




- @qq_41929714
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要: AI经历了从符号主义(规则系统)到机器学习(数据驱动),再到深度学习(神经网络)的演进。自然语言处理(NLP)是AI的核心领域,早期依赖统计方法,后由Transformer架构(基于自注意力机制)革新。大语言模型(LLM)如GPT通过海量数据预训练(T-P-G原则:Transformer结构、预训练、生成式预测)实现文本理解与生成,其核心是逐token概率预测。Transformer的并行
本文介绍如何使用Docker Compose搭建包含MySQL 8.4.7、Elasticsearch 8.18.8、Redis 8.4.0和SkyWalking 10.3.0的开发环境。通过.env文件实现完全变量化配置,包括端口号、账号密码、环境标识(dev/test/prod)等。系统自动为容器名、服务名添加环境后缀,并统一管理挂载目录路径。Docker Compose文件通过变量引用.en
本文简要介绍 Milvus 向量数据库的部署与使用流程,包括 Milvus 的基本概念、部署方式及 Standalone 架构。重点说明如何通过 Docker Compose 部署 Milvus,并结合 .env、milvus.yaml 和 docker-compose.yml 完成环境配置。同时介绍 etcd 与 MinIO 等依赖组件的作用,并给出启动步骤和访问地址,帮助快速搭建 Milvus

Xshell 8和Xftp 8官方免费版下载指南 NetSarang官方提供Xshell 8和Xftp 8家庭/学校免费版,现已取消标签限制,支持无限标签功能。用户需通过官网(免费下载页面)获取最新版本,安装后需邮箱注册认证。此外,百度网盘也提供下载(提取码:67fh)。适用于SSH管理和文件传输需求,适合个人及教育用途。
解决ICMP timestamp请求响应漏洞:在您的防火墙上过滤外来的ICMP timestamp(类型 13)报文以及外出的ICMP timestamp回复报文

