




- @qq_63981678
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
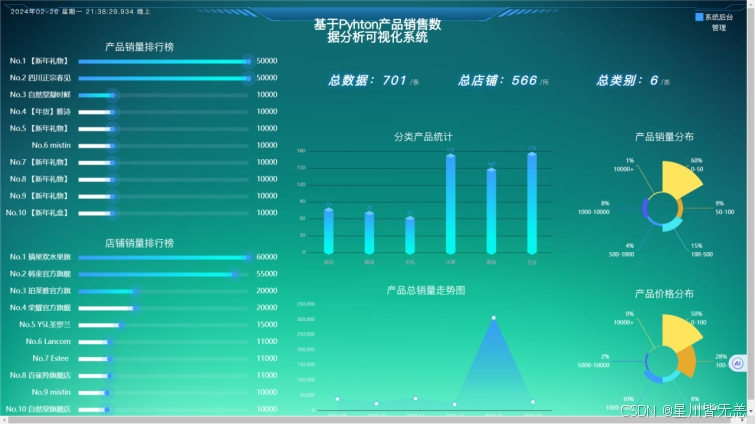
结合现代数据技术,提升企业产品销售管理的智能化与数字化水平。该系统主要包括数据管理和后台管理两个核心模块,其中数据管理部分涵盖数据爬取、数据存储、数据分析、数据可视化以及基于多元线性回归的销量预测五大功能模块。在数据爬取方面,本平台使用Selenium爬虫技术,从相关网站获取销售数据,并借助Pandas进行数据清洗,最后将清洗后的数据存入MySQL数据库。
本文介绍了一个基于Python的智慧旅游数据分析与推荐系统,该系统整合了机器学习TF-IDF算法、Requests爬虫、Echarts可视化、SnowNLP情感分析和Flask框架等技术。