- @m0_71745484
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
关于,一直以来是从业者们关注的话题。业界普遍认为,尽管AI大模型如GitHub的Copilot和OpenAI的ChatGPT等工具日益强大,但这并不会让程序员失去工作。相反,AI的发展能为程序员带来新的发展机遇。人工智能并不是替代程序员,而是提高程序员生产效率的工具。无论是底层程序员,还是其他类型的开发者,都将受益于AI的帮助。人工智能能够协助程序员做一些代码生成、测试用例生成、代码优化、自动添加

物流行业的高效运转离不开知识的精准管理和快速响应。然而,面对客户咨询高频、员工内部知识分散等问题,传统规则驱动的系统往往显得力不从心。如何借助大语言模型(LLM)打造一套智能知识问答系统,成为提升物流企业竞争力的关键所在。本文以物流行业为背景,从系统架构、实际案例和代码实现的角度,为你详细解读如何构建一套基于大语言模型的高效知识问答系统。一、物流行业的需求背景客户咨询高频但重复性强: 客户的询问内

技术并不是一个一蹴而就的过程,而是一个逐渐发展的过程”大模型火了也有两年时间了,然后很多人也在不断的学习大模型技术,但很多人一直没学明白什么是大模型技术;他们所理解的大模型技术就是官方给出的大模型定义,但根本不知道为什么需要大模型技术,以及大模型为什么会是这个样子。今天,我们就抛开技术来思考一下,什么是大模型?什么是大模型?如果你问一个人什么是大模型,如果是一个技术人员他肯定会告诉你,大
网络安全产业就像一个江湖,各色人等聚集。相对于欧美国家基础扎实(懂加密、会防护、能挖洞、擅工程)的众多名门正派,我国的人才更多的属于旁门左道(很多白帽子可能会不服气),因此在未来的人才培养和建设上,需要调整结构,鼓励更多的人去做“正向”的、结合“业务”与“数据”、“自动化”的“体系、建设”,才能解人才之渴,真正的为社会全面互联网化提供安全保障。

今天我对kimi常见的高级用法进行了总结,希望可以帮助到大家~,kimi功能多多,越用越爽,不愧为当红AI大模型。首先我们需要打开kimi的官网:https://kimi.moonshot.cn/,注册登录后, 下面开始我们今天的主题~本文目录背景介绍用法一:充当无广告的智能总结搜索引擎用法二: 设置常用语,快速实现小红书爆文和短剧脚本短剧脚本效果展示小红书爆文常用语设置和效果展示用法三: 让大模

