




- @threestooegs
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
图完全图:任意两个点都有一条边相连,无向完全图有n(n-1)/2条边,有向完全图n(n-1)条边。顶点的度在有向图中,顶点的度等于该顶点的入度与出度之和。当有向图中仅有一个顶点的入度为0,其余顶点的入度均为1是一颗有向树。连通图(强连通图)无向图中,若任何两个顶点u、v都存在从u到v的路径,则称为连通图。有向图中,若任何两个顶点u、v都存在从u到v的路径,则称为强连通图。无向图的极大连通子图成为G
目标检测中常见的loss函数
nps支持多平台的客户端配置,访问https://github.com/ehang-io/nps/releases/tag/v0.26.10地址可以下载不同平台的客户端,配置都是相同的,需要注意的是在windows平台下会被认为是病毒软件,需要将nps.exe添加到杀毒软件的信任区,否则不可用。以上配置完成就可以在任意主机访问内网的服务了,整个流程来讲还是比较简单的,有需要的可以自己玩一下,通过n
把PS中H的值除以2,S乘255,V乘255,可以得到对应的opencv的HSV值。S:saturation饱和度(0~100),形容颜色的深浅,如浅红、大红、深红。opencv中的HSV范围,H是0-180,S是0-255,V是0-255。PS中的HSV范围,H是0-360,S是0-1,V(B)是0-1。V:value色调(0~100),色彩的亮度。H:hue 色相(0~360),红绿蓝。但是H
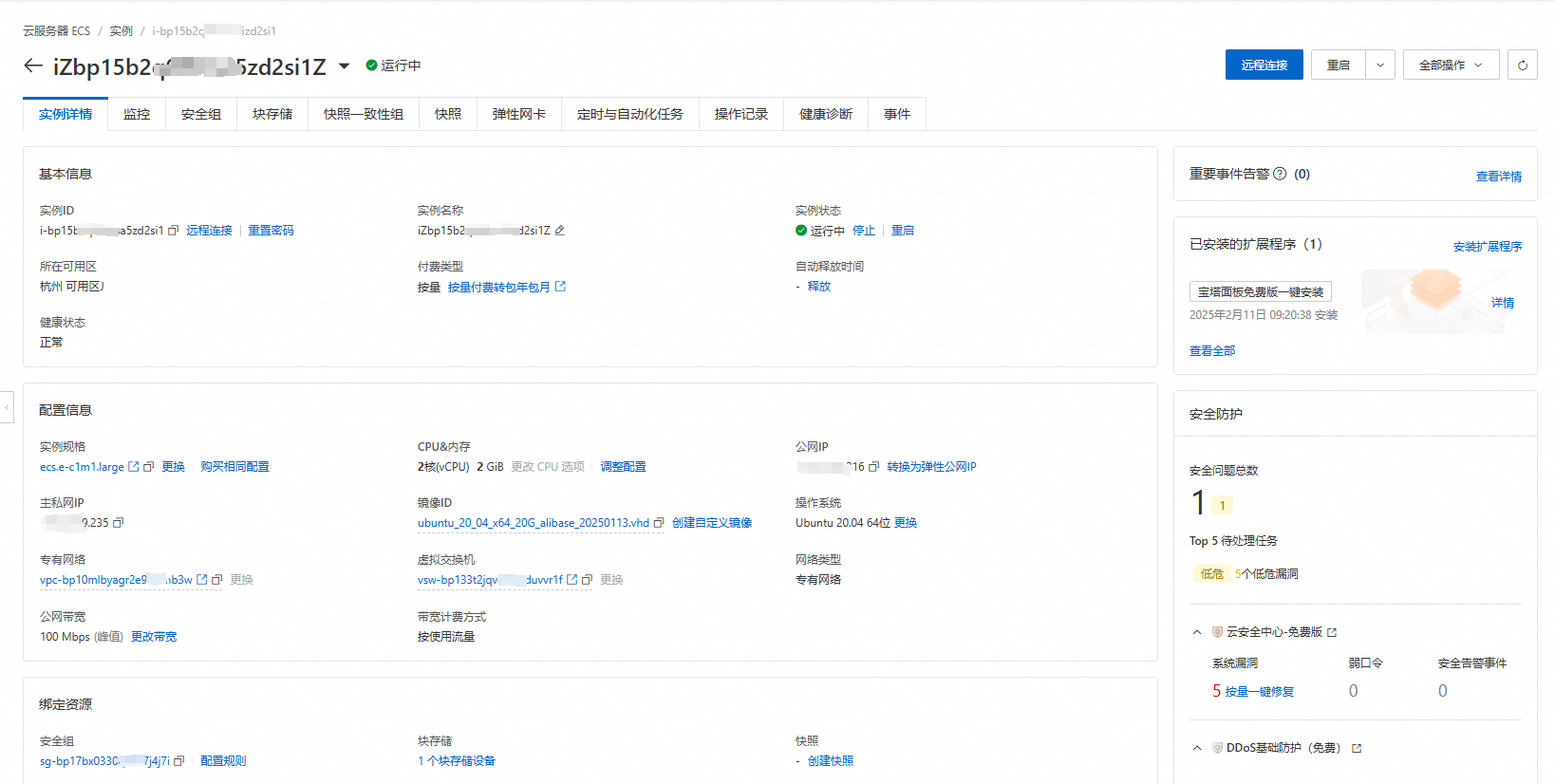
deepseek-r1:1.5b这个模型确实很轻量资源占用很少,应该也就占用1GB多点显存,但是也确实比较呆,很多问题都回答不上来,这里如果想要运行其他模型,可以参考ollama的技术文档https://ollama.readthedocs.io/quickstart/ 里面说明了其他模型运行的方式以及所需要的资源。下载完成后安装ollama,默认安装在c盘下面,这个通过默认安装方式无法更改模型就
