- @weixin_42148238
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
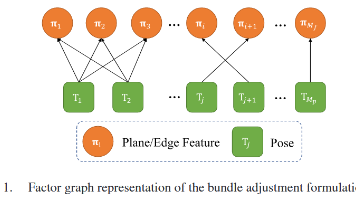
本文提出了一种高效且一致的激光雷达光束平差方法(BALM),通过点簇坐标对原始点进行紧凑表示,直接最小化点到几何特征的自然欧氏距离。关键创新包括:1)采用点簇概念避免枚举原始点,显著降低计算复杂度;2)推导闭式二阶导数,开发高效二阶求解器;3)实现位姿和不确定性的联合估计。实验表明该方法在计算效率和精度上优于现有方法,为激光SLAM系统提供了更优的全局一致性优化方案。
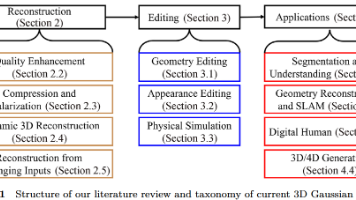
本文综述了三维高斯喷溅(3DGS)技术的最新进展。3DGS通过显式高斯椭球体建模场景,实现了比神经辐射场(NeRF)更高效的训练(约30分钟)和实时渲染(1080p下30FPS)。文章系统梳理了3DGS在三维重建(包括动态场景)、场景编辑(几何/外观/物理模拟)和下游应用(数字人、SLAM、3D生成)等方面的方法创新。重点分析了质量增强、压缩优化、稀疏视图处理等关键技术,并比较了3DGS与网格、S
本文提出SuGaR方法,首次实现从3D高斯泼溅(3DGS)中高效提取可编辑网格。针对3DGS优化后高斯分布无序的问题,作者创新性地引入表面对齐正则化项,使高斯贴合场景表面;随后提出基于泊松重建的快速网格提取算法,仅需单GPU几分钟即可完成,相比传统SDF方法提速显著。实验表明,该方法在保持3DGS高质量渲染优势的同时,支持网格编辑、重光照等图形学操作,为3D场景建模提供了新思路。

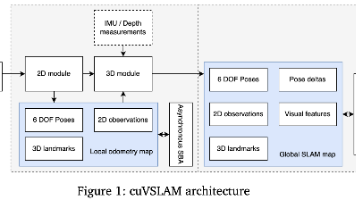
摘要:cuVSLAM是NVIDIA开发的GPU加速视觉SLAM系统,支持单目、双目、RGB-D、视觉惯性及多相机配置。该系统采用前后端分离架构,前端实现低延迟位姿估计,后端负责全局优化。创新性地将多相机系统建模为视场重叠图,自动判断跨相机跟踪关系。通过CUDA加速特征处理、稀疏BA等模块,在Jetson边缘设备上实现实时性能。实验表明,该系统在KITTI等数据集上表现优异,多相机配置显著提升弱纹理
DSO 经典的地方不在于它“第一次做了直接法”,而在于它把直接法系统化、BA 化、工程化了。它证明了一件事:直接法不一定要稠密,也不一定要依赖深度平滑先验。只要点选得好、光度模型足够准确、优化结构设计合理,稀疏直接法也可以做到实时、高精度和高鲁棒性。DSO 对后续工作的影响主要有三点。第一,它让光度误差成为 SLAM 后端中的一类标准残差。后来的很多 VIO、RGB-D、LiDAR-Visual
摘要: 论文《Trick-GS: A Balanced Bag of Tricks for Efficient Gaussian Splatting》提出了一种高效优化3D高斯泼溅(3DGS)的方法,通过组合多种已验证策略,在模型压缩、训练速度和渲染效率之间取得平衡。Trick-GS采用渐进式训练(分辨率、模糊、尺度)、基于体积和显著性的高斯剪枝、球谐函数(SH)掩码等技术,显著降低了模型存储(最

《iG-LIO:基于增量GICP的激光-惯性紧耦合里程计》提出了一种高效稳健的LiDAR-惯性里程计系统。该研究通过三个关键技术改进现有方法:1) 将GICP配准约束与IMU测量通过最大后验估计紧耦合;2) 设计体素化表面协方差估计器(VSCE)实现O(1)复杂度查询;3) 采用增量体素地图实现动态环境建模。实验表明,iG-LIO在NCLT等6个数据集上保持相同参数时,比Faster-LIO快1.
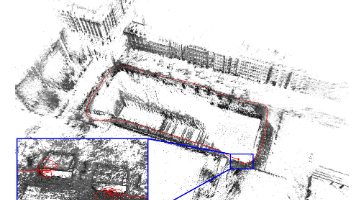
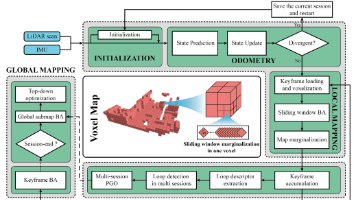
Voxel-SLAM是一种基于激光雷达和IMU的完整SLAM系统,具有以下创新点:1) 采用统一的自适应体素地图表示,覆盖初始化、里程计、局部建图、闭环和全局建图全过程;2) 提出鲁棒的初始化方法,可在动态初始状态下工作;3) 利用短期、中期、长期和多地图四种数据关联,实现高精度定位与建图;4) 引入高效的局部光束平差和全局层次优化方法。系统在室内、户外和城市等多种场景的30个数据序列上验证了其优
本文介绍了一个开源项目"awesome-3DGS-SLAM-and-Datasets",旨在解决3D高斯泼溅(3DGS)SLAM领域文献快速增长带来的管理难题。该项目采用结构化YAML文件存储论文和数据集信息,通过自动化脚本生成README和交互式网页,支持按多种条件检索文献。核心功能包括:论文分类展示、数据集归纳、代码链接收集、本地实验记录、自动查重等。项目采用公开与私有数据

LaTeX是一款高效的排版工具,搭配VSCode可提升写作效率。安装时注意:Windows中文用户名需改为英文,避免报错。VSCode配置需禁用自动编译功能,防止频繁生成中间文件占用磁盘。推荐学习资源包括知乎和CSDN上的LaTeX入门指南,以及Overleaf的文档定位技巧。使用中需定期清理VSCode缓存路径(如WebStorage文件夹)以释放空间。注意图片浮动选项避免"H&quo