系统通过爬取景区数据,进行热度分析、客流量统计、情感评价和路线推荐,并以热力图、折线图等形式可视化呈现。重点阐述了TF-IDF算法的数学原理及其在关键词提取中的应用,展示了通过SnowNLP实现文本清洗、分词和情
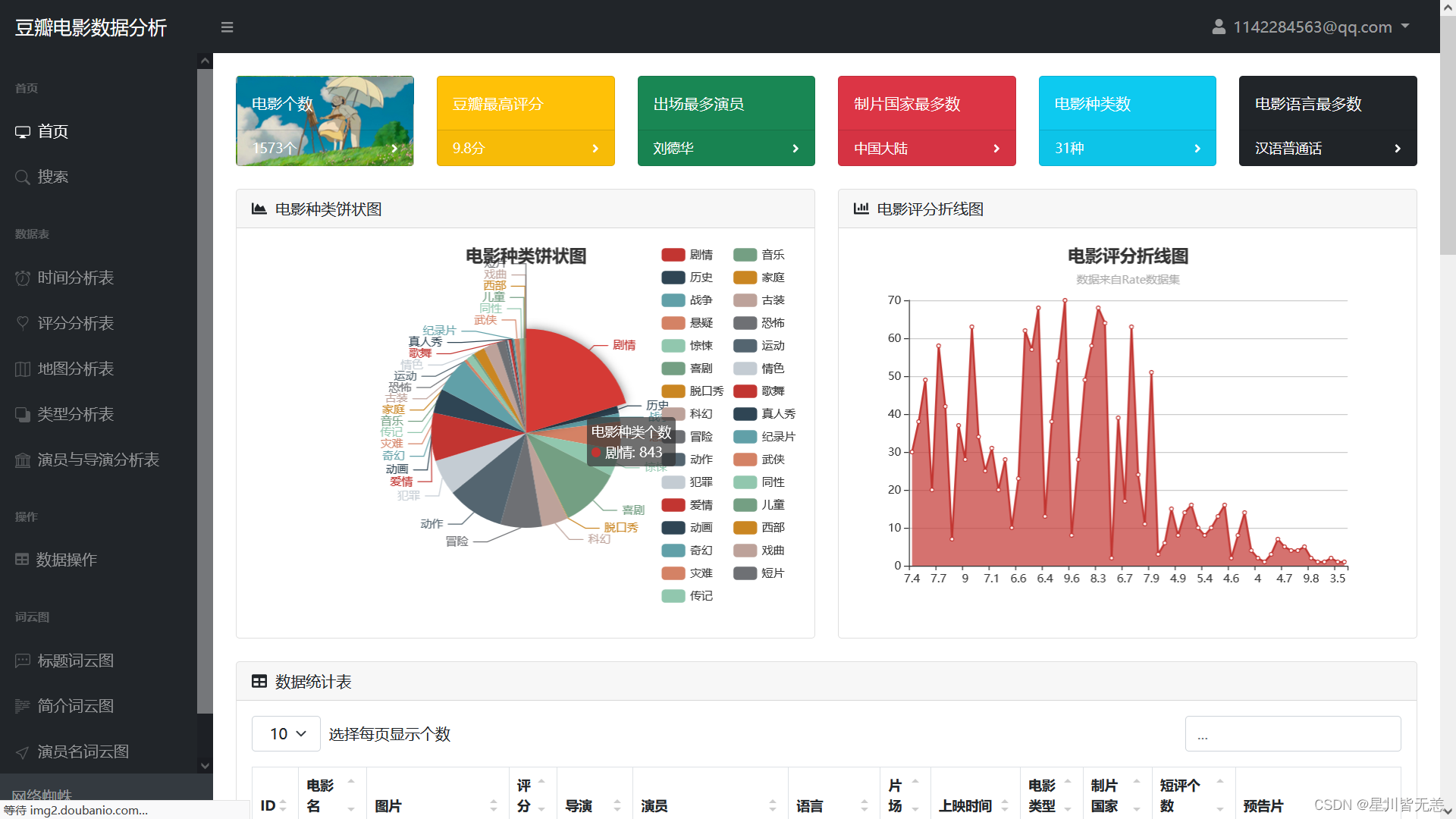
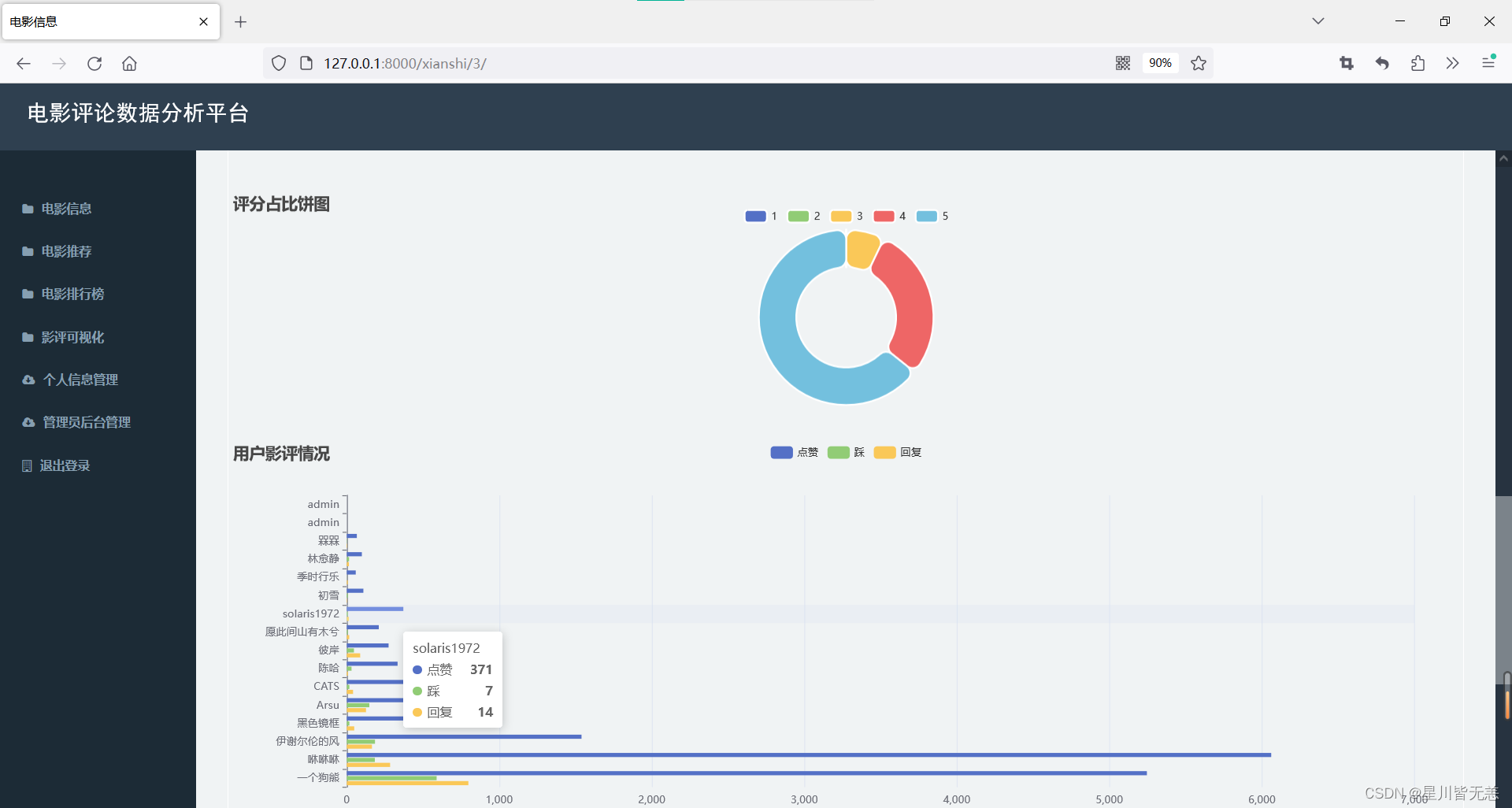
本项目旨在通过对豆瓣电影数据进行综合分析与可视化展示,构建一个基于Python的大数据可视化系统。通过数据爬取收集、清洗、分析豆瓣电影数据,我们提供了一个全面的电影信息平台,为用户提供深入了解电影产业趋势、影片评价与演员表现的工具。项目的关键步骤包括数据采集、数据清洗、数据分析与可视化展示。首先,我们使用爬虫技术从豆瓣电影网站获取丰富的电影数据,包括电影基本信息、评分、评论等存储到Mysql数据库
