




- @text2204
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
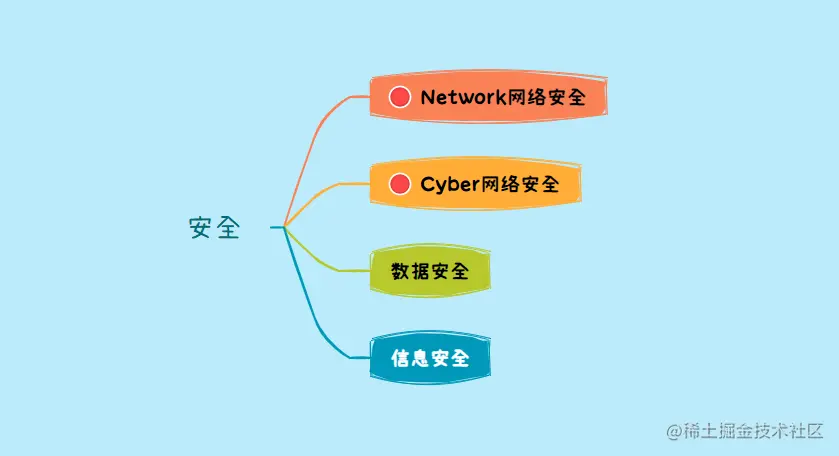
网络安全自学路线
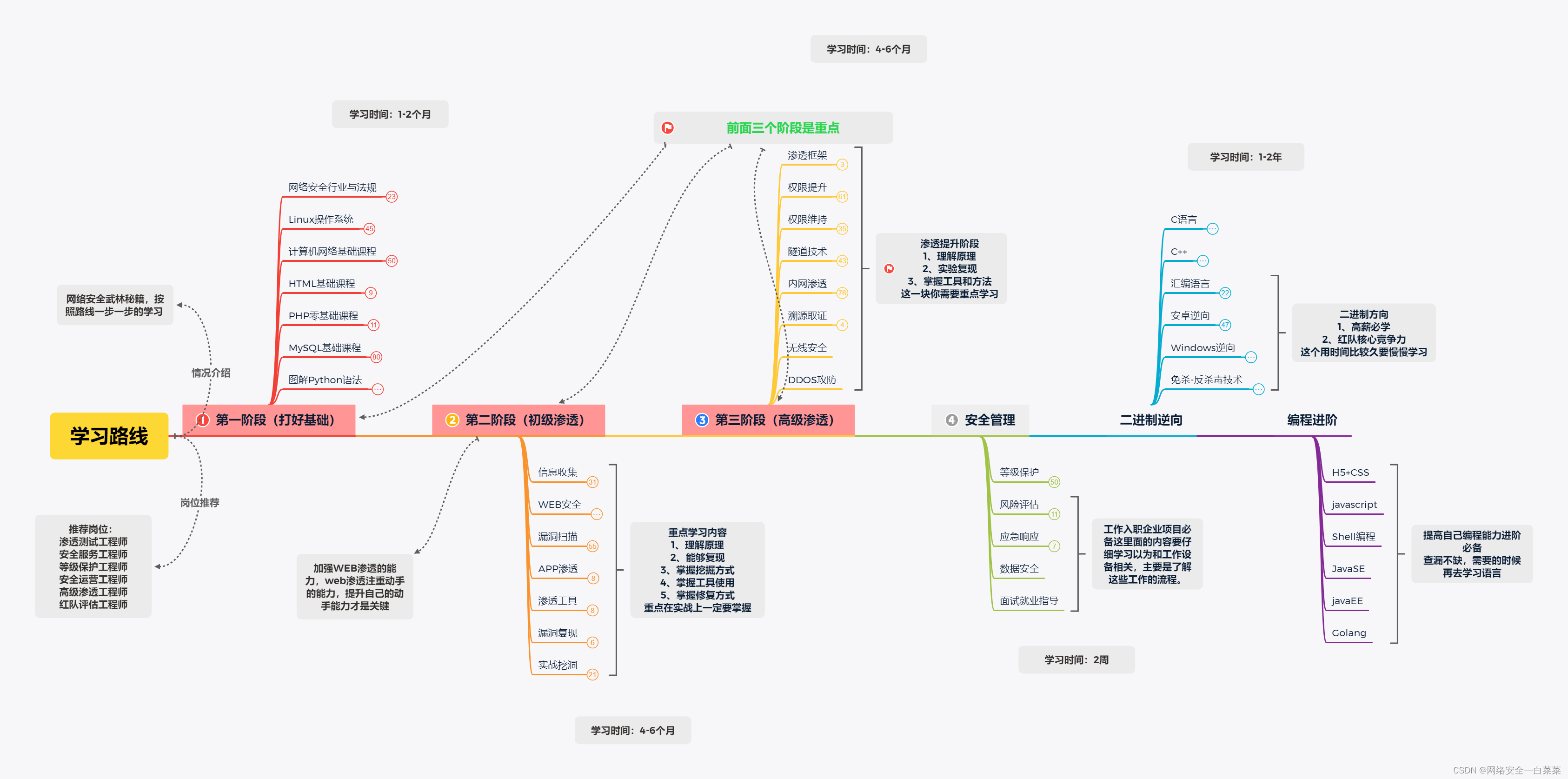
然而,对于企业来说,如何让这些模型了解并遵循内部的代码规范、使用自定义组件和公共库,仍然是一个挑战。AI大模型应用所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。未来的工作可以集中在进一

