




- @qq_24923619
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
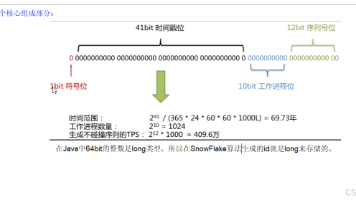
雪花算法是分布式 ID 生成的“轻量级王者”,核心是通过 64 位字段划分实现“全局唯一、有序、高性能”的 ID 生成。本文从“是什么(入门)→ 怎么设计(原理)→ 怎么用(实战)→ 怎么优化(进阶)”四个维度,帮你掌握雪花算法的核心逻辑。核心记忆点:64 位结构(1 符号 + 41 时间 + 10 机器 + 12 序列)、线程安全(原子类/CAS)、防时钟回拨。生产建议。
HashMap 基于数组+链表/红黑树实现,通过哈希函数将键(Key)映射到数组索引,解决哈希冲突时用链表存储相同索引的元素,当链表长度超过阈值(默认8)且数组长度≥64时,链表会转为红黑树以提升查询效率。若索引位置为空,直接存入元素(Node 对象,包含 Key、Value、哈希值、下一个节点引用)。◦链表:逐个比较节点的哈希值和 Key,找到则返回 Value,否则返回 null。◦否则遍历链

继承Thread类:简单直接,但Java单继承限制了灵活性。实现Runnable接口:避免单继承限制,推荐使用。实现Callable接口:适合需要返回结果或可能抛出异常的场景。线程池:适合需要创建多个线程的场景,能有效管理线程资源,是实际开发中的首选方式。在实际开发中,通常优先选择实现Runnable或Callable接口的方式,而非继承Thread类,以提高代码的灵活性和可维护性。线程池则更是企

Java设计模式解析:三大类核心模式及应用场景 设计模式是解决软件常见问题的成熟方案,分为创建型、结构型和行为型三大类。创建型模式(如单例、工厂、建造者)专注于对象创建和管理;结构型模式(如适配器、装饰器、代理)优化对象组合关系;行为型模式(如观察者、策略、模板方法)规范对象交互方式。每种模式都通过生活化类比(如皇帝、电源适配器、经纪人等)帮助理解其原理和应用价值,实现了代码复用、解耦和灵活扩展等

双亲委派是 Java 类加载器(ClassLoader)加载类时遵循的层级委派规则:当一个类加载器需要加载某个类时,它不会先自己尝试加载,而是先委托给“父加载器”去加载;总结:双亲委派通过“自上而下委托、自下而上加载”的规则,既保护了 JDK 核心类的安全,又保证了类加载的一致性,是 Java 类加载机制的核心设计。应用类加载器收到加载 com.example.User 的请求,先委托给父加载器(

适用于需“部分状态持久化”“加密存储”或“自定义存储时机”的场景,通过 Pinia 的onMounted(Store 初始化)和watch(状态变化)实现。userStore持久化用户 ID 和 Token(加密存储)// src/utils/encryption.js(简易加密工具,实际项目推荐用 CryptoJS)// 简单 Base64 加密(生产环境需用 AES 等强加密)try {ret

【代码】【Vue3】【笔记】----第二章:Vue3 响应式系统(从原理到实战落地)

【代码】【Vue3】【笔记】----第一章:Vue3 基础入门与环境搭建(从0到1建立认知)

Vue3组合式API通过<script setup>语法糖解决了Options API逻辑分散的问题,使相关代码更聚合。核心功能包括computed(计算属性)、watch(监听数据变化)和watchEffect(自动依赖追踪)。通过组合式函数(如useCounter)可实现逻辑复用,提升代码可维护性。实战案例展示了如何用组合式API开发TodoList,包括数据管理、功能实现和组件拆

Vue3 项目是单页应用(SPA),部署时需解决“路由刷新404”“资源访问路径”两个核心问题,推荐用 Nginx 作为服务器。Vue3 项目推荐用 Vite 构建(比 Webpack 更快),通过修改。项目优化不是“锦上添花”,而是上线前的“必备步骤”——核心目标是。(减少线上报错),最终提升用户体验和搜索引擎排名(SEO)。:对“首屏必需的资源”(如核心 JS、CSS、字体)用。(让页面加载/
