




- @qq_47941078
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在官网查找版本时,我和 .whl 下载网页进行了对比,因为可能有的版本在 .whl 下载网也中没有,所以我找了相对较新且都能下载的。可能没有对应cuda版本的pytorch,所以即使你版本匹配,也可能会装cpu版的,这就导致测试时,永远是。然后我要安装的anaconda环境下,python版本是3.8的,所以我选择下载。这里为什么要直接对 .whl 文件进行下载,因为我之前修改了清华源下载,而。下

解决pycharm添加python2.7解释器出现Failed to create virtual environment和添加python3.8解释器SDK无效问题
A svm分类后概率为 0.98,B 概率为 0.86,通过对边界框进行IOU计算,大于我们设定的阈值说明是同一个目标,就把概率低的删掉。这里应该就是二值交叉熵损失,如果是softmax,对于是前景的概率应该也是更大的概率,而不是0.1这种,pi就是目标的概率。[u≥1] 的意思是:当 u 满足 ≥1时,这一项 = 1,当u不满足≥1时,就是对应背景时,这一项 =0。2000个框,每个框都得到40

CPU注重的是单线程的性能,要保证指令流不中断,需要消耗更多的晶体管和能耗用在控制部分,于是CPU分配在浮点计算的功耗就会变少。CNN是一种带有卷积结构的前馈神经网络,卷积结构可以减少深层网络占用的内存量,其中三个关键操作——局部感受野、权值共享、池化层,有效的减少了网络的参数个数,缓解了模型的过拟合问题。② 图像在数字化的过程中很难保留原有的特征,导致图像处理的准确率不高。CPU有大量的缓存结构

以猫分类为例,数据是离散值,二分类每个椭圆和矩阵称为树的节点,最顶层的叫做 树的根节点;所有椭圆形除了底部的框 都成为决策节点底部的节点即这些矩形框称为 叶子节点在以下这些不同的决策树中,有些更好,有的则更差,在所有的决策树中,尝试选择一个希望在训练集中表现良好的,然后再理想情况下也可以很好地推广到新数据,交叉验证和测试集也是如此。...............

也就是说对于每个分类器来说,我扔掉的东西就一个不是人脸,不是正例,保留下来的还不确定,就这样的过程叠加若干的,每个分类器也不一样,最后剩下的才是真正的正例。就是画的框就是背景和前景的颜色分布都有了,然后找这些颜色分布找若干个聚类中心,框之外的颜色就是背景,背景也找若干个聚类中心;要做的就是在不断的迭代过程中,框住的颜色里属于背景的就会逐渐被归到框外的聚类中心上,框里面的就仅仅属于自己。梯度每落在2

为了检测出这个 6 ×6 图像的垂直边缘,构建一个 3×3 的过滤器(filter),或者称为核,进行卷积运算 *,输出得到一个 4×4 的矩阵,里面元素的运算过程如下图所示,以第一行第一列的元素为例:这个即为:垂直边缘检测器不同编程框架下的卷积运算:python:conv_forward 函数tensorflow:tf.nn.conv2d 函数Keras:Conv2D 函数为什么这个可以做 垂直

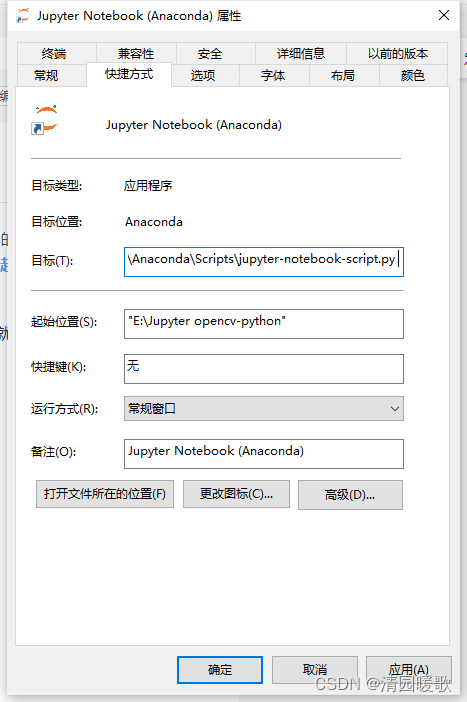
但实际上,因为我修改过,它问了一次y/n,当时没注意,其实他是询问是否覆盖,我当时直接y了就给我覆盖了,导致我之前的修改无效了,anaconda环境打开的目录也恢复成了默认路径。博主之前一开始安装anaconda时,曾经修改过默认打开目录,采用的方法是直接修改,即找到文件位置-属性-快捷方式,删除。将第二行的#和空格去掉,修改自己的路径,该方法确实可以,但还是无法满足我两个环境分别打开两个目录的需
图像预处理实际就是一个图像增强的过程:空间域:点运算:就是基于直方图对图像整体的色差进行调整,对一个点颜色进行调整,跟周围或多或少也有点关系形态学运算:腐蚀、膨胀临域运算:每个点跟他周围的点进行比较或一块进行计算把空间域映射到频率域,对于我们这里来说,意义就是快速计算卷积傅里叶变换小波运算。
相差很小,但是DoG计算量小很多,差分高斯就是不同高斯核滤波,相减。其实是在找不同尺度上的特征,小的是在找原图的大特征。斑点就是二阶导数取最大值、最小值的地方。LoG:先高斯,再拉普拉斯。