- @u012856866
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
fairseq 是 Facebook AI Research Sequence-to-Sequence Toolkit 的缩写,是一款开源的神经机器翻译框架。它基于PyTorch开发,用于训练和评估各种序列到序列(seq2seq)模型,广泛应用于自然语言处理(NLP)任务,如机器翻译、文本生成、语音识别等。它支持多种模型架构,包括但不限于 Transformer、LSTM 和 Convolutio
文章目录1. Ubuntu下安装django2. 新建django项目2.1 通过shell终端新建项目2.2 通过pycharm新建项目3. 启动项目3.1 shell终端模式3.2 pycharm模式1. Ubuntu下安装django打开Shell终端, 用如下命令安装djangosudo apt-get install django查看django安装的版本python -m django
Back-off restarting failed container的Warning事件,一般是由于通过指定的镜像启动容器后,容器内部没有常驻进程,导致容器启动成功后即退出,从而进行了持续的重启。**解决方法:**找到对应的deployment,加上如下语句: command: [“/bin/bash”, “-ce”, “tail -f /dev/null”]pod启动后一直重启,并报Back
【莫烦Python】Reinforcement Learning:https://mofanpy.com/tutorials/machine-learning/reinforcement-learning/简介1.1 什么是强化学习1.2 强化学习方法汇总1.3 为什么用强化学习 Why?1.4 课程要求Q-learning2.1 什么是 Q Leaning2.2 小例子2.3 Q-learnin
Streamlit是一个用于机器学习、数据可视化的 Python 框架。基于Streamlit我们可以快速部署自己的机器学习应用,或者构建机器学习数据分析的web可视化界面。
大模型训练框架 DeepSpeed 详解DeepSpeed 是一个由微软研究院开发的深度学习优化库,它主要针对大规模分布式训练进行了优化,尤其是在使用大量 GPU 进行训练时可以显著提高效率。DeepSpeed 旨在降低模型并行和数据并行的通信开销,同时提供了一系列工具来帮助研究人员和开发者更容易地训练大型模型。:这是一种减少内存使用的优化器,通过将模型状态分布在多个 GPU 上来减少内存占用。混
【代码】【大模型】Qwen, DeepSeek, GLM的API接口调用(官方示例+LangChain示例)
PostgreSQL是一种功能强大的开源关系数据库管理系统,广泛应用于各种应用程序中。PostgresStore 提供持久化存储功能,支持层次命名空间和可选的向量搜索(通过 pgvector 扩展),适合需要长时记忆的 AI 应用,如聊天机器人或自动化工作流。下面介绍如何以形式启动PostgreSQL服务。注意: 这里,如果安装的是新版本的 ,后续命令为(没有中间的横线-)运行下面命令启动Post
1. RNN神经网络模型原理2. RNN神经网络模型的不同结构3. RNN神经网络-LSTM模型结构
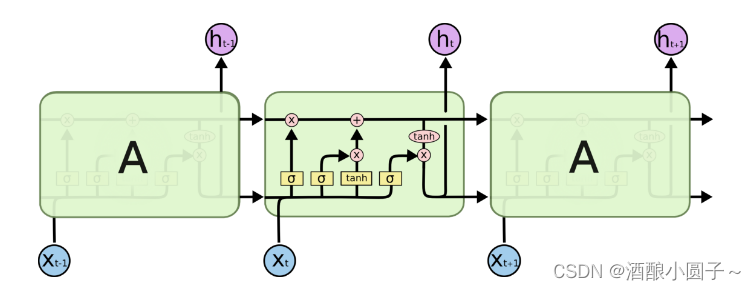
软件定义网络(Software-defined Networking,简称SDN)技术是一种网络管理方法,它,提高了网络性能和管理效率,使网络服务能够像云计算一样提供灵活的定制能力。SDN将网络设备的与解耦,通过。