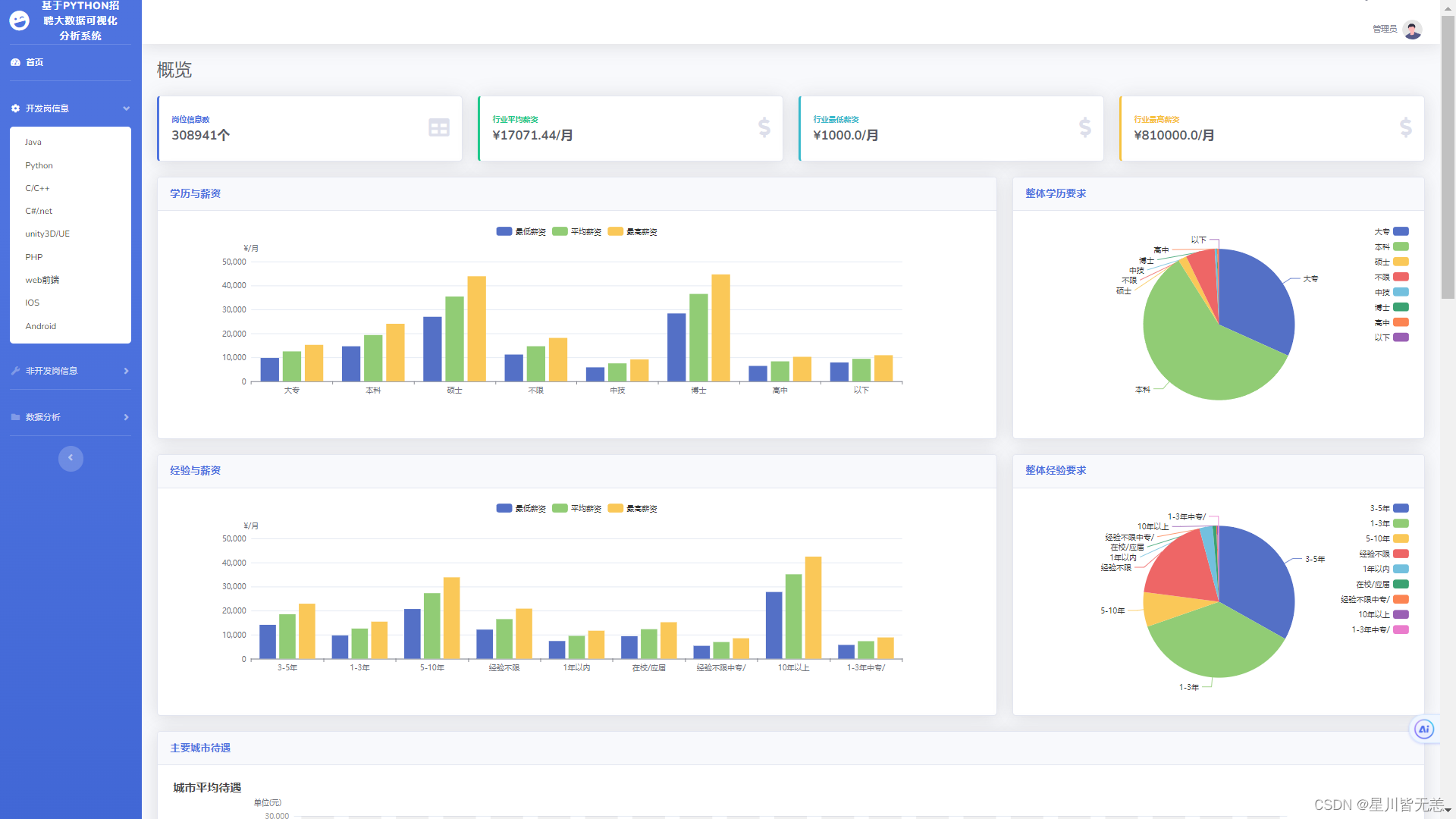
本文介绍了一个基于Python网络爬虫的IT招聘就业岗位可视化分析推荐系统。系统通过Selenium爬取Boss直聘等网站的70万条招聘数据,利用Pandas、NumPy等工具进行数据清洗和分析,并实现以下功能:1)职位数据词云可视化;2)多维度数据分析与图表展示;3)基于用户画像的岗位推荐算法;4)机器学习薪资预测模型。系统提供完整的Web界面,涵盖Java、Python、算法等IT岗位分析,支
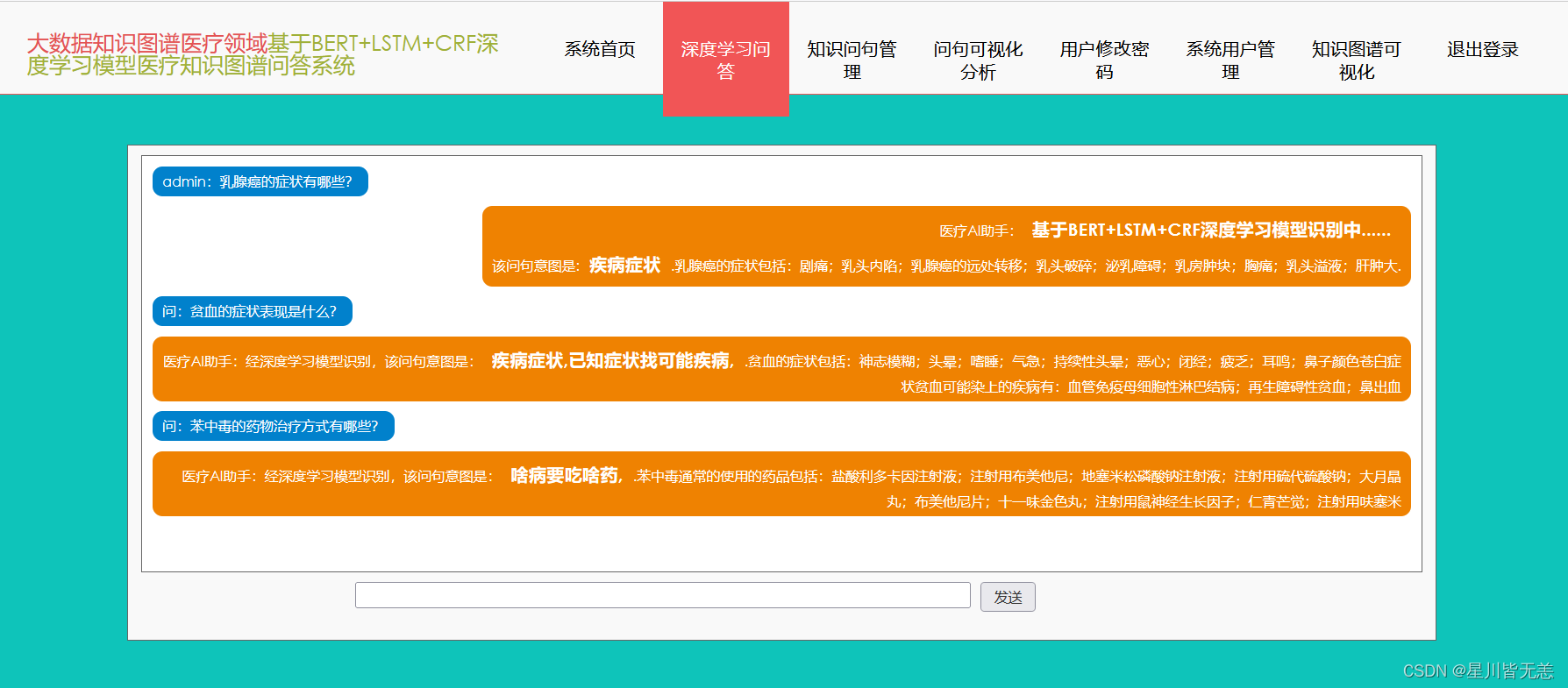
基于BERT+LSTM+CRF深度学习识别模型医疗知识图谱问答可视化系统通过构建医疗领域的知识图谱来实现计算机的深度学习,并且能够实现自动问答的功能。