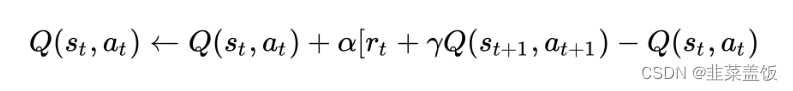- @niulinbiao
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
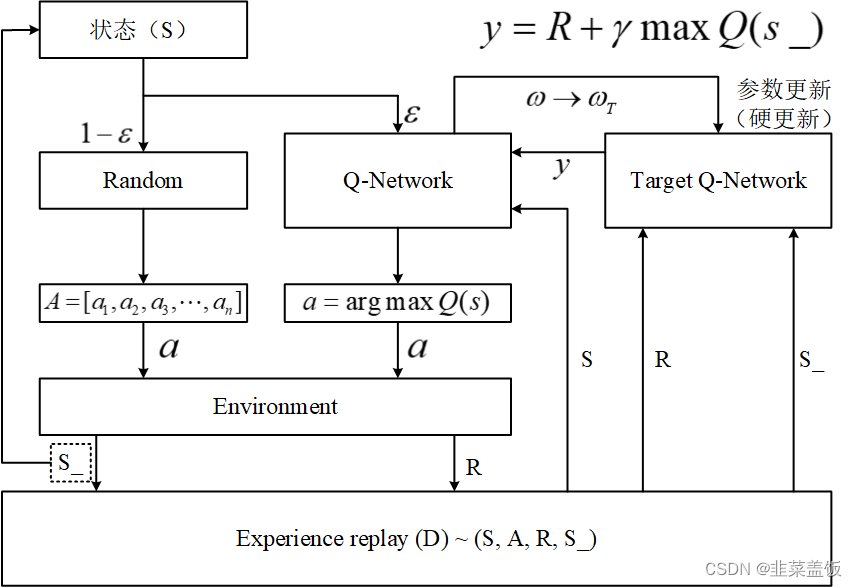
DQN,即深度Q网络(),是指基于深度学习的Q-Learing算法。Q-Learing算法维护一个Q-table,使用表格存储每个状态s下采取动作a获得的奖励,即状态-价值函数Q(s,a),这种算法存在很大的局限性。在现实中很多情况下,强化学习任务所面临的状态空间是连续的,存在无穷多个状态,这种情况就不能再使用表格的方式存储价值函数。为了解决这个问题,我们可以用一个函数Q(s,a;w)来近似动作-
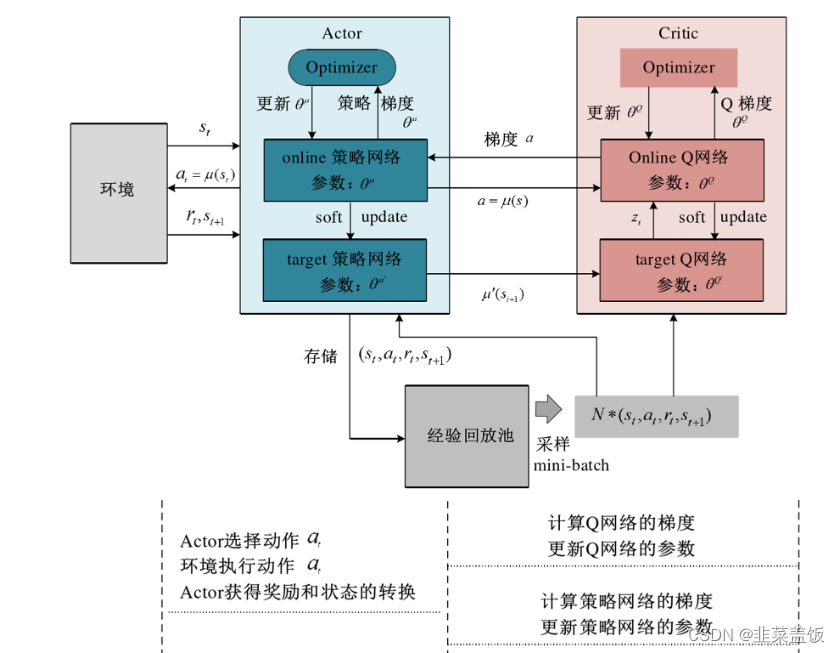
算法是DeepMind团队提出的一种专门用于解决连续控制问题的在线式(on-line)深度强化学习算法,它其实本质上借鉴了算法里面的一些思想。本文将会介绍其基本原理,并实现DDPG算法来训练游戏的例子。
Q learning算法是一种的强化学习算法,Q是quality的缩写,Q函数 Q(state,action)表示在状态state下执行动作action的quality, 也就是能获得的Q value是多少。算法的目标是最大化Q值,通过在状态state下所有可能的动作中选择最好的动作来达到最大化期望reward。Q learning算法使用Q table来记录不同状态下不同动作的预估Q值。

PPO算法之所以被提出,根本原因在于在处理连续动作空间时取值抉择困难。取值过小,就会导致深度强化学习收敛性较差,陷入完不成训练的局面,取值过大则导致新旧策略迭代时数据不一致,造成学习波动较大或局部震荡。除此之外,因为在线学习的性质,进行迭代策略时原先的采样数据无法被重复利用,每次迭代都需要重新采样;同样地置信域策略梯度算法虽然利用重要性采样、共轭梯度法求解提升了样本效率、训练速率等,但在处理函数的
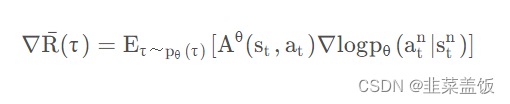
PPO算法之所以被提出,根本原因在于在处理连续动作空间时取值抉择困难。取值过小,就会导致深度强化学习收敛性较差,陷入完不成训练的局面,取值过大则导致新旧策略迭代时数据不一致,造成学习波动较大或局部震荡。除此之外,因为在线学习的性质,进行迭代策略时原先的采样数据无法被重复利用,每次迭代都需要重新采样;同样地置信域策略梯度算法虽然利用重要性采样、共轭梯度法求解提升了样本效率、训练速率等,但在处理函数的
算法是DeepMind团队提出的一种专门用于解决连续控制问题的在线式(on-line)深度强化学习算法,它其实本质上借鉴了算法里面的一些思想。本文将会介绍其基本原理,并实现DDPG算法来训练游戏的例子。
整理一些常见八股问题,用于面试复习。
Q learning算法是一种的强化学习算法,Q是quality的缩写,Q函数 Q(state,action)表示在状态state下执行动作action的quality, 也就是能获得的Q value是多少。算法的目标是最大化Q值,通过在状态state下所有可能的动作中选择最好的动作来达到最大化期望reward。Q learning算法使用Q table来记录不同状态下不同动作的预估Q值。
springboot + mybatis进行分页以及模糊查询后端部分导入依赖<!-- mybatis的分页助手--><dependency><groupId>com.github.pagehelper</groupId><artifactId>pagehelper</artifactId><version>5.1.
是一个学习马尔可夫决策过程策略的算法,通常应用于机器学习和强化学习学习领域中。它由Rummery和Niranjan在技术论文“” 中介绍了这个算法,并且由Rich Sutton在注脚处提到了SARSA这个别名。这个名称清楚地反应了其学习更新函数依赖的5个值,分别是当前状态S1,当前状态选中的动作A1,获得的奖励RewardS1状态下执行A1后取得的状态S2及S2状态下将会执行的动作A2。我们取这5