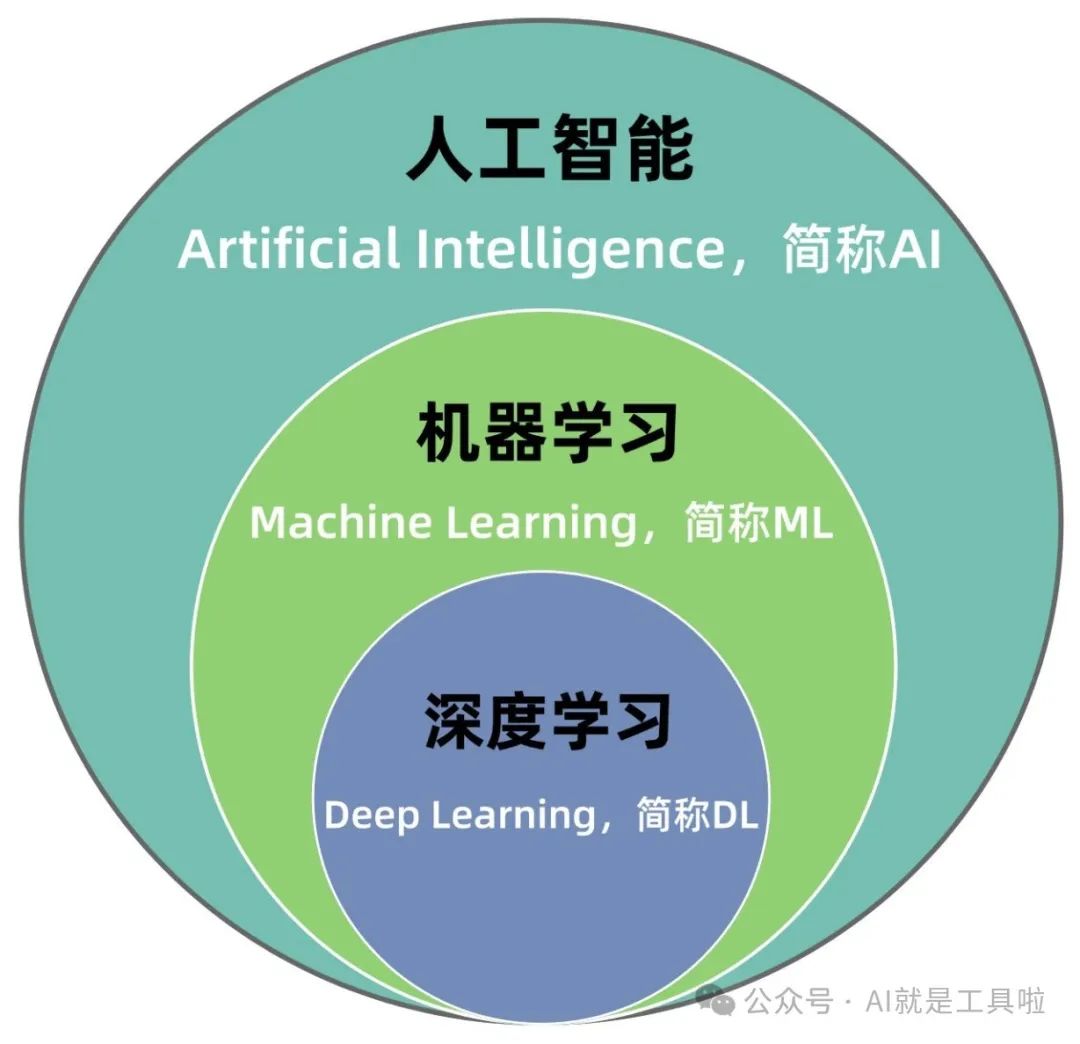
最近人工智能AI(Artificial Intelligence)很热门,讨论的人也越来越多。现在国内互联网大厂越来越重视AI了,开发了很多AI应用工具产品。那什么是AI,国内大厂在AI方面又做了哪些布局呢?人工智能简称AI,是一种利用计算机模拟人类智能的技术和方法。它涵盖了机器学习、深度学习、自然语言处理等多个领域,旨在让计算机能够像人类一样进行感知、理解、推理和决策。人工智能的发展离不开大模型

热门领域需求旺盛:人工智能、大数据、云计算、网络安全、芯片设计、自动驾驶等领域技术迭代快,高端人才缺口大。传统互联网岗位饱和:前端、后端开发等基础岗位因前几年扩招导致竞争加剧,中小厂“降本增效”下招聘门槛提高。新兴交叉领域崛起:如AI+医疗、AI+金融、工业软件、机器人等,需要“计算机+行业知识”的复合型人才。
计算机专业就业方向多样,除了程序员外还有多种高薪岗位选择。AI算法类岗位包括人工智能算法工程师、推荐算法工程师、机器学习工程师等,负责开发智能系统、个性化推荐和数据分析。后端开发类岗位涵盖全栈工程师、大数据开发工程师、区块链开发工程师等,涉及服务端开发、数据处理和去中心化应用。这些岗位在科技公司如Google、Netflix、特斯拉等都有成功应用案例,展现了计算机专业广阔的就业前景。

