




- @m0_73800387
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
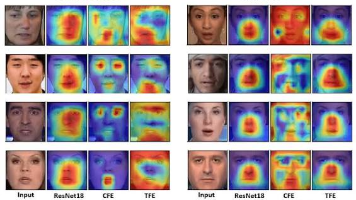
本文手把手从 YOLOv8 模型结构出发,推导 CAM/Grad-CAM/Grad-CAM++ 的数学原理,给出一个完整可跑的 YOLO 检测模型可解释性部署方案——含虚拟环境配置、代码适配、热力图可视化与视频交互控制。
本文提供了一种基于rosbridge-websocket实现跨网络的ROS1与ROS2通讯。(c++实现)

本文同时介绍了完整的从生成密钥、上传密钥、到配置ssh别名的全流程。

关于ROS2的setup.bash的详解

本文介绍了在 RDK X5 上实现多摄像头视觉推理的方法:通过 V4L2 控制带宽解决 USB 共享问题,利用 ROS2 remapping 区分多路摄像头,并用中间调度节点实现输入源动态切换;结合 shared memory 零拷贝与 codec 转换,完成“多摄像头采集 → 统一推理入口 → DNN 推理 → Web 显示”的低延迟视觉处理流程。

本文针对带中心机械臂的麦克纳姆底盘提出了一种双2D激光雷达融合方案,通过 udev 实现设备稳定映射,结合 tf2 构建统一坐标系,并将 LaserScan 转换为 PointCloud2 后进行空间融合与ROI过滤,最终再反投影生成新的 LaserScan 数据流,从而有效解决单雷达遮挡导致的感知缺失问题,实现了稳定可靠的全局环境感知结构。

本文手写 RRT 与 RRT* 两种采样规划器——从随机撒点、最近邻扩展到择优父节点与重连接优化,以 Nav2 插件形式注册,让机器人在复杂场景中快速找到渐近最优的路径。
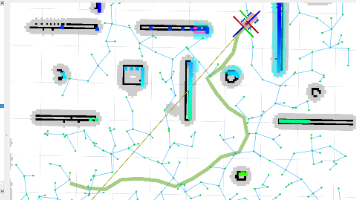
本文手写 Hybrid-A* 全局规划器——从自行车运动学模型推导到 C++ 代码实现,以 Nav2 插件形式注册并替换默认规划器,让机器人学会"考虑朝向、会倒车"的路径规划。

本文从移动机器人实时定位的需求出发,完整走了一遍基于 ICP 的点云定位方案——用先验地图 + 当前扫描 → 估计机器人精确位姿。从 SVD 闭式求解的数学推导,到手写 C++ 实现,再到离群点剔除、多分辨率加速、自适应退火等工程优化。

本文从安装、API 配置、第三方切换工具,到实际使用、高级冷知识,系统性地介绍 Claude Code的使用方式。