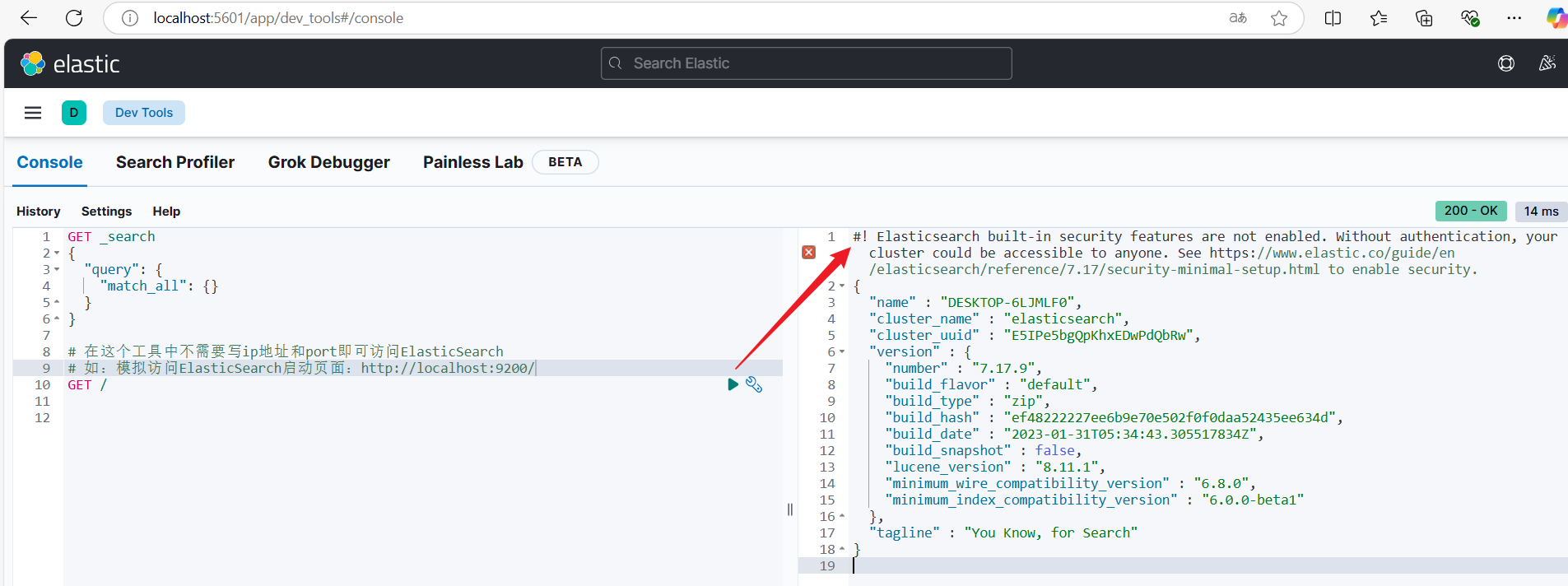
ElasticSearch 是一个开源的分布式搜索和分析引擎,广泛应用于各种数据检索、实时分析和日志管理场景。它是基于 Apache Lucene 构建的,提供了比 Lucene 更强大的分布式能力和更高效的搜索与分析性能。ElasticSearch 在多个领域都有广泛的应用,包括日志数据分析、监控、实时搜索、推荐系统等。ElasticSearch 提供了强大的 RESTful API,便于与其他
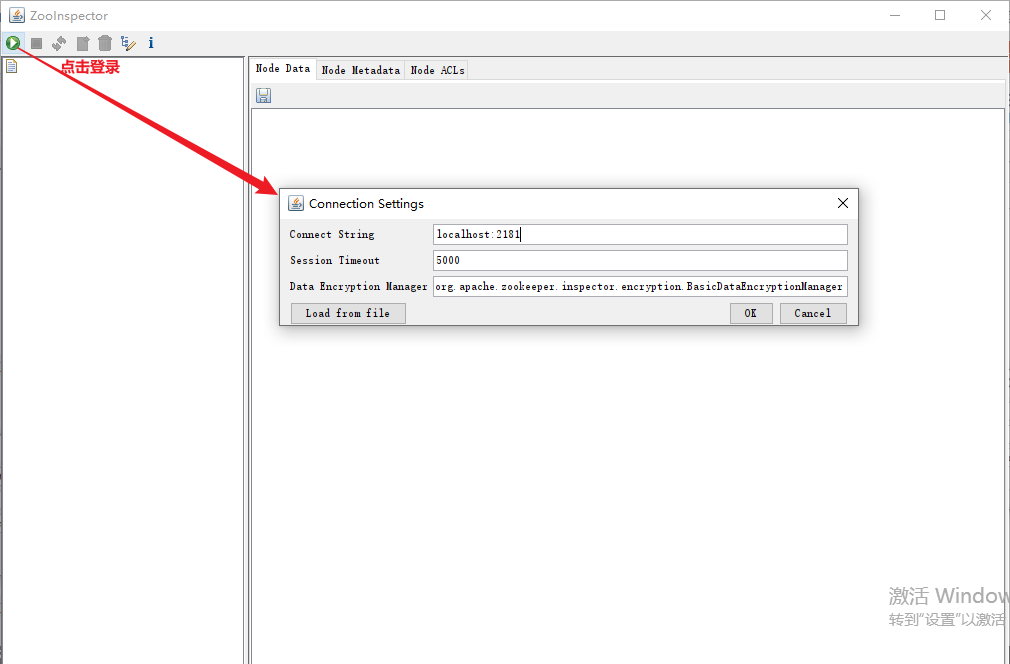
介绍三款Zookeeper可视化工具。
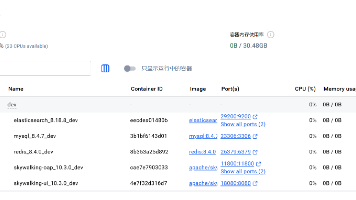
本文介绍如何使用Docker Compose搭建包含MySQL 8.4.7、Elasticsearch 8.18.8、Redis 8.4.0和SkyWalking 10.3.0的开发环境。通过.env文件实现完全变量化配置,包括端口号、账号密码、环境标识(dev/test/prod)等。系统自动为容器名、服务名添加环境后缀,并统一管理挂载目录路径。Docker Compose文件通过变量引用.en
在 React 项目中执行 yarn eject 后,create-react-app 隐藏的 Webpack 配置将被暴露,生成 config/ 目录。该目录包含构建、开发和测试所需的配置文件,如 env.js(环境变量配置)、getHttpsConfig.js(HTTPS 配置)、modules.js(模块路径配置)、paths.js(项目路径管理)、webpack.config.js(Web

springboot工程搭建层级目录图搭建父工程parent需要注意的父工程pom搭建api工程搭建api子父工程搭建api子工程搭建网关gateway工程搭建service工程搭建service子父工程搭建子工程pdx-goods-service、pdx-file-service搭建公共工程util搭建common子父工程搭建service-dependency子父工程搭建web工程错误打包报错