学习推理大模型(如GPT-4、PaLM、LLaMA等)需要结合深度学习、自然语言处理(NLP)和逻辑推理的知识。:掌握线性代数、概率统计、微积分(如梯度下降)、信息论(如交叉熵)。:熟练使用Python,学习PyTorch或TensorFlow框架。:理解经典算法(如动态规划、搜索算法)和机器学习基础(如监督学习、无监督学习)。学习传统模型(如线性回归、SVM、决策树)。掌握深度学习基础:神经网络
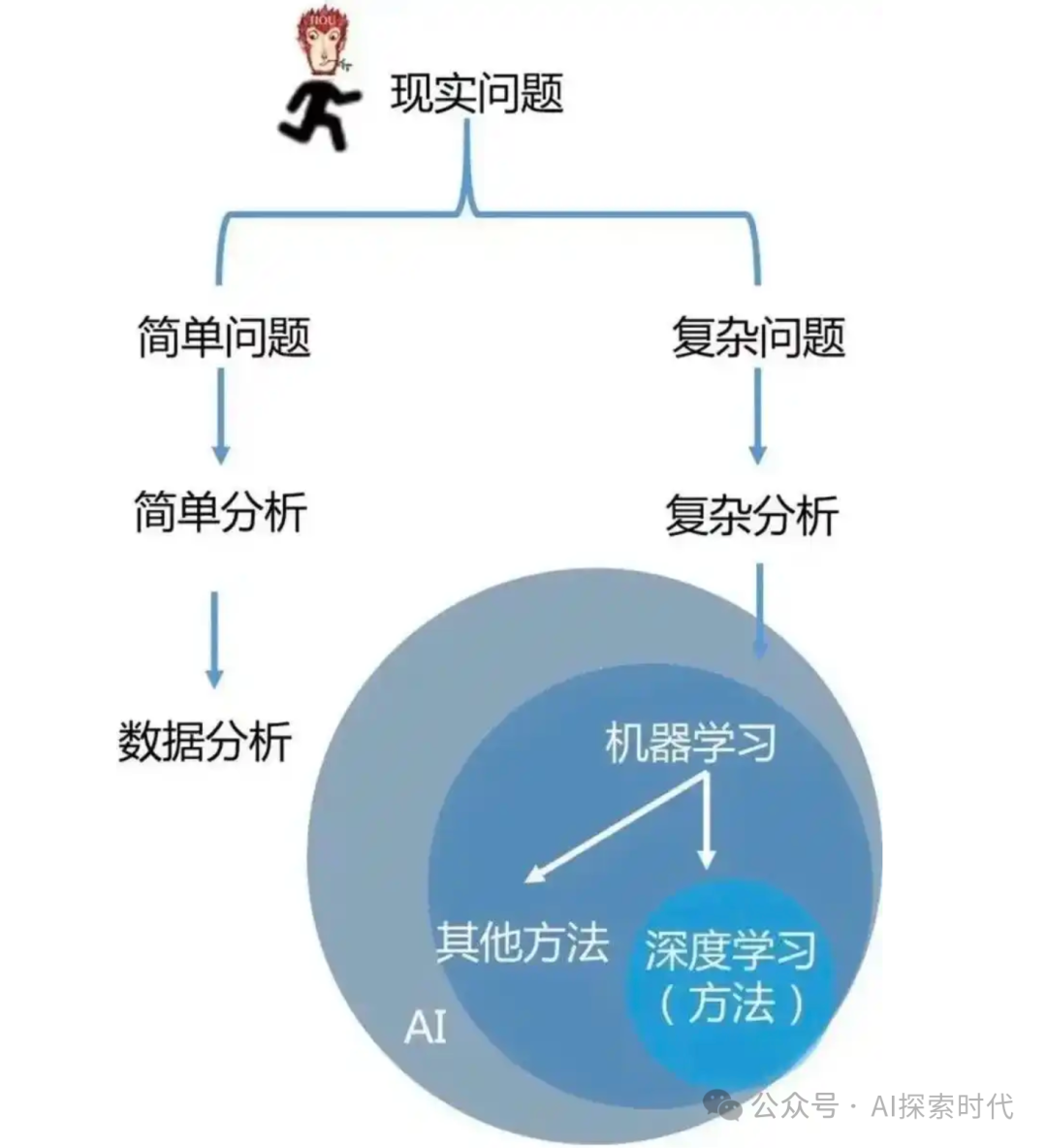
人工智能包括机器学习和深度学习深度学习,而自然语言处理和计算机视觉正是人工智能领域热门的方向。**路径一:**如果你希望快速学习完进行项目实践,请直接学习深度学习,不过编程和数学基础还是要有的(之后如果遇到不懂的地方,单独学不懂的地方就可以了)**路径二:**一步一个脚印,扎扎实实从基础学起,逐步提高学习难度(后附学习大纲)在深入学习人工智能之前,你需要对这个行业有一个初步的了解,包括当前的发展趋