




- @weixin_43923463
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
最近在跑深度学习实验,完成之后发现生成了.npy文件,于是上网查找了一下如何打开此文件,记录一下,希望可以帮助到大家。这样在控制台就可以看到文件内容了,并且在文件地址2也可以查看到.txt文件。

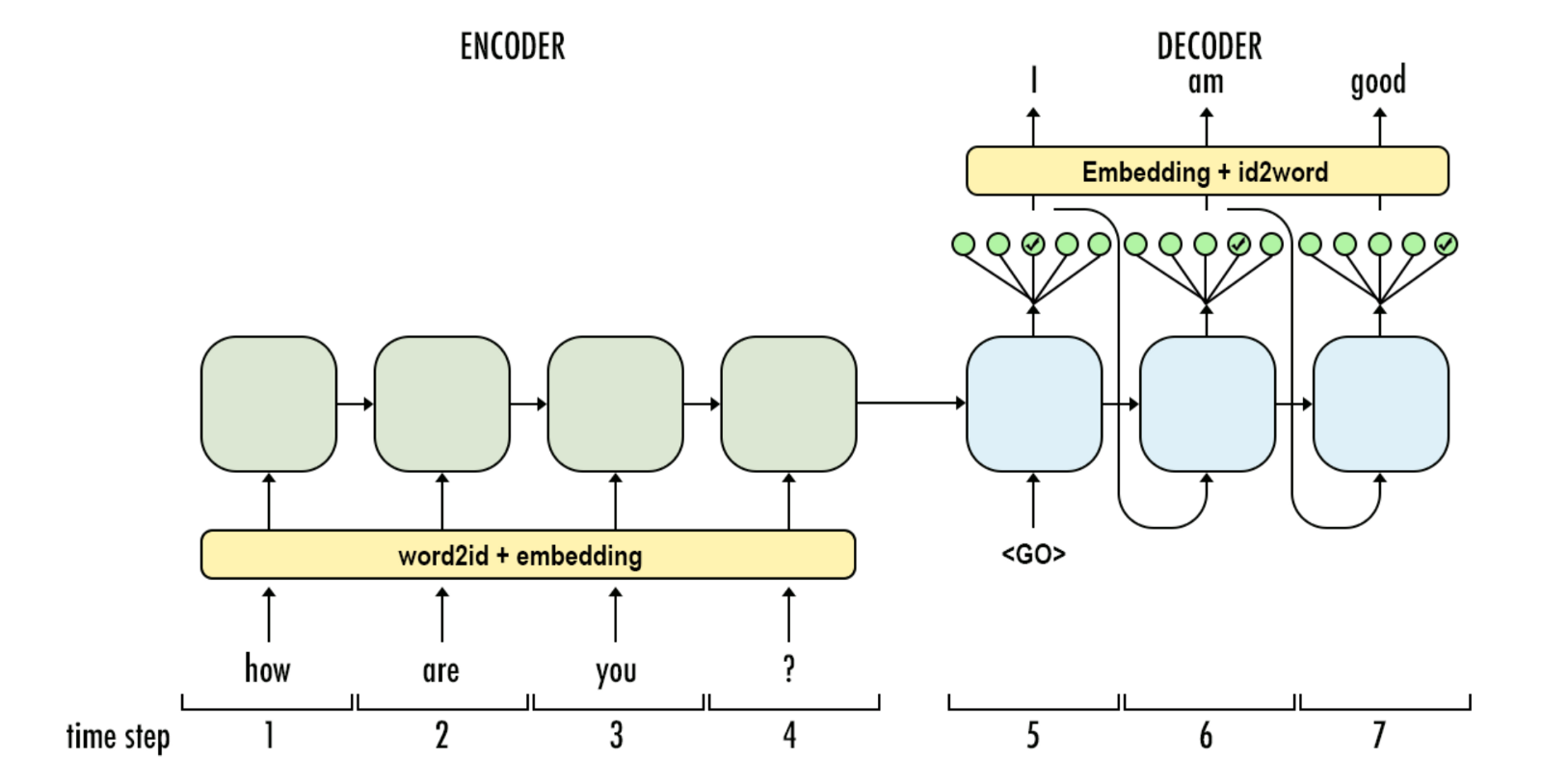
由于数据中存到大量的噪声,可以对其进行基础的处理,然后分别把input和target使用两个文件保存,即input中的第N行为问,target的第N行为答。当前的数据量为500多万条,在GTX1070(8G显存)上训练,大概需要90分一个epoch,耐心的等待吧。的聊天数据非常不好获取,所以从github上使用一些开放的数据集来训练闲聊机器人模型。和之前的操作相同,需要把文本能转化为数字,同时还需
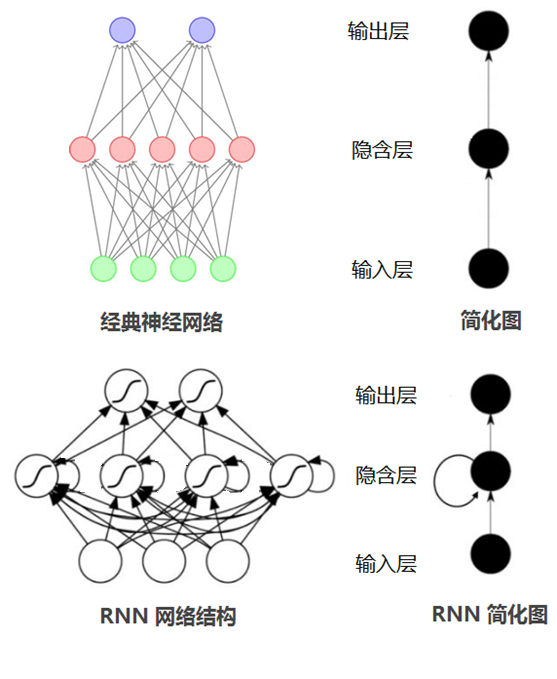
为什么有了神经网络还需要有循环神经网络?在普通的神经网络中,信息的传递是单向的,这种限制虽然使得网络变得更容易学习,但在一定程度上也减弱了神经网络模型的能力。