




- @weixin_43322583
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Linux下分布式部署hadoop全流程详细记录附带图文。

在已经安装完hadoop,mysql的基础上可以进行hive的安装之前部署的hadoop版本为3.2.4,mysql版本为8.0.39,详细部署流程。

在hadoop搭建完成的前提下,集成spark,spark on yarn模式运行。

YAML 参考了其他多种语言,包括:C语言、Python、Perl,并从 XML、电子邮件的数据格式(RFC 2822)中获得灵感。命名卷可以用于持久化容器内的数据,即使容器被删除或重新创建,数据也不会丢失。1.命名卷存储在Docker管理的宿主机文件系统中,在Docker主机上创建的独立于容器生命周期的持久化存储区域。YAML 文件使用缩进和换行等符号来表示层次结构和序列关系,从而达到编写简单易

Kafka的介绍,以及使用python创建kafka的topic

linux下安装python的详细过程,以及pip源配置的方式,附图文。

hdfs操作,基础操作,附带配详演示截图。

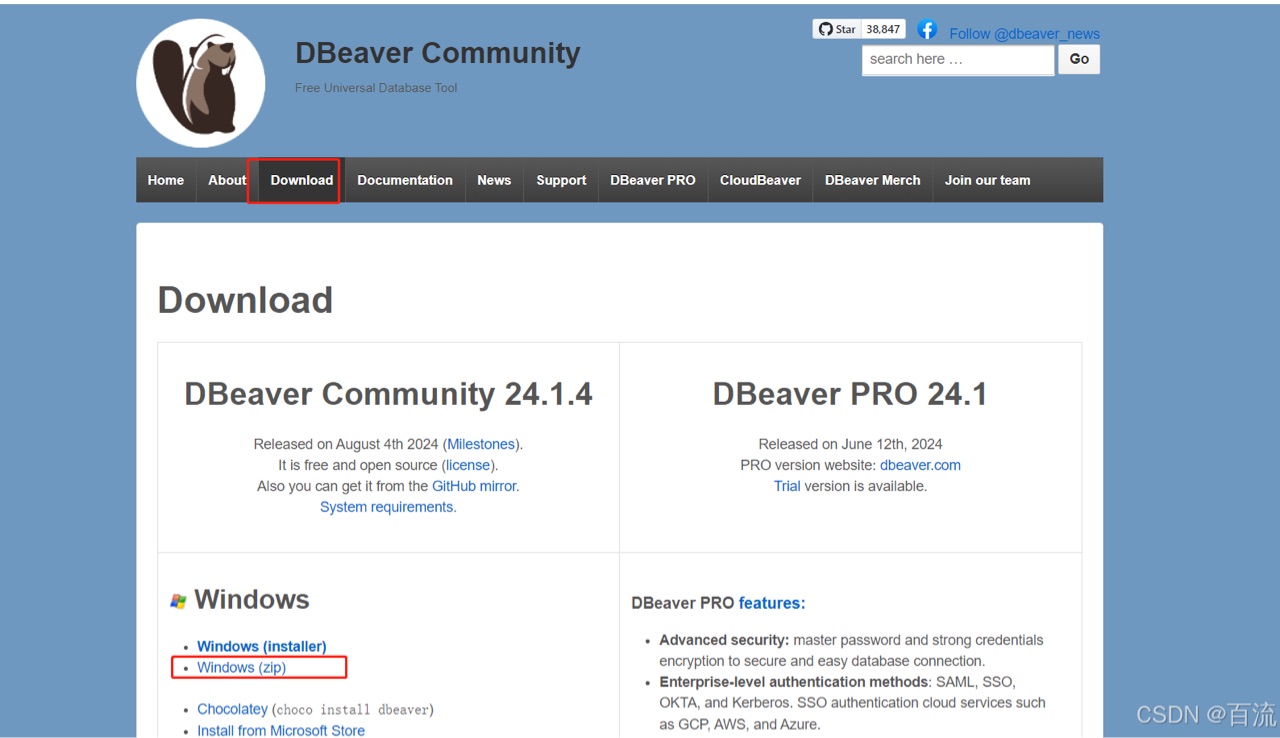
DBeaver是一款免费、开源的数据库管理工具,支持多种关系型数据库,包括MySQL、PostgreSQL、Oracle、SQLite、Microsoft SQL Server,还可以链接hive。它是一款跨平台软件,支持Windows、macOS、Linux等操作系统。DBeaver提供了强大的数据库管理功能,包括数据库连接、SQL编辑器、数据导入导出、数据备份、数据恢复等。同时,它还支持多个数
关键字声明的变量确实是可变的,这意味着你可以在变量的生命周期内多次改变它的值。一旦一个变量被声明,就不能在同一作用域内再次声明它,无论它是。在 Scala 中声明变量和常量不一定要指明数据类型,在没有指明数据类型的情况下,其数据类型是通过变量或常量的初始值推断出来的。所以,如果在没有指明数据类型的情况下声明变量或常量必须要给出其初始值,否则将会报错。变量重新赋值为不同的值,这些值可能会存储在不同的
