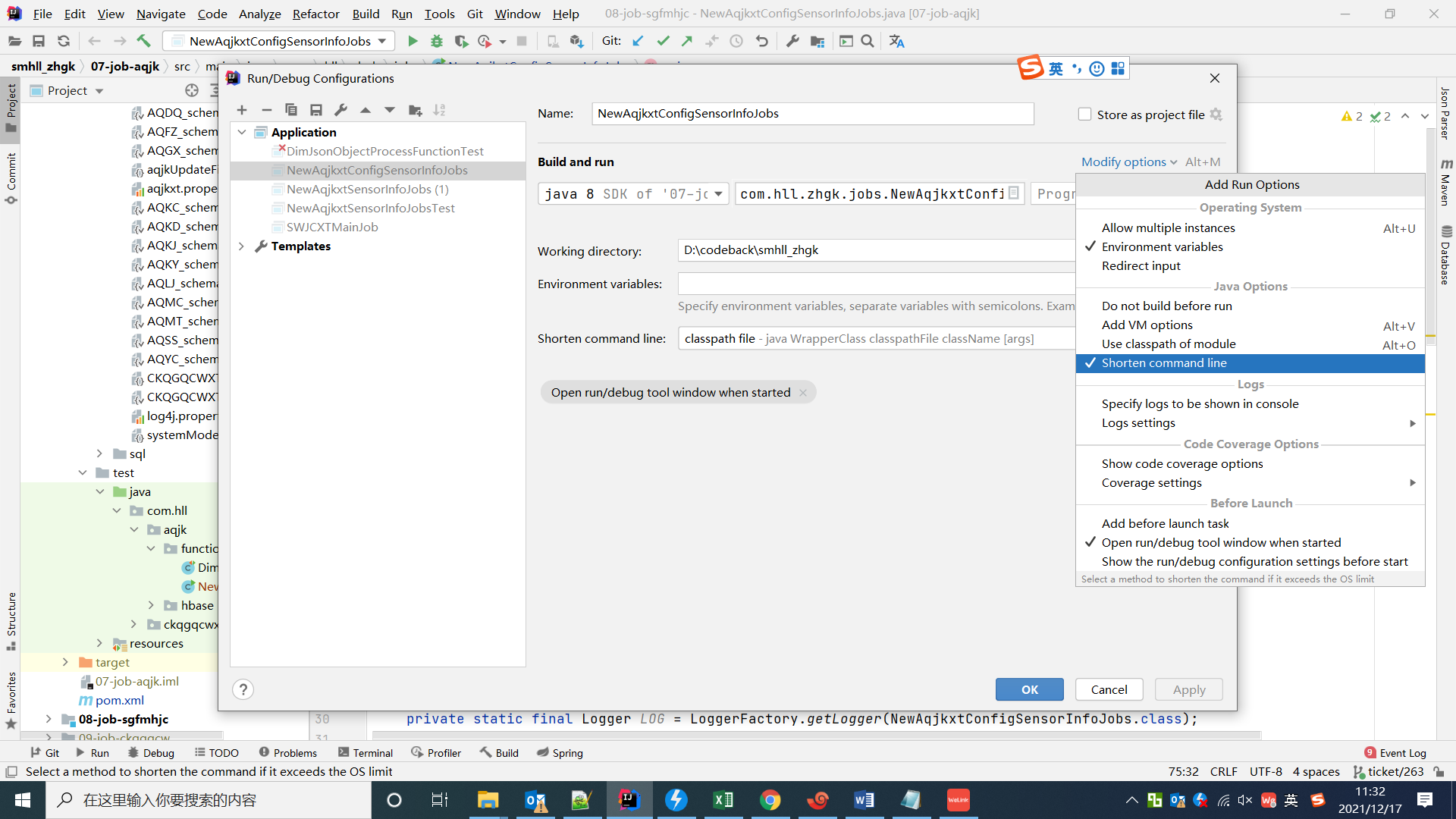
Error running 'JsonSchemaTest.loadSchemaTestFailed':Command line is too long. Shorten command line for。。。。。 also for JUnit default configuration? (a minute ago)命令太长加载时找不到在configuration中选择modify option
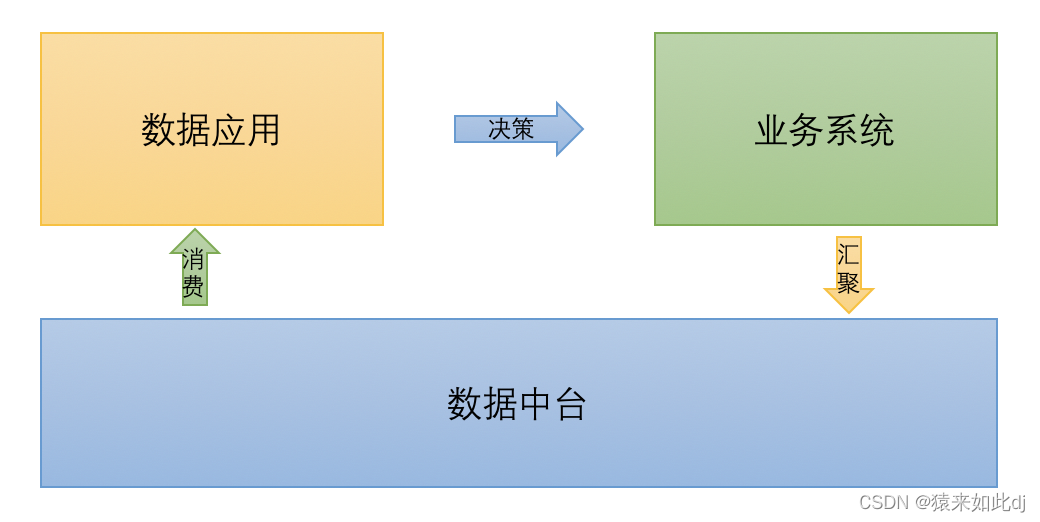
主题:即高层次的互不折叠的数据分类,用于管理其下一级的业务对象数据标准:基于公司或者一具体的业务线制定的需要公司共同遵守的属性层数据含义和业务规则,描述了公司对某个数据的共同理解,这些理解确定后就应该作为标准在企业内被共同遵守。数据仓库-ODS层:存储源数据的简单落地数据仓库-DWI层:又称为数据整合层,DWI层是对多个源系统数据的整合,清洗,基于数据建模三范式建模(个人理解属于从数据治理得来的数
1:安装dockerdocker安装以及使用安装成功后docker verion检查是否安装成功1:启动docker systemctl start docker2:检查docker运行状态systemctl status docker3:利用docker部署nigex2:linux部署nigexNginx相关地址源码:https://trac.nginx.org/nginx/browser官网:
1:分片未分配使用ES的cat API可以分析出未分配的分片信息及未分配的原因:curl -XGET “http://ip:port/_cat/shards?v&h=index,shard,prirep,state,node,unassigned.reason” | grep UNASSIGNED解决1:开启重分配命令:curl -XPUT ‘localhost:9200/_cluster