特别是在很多现实任务中,网络的输出不仅和当前时刻的输入相关,也和其过去一段时间的输出相关。此外,普通网络难以处理时序数据,比如视频、语音、文本等,时序数据的长度一般是不固定的,而前馈神经网络要求输入和输出的维数都是固定的,不能任意改变。因此,
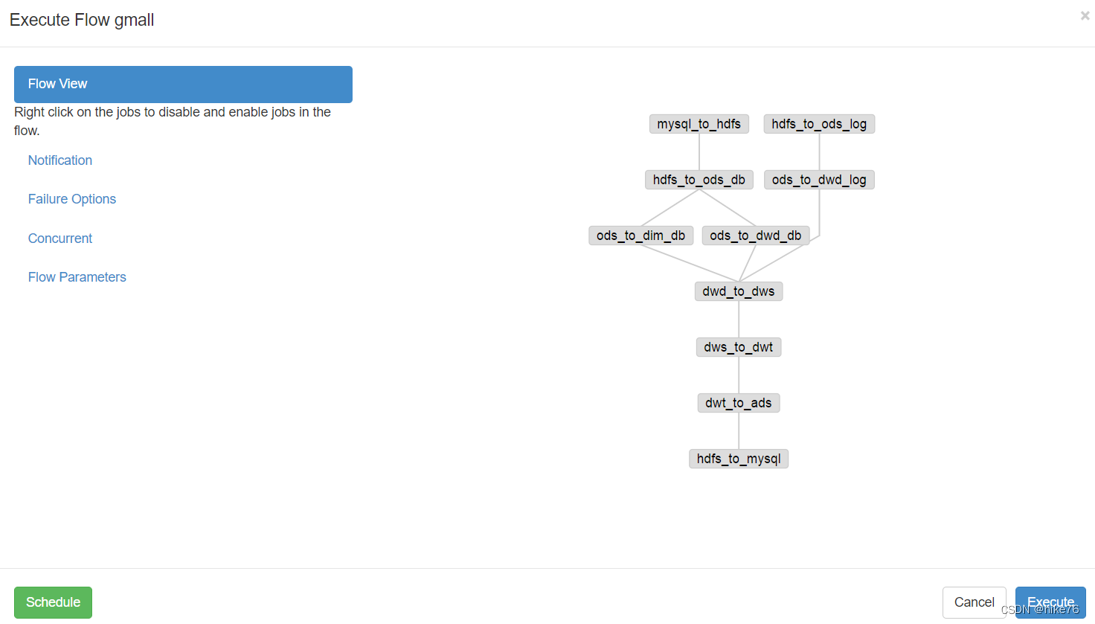
环境准备:centos7.5,hadoop 3.1.3,jdk 1.8.0_161前言:经过半个月的时间,请教了往届的师兄师姐、身边的朋友、公司里面的维修人员、在网上找到的自学运维和阿里P7的两位老大哥,终于把平台在实验室环境下搭建成功。总结下来,实验室的环境不像自己在虚拟机中随意更改,所以这半个月都在修改环境,搭建集群只用不到一个小时的时间。从最初出现问题不知道是什么原因,到后来知道原因着手去修
将首日数据导入(6-14),其他日期的数据不要导入,如果导入,关闭除HDFS的所有集群,删除hdfs上的warehouse,origin_data,将表重新建立一遍。gmall中有75张表。二 Azkaban部署1 上传tar包将azkaban-db-3.84.4.tar.gz,azkaban-exec-server-3.84.4.tar.gz,azkaban-web-server-3.84.4.
