- @sensen_kiss
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
聚类是一种将相似数据对象分组的数据分析方法,旨在发现数据中的自然模式和内在结构。聚类问题涉及定义距离度量(如欧几里得距离、余弦距离等)来衡量对象间的相似性,并处理高维数据面临的"维度诅咒"挑战。主要应用包括星系分类、音乐推荐和文档主题分析等。聚类方法分为层次聚类(自底向上或自顶向下)和点分配聚类,其中凝聚型层次聚类通过反复合并最近聚类来构建层次结构,在非欧几里得空间则使用&qu

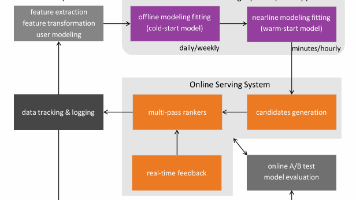
数据科学从经验观察发展为理论分析与计算建模的跨学科领域。现代数据挖掘通过特征提取、模型训练和在线服务等流程,将海量异构数据转化为商业与科研价值。以Hubway骑行数据和社交网络推荐系统为例,展示了数据整合、特征工程和相似性分析等核心技术。面对数据缺失问题,可采用协同过滤、聚类或预测模型进行补全。数据可视化不仅辅助探索性分析,还能验证假设并指导决策。这一流程涵盖数据收集、清洗、建模到应用的全周期,需
前面已经分享过了关于CPT205的CW1的2D作业,这次CW2要求的是3D作业,但是主题不限,不像上次规定了必须得是生日贺卡。这里将以这个大作业为例,讲解OpenGL的3D实践。首先虽然我们来到了3D作业,但我们能靠OpenGL做一个类似于我们现在所处的世界一样的作业吗?答案当然是不能。虽然现在的游戏或者说计算机图形学已经可以让我们能做出接近现实世界的虚拟世界,但是那需要非常细致的建模和设计。很明

文章摘要:本文探讨了原型设计的保真度评估及其五个关键维度:视觉、交互、广度、深度和内容。文章指出原型保真度没有绝对标准,设计师需根据项目需求权衡各维度投入。低保真原型适合快速迭代,高保真原型则接近最终产品体验。文中强调使用精确语言描述保真度的重要性,以避免误解和资源浪费。此外,文章还介绍了物理设计要素,包括菜单、图标、屏幕和信息显示的设计考量。建议采用模块化方法进行原型设计,避免同时处理所有维度带

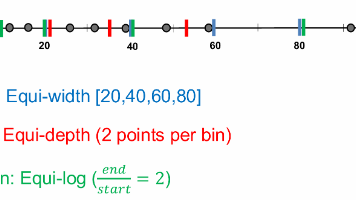
数据是由多个数据对象及其属性组成的集合,属性可分为数值型(离散/连续)和分类型(名义/有序)。关系型数据存储在固定模式的表中,而数值数据可表示为多维空间中的点。向量数据库存储机器学习生成的嵌入向量。混合数据包含数值和分类属性,可通过独热编码或分箱处理。分箱方法包括等宽、等深、等对数和优化分箱,适用于不同数据分布。这些概念是数据分析和机器学习的基础。
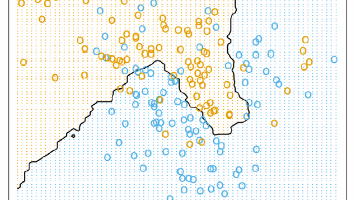
本文介绍了机器学习相关课程及基本概念。课程涵盖监督学习(KNN、决策树、SVM等)、无监督学习(K-means、混合 portfolios)和强化学习三大类。机器学习被定义为通过经验提高任务表现的计算程序,适用于图像识别等传统编程难以解决的问题。与统计学相比,机器学习更注重预测性能和可扩展性;与AI的关系上,机器学习是基于数据学习的系统,不同于符号推理等非学习型AI。文章还梳理了机器学习与人类学习
界面隐喻通过模拟现实世界的物体或活动(如桌面、购物车等)帮助用户理解数字系统功能,降低学习门槛但可能限制设计创新。交互类型包括指令式(如输入命令)、对话式(如语音助手)、操作式(如拖放文件)等,各具特点:指令式高效直接,对话式自然但易误解,操作式直观但需精准设计。设计需权衡隐喻的认知优势与局限,同时选择最适合任务场景的交互方式。
本课叫Human-Centric Computing(以人为中心的计算),而非传统的人机交互(HCI,Human-Computer Interaction),HCI 是一门研究人与计算机之间交互方式的学科,主要关注如何设计、评估和改进用户与计算机系统的交互体验。而本课的要求较低一些,是一种更广泛的跨学科领域,强调将人类的需求、能力和体验作为技术设计的核心。

本文介绍了集成学习方法Bagging和Boosting的原理与应用。Bagging通过有放回采样生成多个训练集,训练多个模型后取平均预测值,主要降低模型方差而不改变偏差,适用于决策树等模型。Boosting则顺序训练分类器,每次重点关注前一轮分类错误的样本,通过加权训练集逐步降低模型偏差(如AdaBoost)。随机森林作为Bagging的改进,通过特征随机选择降低模型间相关性。分析表明,Baggi
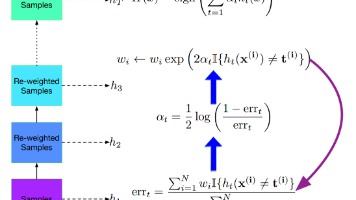
本文介绍了神经网络的基本原理和运算过程。首先阐述了从线性模型到多层神经网络的演化,重点讨论了Sigmoid、tanh、ReLU等多种激活函数的特点及其数学表达式。随后详细解析了神经网络的三大组成部分(输入层、隐藏层、输出层)和全连接架构。通过Python代码示例展示了前向传播的计算流程,包括权重矩阵运算和激活函数应用。文章深入讲解了损失函数(SVM损失和正则化项)的计算方法,并通过具体数值示例演示