Ollama 默认直接支持很多模型,只需要简单的使用 命令,示例如下:就可安装、启动、使用对应模型。通过这样方式直接支持的模型我们可以通过https://ollama.com/library 找到。在https://huggingface.co/models上有数万的模型,Ollama 默认支持的不可能全部覆盖,那如何支持其它模型呢?这里我们选择个:无内容审核的大模型:CausalLM-14B(h

常用集成声明式 AI 服务。
通过搭建GraphRAG本地demo后,笔者通过少量的文本内容(三国演义第一章),初略对比了一下传统RAG方案与GraphRAG方案,基于少量文本内容而言,GraphRAG的效果还是符合其宣传内容的,后续更严谨的测试还是需要海量数据的进行验证。希望本文能帮助到对GraphRAG有兴趣的朋友,毕竟读万卷书不如行万里路,看再多的理论介绍,不如自己亲自去动手验证一把来的实在~如果你对AI大模型应用感兴趣
LlamaIndex 和 LangChain 都是优秀的 LLM 开发框架,它们各有优势,适用于不同的使用场景。如果你需要构建一个以数据为中心的应用,并且希望使用一个简单易用的框架,那么 LlamaIndex 是一个不错的选择。如果你需要构建一个复杂的 LLM 工作流程,并且需要高度的灵活性和更广泛的 LLM 支持,那么 LangChain 是一个更好的选择.当然,更灵活多变的用法可将两者结合起来

通过搭建GraphRAG本地demo后,笔者通过少量的文本内容(三国演义第一章),初略对比了一下传统RAG方案与GraphRAG方案,基于少量文本内容而言,GraphRAG的效果还是符合其宣传内容的,后续更严谨的测试还是需要海量数据的进行验证。希望本文能帮助到对GraphRAG有兴趣的朋友,毕竟读万卷书不如行万里路,看再多的理论介绍,不如自己亲自去动手验证一把来的实在~如果你对AI大模型应用感兴趣
虽然对于大多数人来讲,由于我们的电脑配置等原因,部署本地大模型并且达到很好的效果是很奢侈的一件事情。但是这并不妨碍我们对其中的流程和原理进行详细的了解如果你对AI大模型应用感兴趣,这套大模型学习资料一定对你有用。

然而,对于企业来说,如何让这些模型了解并遵循内部的代码规范、使用自定义组件和公共库,仍然是一个挑战。AI大模型应用所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。未来的工作可以集中在进一