最近在跑深度学习实验,完成之后发现生成了.npy文件,于是上网查找了一下如何打开此文件,记录一下,希望可以帮助到大家。这样在控制台就可以看到文件内容了,并且在文件地址2也可以查看到.txt文件。
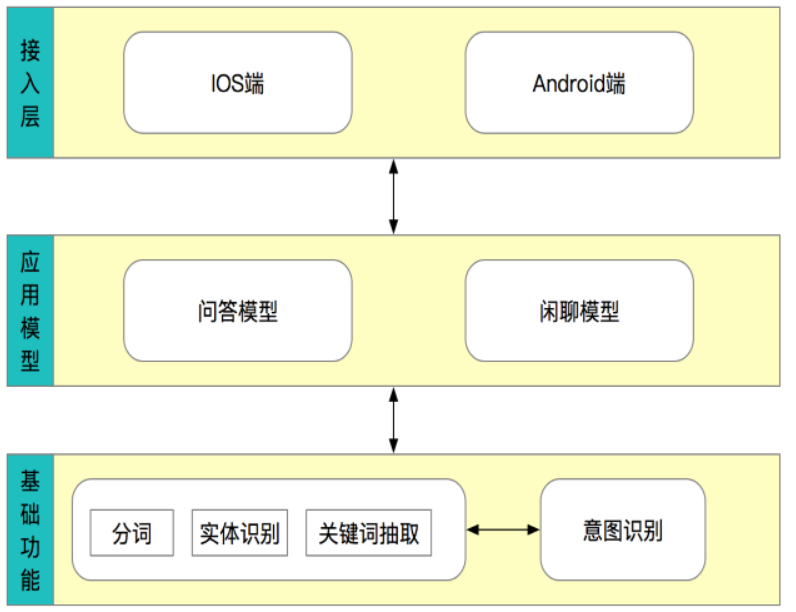
QA BOT(问答机器人):回答问题代表 :智能客服、比如:提问和回答TASK BOT (任务机器人):帮助人们做事情代表:siri比如:设置明天早上9点的闹钟CHAT BOT(聊天机器人):通用、开放聊天代表:微软小冰实现聊天机器人,起到智能客服的效果,能够为使用app的用户解决基础的问题,而不用额外的人力。python是什么,python有什么优势等问题。
在阿里云服务器配置hadoop没有NameNode、ResourceManager、SecondaryNameNode三个节点的解决办法公网IP,私网IP
最近在跑深度学习实验,完成之后发现生成了.npy文件,于是上网查找了一下如何打开此文件,记录一下,希望可以帮助到大家。这样在控制台就可以看到文件内容了,并且在文件地址2也可以查看到.txt文件。
忽略具有cuda计算力为3.0的可见GPU设备。最低要求的Cuda计算力为3.5。