
写文章




- @m0_46324847
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
说话人识别中的数据需求
机器学习领域名言“Garbage In, Garbage Out!”不论神经网络多么先进,如果输入是垃圾,那么输出也一定是垃圾在说话人识别领域,所需的最小数据单元,包括:一段只包含单一说话人语音的音频,被称为Utterance(话语)该段音频的说话人标签,能够唯一地在整个数据集中标识该说话人怎么样的数据不是Garbage呢?或者说,如何评价一个数据集的质量呢?有以下这些指标:说话人的数量每个说话人
Conda虚拟环境管理,示例:安装GPU版PyTorch、解决PowerShell启动时无法激活虚拟环境的问题、导出导入环境、安装GCC编译器
【代码】Conda虚拟环境管理,示例:安装GPU版PyTorch、解决PowerShell启动时无法激活虚拟环境的问题、导出导入环境、安装GCC编译器。
深入理解ECAPA-TDNN——兼谈Res2Net、ASP统计池化、SENet、Batch Normalization
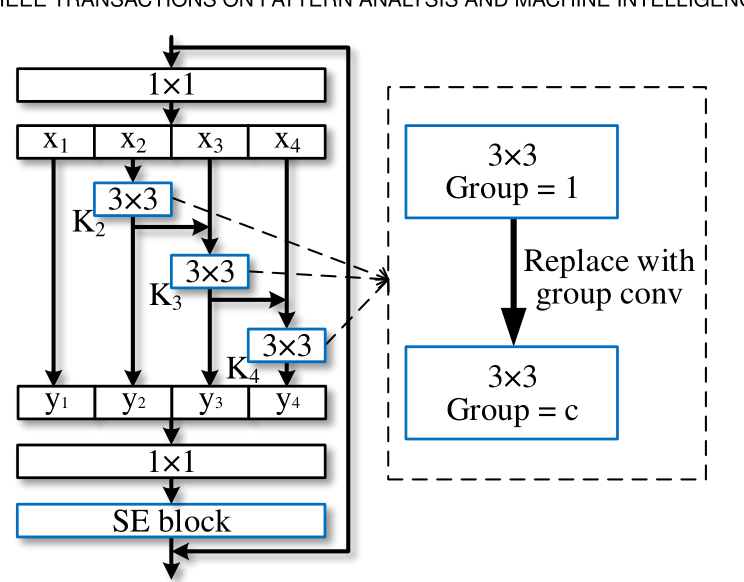
ECAPA-TDNN是说话人识别中基于TDNN的神经网络,是目前最好的单体模型之一关于TDNN,可以参考深入理解TDNN(Time Delay Neural Network)——兼谈x-vector网络结构。
深入理解ECAPA-TDNN——兼谈Res2Net、ASP统计池化、SENet、Batch Normalization
ECAPA-TDNN是说话人识别中基于TDNN的神经网络,是目前最好的单体模型之一关于TDNN,可以参考深入理解TDNN(Time Delay Neural Network)——兼谈x-vector网络结构。
到底了