本次的内容研究主要是通过以Python技术来对医疗相关内容进行数据的爬取,通过爬取足量的数据来进行知识图谱的的搭建,基于Python语言通过echarts、Neo4j来实现知识图谱的可视化。通过智慧问答的方式构建出以BERT+LSTM+CRF的深度学
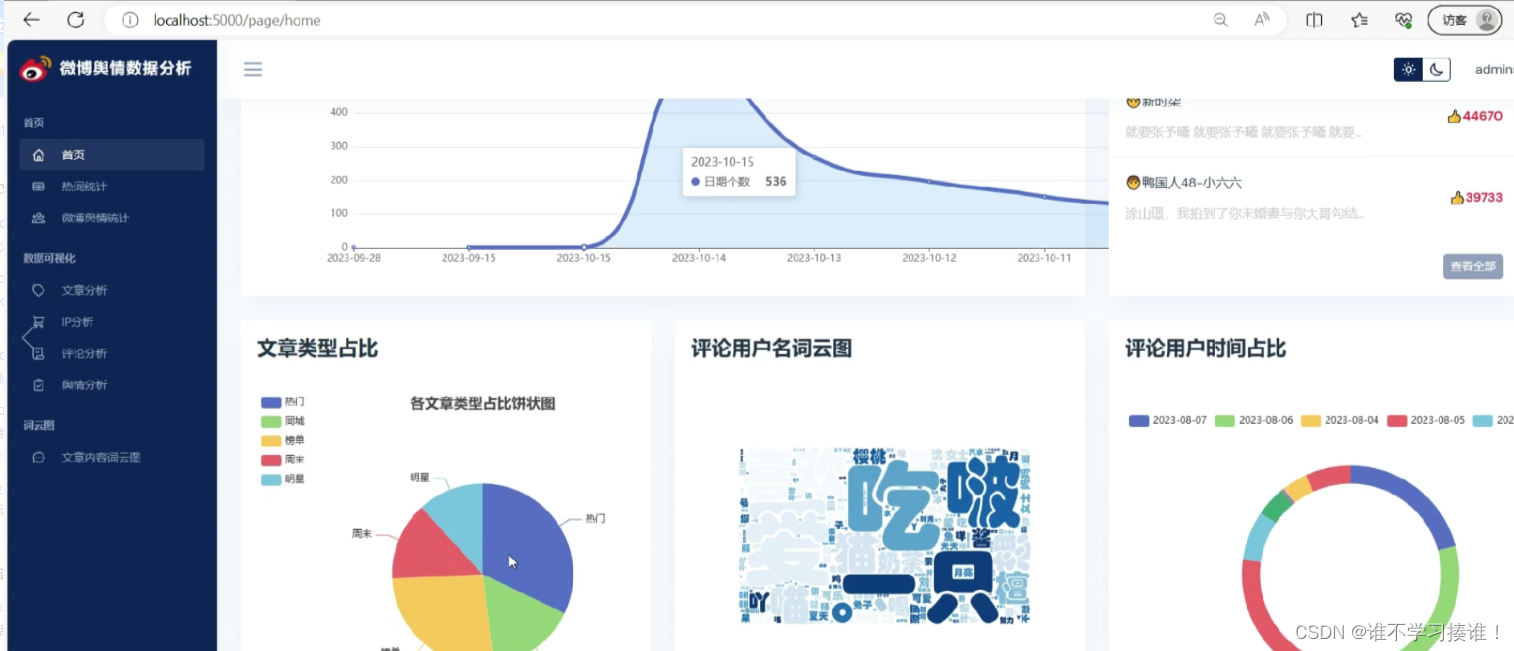
Python语言、Flask框架、MySQL数据库、requests网络爬虫技术、scikit-learn机器学习、snownlp情感分析、词云、舆情分析3、项目说明1.开发工具本项目主要采用 PyCharm 开放平台利用 Python 语言来实现的。PyCharm 是一种PythonIDE,带有一整套可以帮助用户在使用 Python 语言开发时提高其效率的工具。2.数据获取。