最近在做paddleocr部署时,在新的机器上部署环境时安装lanms-neo时安装失败,分析了一下error日志,大概是在编译过程中MSVC版本的问题。重新安装了visual stdio 2019后,在进行安装lanms-neo安装成功。
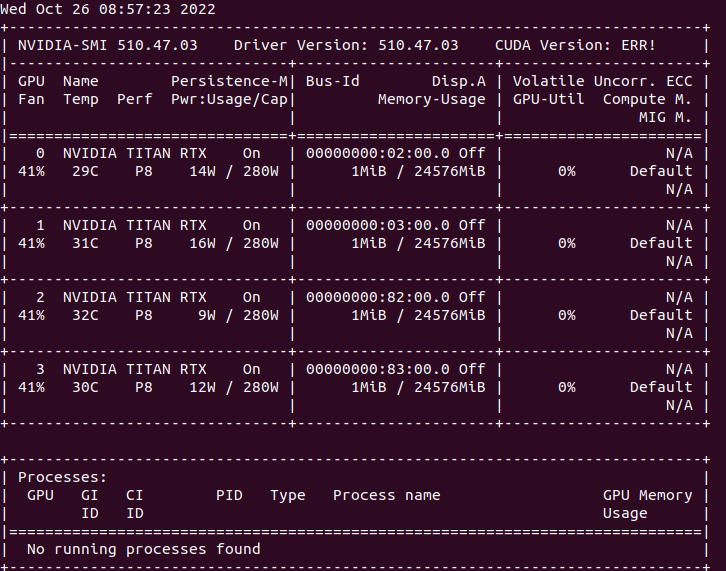
查找了相关的解决方案,大多数说是CUDA、cuDNN、显卡驱动版本不匹配问题,但是我的这套版本用了很长时间了,没有出现过这个问题,然后对问题进行了排查,怀疑是CUDA的动态连接库问题,查看了CUDA/lib目录下的动态链接库文件,果然多了两个文件,nvidia-smi查看显卡驱动后发现,CUDAversion:ERR!把这两个文件删除后,nvidia-smi后显示正常。
deepseek-r1:1.5b这个模型确实很轻量资源占用很少,应该也就占用1GB多点显存,但是也确实比较呆,很多问题都回答不上来,这里如果想要运行其他模型,可以参考ollama的技术文档https://ollama.readthedocs.io/quickstart/ 里面说明了其他模型运行的方式以及所需要的资源。下载完成后安装ollama,默认安装在c盘下面,这个通过默认安装方式无法更改模型就
查找torch与torchvision对应版本github链接:https://github.com/pytorch/vision#installation在线下载或者离线下载1、在线下载在pytorch官网选择相应的历史版本,使用conda或者pip安装,使用官网的镜像下载很慢,建议使用其他的镜像源,这里我使用的是阿里的镜像速度还不错。pip install torch==1.7.1 torch
在虚拟环境pytho3.6、cuda10.2中使用pip安装tensorflow-gpu==1.14运行报错,ImportError: libcublas.so.10.0: cannot open shared object file: No such file or directory,查找了相关资料说是tensorflow和cuda版本不匹配问题,但是我已经安装了cuda10.2重新安装比较麻