




- @sgyuanshi
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在推荐系统中,向量的最邻近检索是极为关键的一步,特别是在召回流程中。一般常用的如Annoy、faiss都可以满足大部分的需求,今天再来介绍另外一个:MilvusMilvusMilvus不同于Annoy、faiss这类型的向量检索工具,它更是一款开源向量数据库,赋能 AI 应用和向量相似度搜索。涉及的术语Filed:类似表字段,可以是结构化数据,当然还可以是向量;Entity:一组Filed,类似表

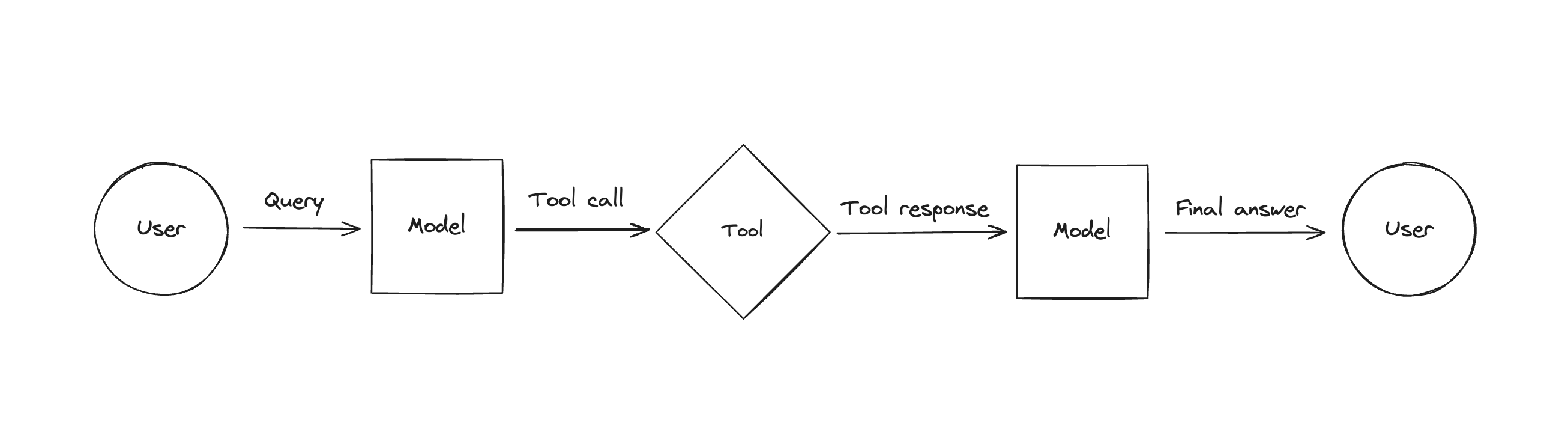
1. 这篇文章我们介绍了Agent这个热门的概念,以及它是如何依托LLM的function call来实现的2. 接着,再展示了借助LangChain的封装来简化这个开发过程,3. 并且还介绍了另外一种不依赖function call的Agent实现。
hadoop集群搭建教程:Hadoop集群搭建教程(一)Hadoop集群搭建教程(二)Spark集群官网下载:spark官网这里要注意spark兼容的hadoop版本接着解压:tar -zxvf spark-2.4.3-bin-hadoop2.7.tgz先在你的master节点进行spark的安装和配置,然后直接拷贝到其他节点就可以了。cd /usr/loca/spark/co...
在推荐系统中,向量的最邻近检索是极为关键的一步,特别是在召回流程中。一般常用的如Annoy、faiss都可以满足大部分的需求,今天再来介绍另外一个:MilvusMilvusMilvus不同于Annoy、faiss这类型的向量检索工具,它更是一款开源向量数据库,赋能 AI 应用和向量相似度搜索。涉及的术语Filed:类似表字段,可以是结构化数据,当然还可以是向量;Entity:一组Filed,类似表
核密度估计属于非参数估计,它主要解决的问题就是在对总体样本的分布未知的情况,如何估计样本的概率分布。像平时,我们经常也会用直方图来展示样本数据的分布情况,如下图:但是,直方图有着明显的缺点:非常不平滑,邻近的数据无法体现它们的差别;不同的bins画出的直方图差别非常大;无法计算概率密度值。核密度估计核密度估计就可以很好的解决直方图存在的问题,它的原理其实也很简单:当你需要估计一...
1. 这篇文章我们介绍了Agent这个热门的概念,以及它是如何依托LLM的function call来实现的2. 接着,再展示了借助LangChain的封装来简化这个开发过程,3. 并且还介绍了另外一种不依赖function call的Agent实现。
如标题所见,这篇博客的主题就是基于Seq2Seq模型的机器翻译,它的主要任务就是将一种语言翻译为另一种语言,在这里我们以英语翻译成法语为例子,如I'm a student.---->>>Je suis étudiant.这份数据是公开,可以直接下载的,下载地址为:翻译语料下载地址模型结构首先,我们先了解一下模型的结构:首先,第一部分是编码器Encoder,它接收source se
参考《Distilling the Knowledge in a Neural Network》Hinton等蒸馏的作用首先,什么是蒸馏,可以做什么?正常来说,越复杂的深度学习网络,例如大名鼎鼎的BERT,其拟合效果越好,但伴随着推理(预测)速度越慢。此时,模型蒸馏酒派上用场了,其目的就是为了在尽量减少模型精度的损失的前提下,大大的提升模型的推理速度。实现方法其实,模型蒸馏的思想很简单。第一步,训
TensorFlow Serving简单来说就是一个适合在生产环境中对tensorflow深度学习模型进行部署,然后可以非常方便地通过restful形式的接口进行访问。除此之外,它拥有许多有点:支持配置文件的定期轮询更新(periodically poll for updated),无需重新启动;优秀的模型版本控制;支持并发;支持批处理;基于docker,部署简单。(这些优点我们在下面会逐一提到)
TensorFlow Serving简单来说就是一个适合在生产环境中对tensorflow深度学习模型进行部署,然后可以非常方便地通过restful形式的接口进行访问。除此之外,它拥有许多有点:支持配置文件的定期轮询更新(periodically poll for updated),无需重新启动;优秀的模型版本控制;支持并发;支持批处理;基于docker,部署简单。(这些优点我们在下面会逐一提到)