本项目构建了一个基于深度学习的电影推荐系统,整合了LSTM时序建模、协同过滤推荐算法、Scrapy爬虫和NLP情感分析等技术。系统通过爬取豆瓣电影数据,运用LSTM捕捉用户行为序列特征,结合UserCF和ItemCF双推荐算法实现个性化推荐。同时采用PaddleNLP对用户评论进行情感分析,并通过可视化界面展示电影数据统计和情感倾向。项目包含完整源码、详细文档和万字论文,实现了从数据采集、情感分析
Django(发音为"jan-go")是一个高级的Python web框架,它鼓励快速开发和干净、可重用的设计。Django 遵循经典的 Model-View-Controller(MVC)软件设计模式,但采用了稍微不同的结构。在Django中,这个模式被称为Model-View-Template(MVT)。负责数据存储和检索。定义数据模型,通过对象关系映射(ORM)将数据模型映射到数据库表。处理
本文介绍了一个基于Django框架的快递物流管理可视化系统。该系统针对电商快速发展背景下的物流管理需求,整合了运单录入、订单追踪、运输路线规划、配送员管理等核心功能模块。系统采用Bootstrap 4和AdminLTE前端框架,MySQL数据库,实现了物流全流程的可视化管理,包括运单管理、发车管理、到货管理、客户签收和财务管理等功能。通过数据可视化技术和权限管理机制,系统提升了物流运营效率和服务质
Django(发音为"jan-go")是一个高级的Python web框架,它鼓励快速开发和干净、可重用的设计。Django 遵循经典的 Model-View-Controller(MVC)软件设计模式,但采用了稍微不同的结构。在Django中,这个模式被称为Model-View-Template(MVT)。负责数据存储和检索。定义数据模型,通过对象关系映射(ORM)将数据模型映射到数据库表。处理
