- @pythonhy
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
AI Agent 千行实战:6 个设计套路,从代码看懂 Agent 怎么跑
AI Agent 千行实战:6 个设计套路,从代码看懂 Agent 怎么跑
AI知识库已成为提升效率的核心工具。今天我将通过企业实际落地案例,详解从架构设计到性能优化的全流程技术方案,助你避开共性陷阱。
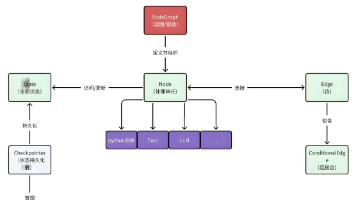
在开发复杂的大语言模型应用时,工程师常被多步推理、状态管理和任务协调等问题困扰。传统代码结构在应对涉及决策、回溯、状态传递和多轮交互的场景时往往力不从心。
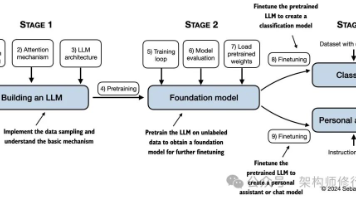
让你通过亲手编写代码,彻底搞懂那些复杂的LLM是如何从里到外工作的。这就像是拆解一辆汽车,然后一个零件一个零件地重新组装,这过程中你会对它有全新的理解。
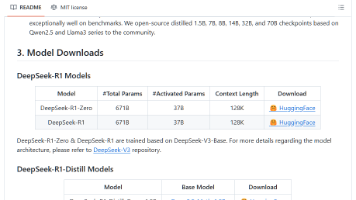
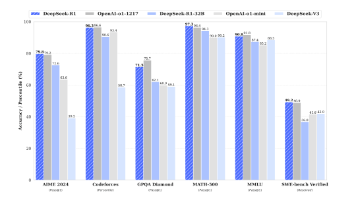
DeepSeek-R1的论文介绍中不仅描述了比较完整的技术实现路径,同时也提供了一些失败的实验尝试,这给其他厂商提供了完整的复现方式。先看一下大模型的效果。
这是一种结合了检索(Retrieval)和生成(Generation)的机器学习模型,通常用于自然语言处理任务,如文本生成、问答系统等。
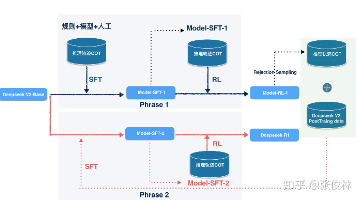
随着大模型应用不断落地,知识库,RAG是现在绕不开的话题,但是相信有些小伙伴和我一样,可能会一直存在一些问题,
我们打开deepseek官网,会发现对话框之下:有两个按钮,那他们的含义如何理解🤔?最近爆火的deepseek究竟指的是哪个模型?深度思考R1与联网搜索的作用?
自从 DeepSeek 发布后,对 AI 行业产生了巨大的影响,以 OpenAI、Google 为首的国际科技集团为之震惊,它的出现标志着全球AI竞争进入新阶段。从以往单纯的技术比拼转向效率、生态与战略的综合较量。