




- @llovewuzhengzi
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
项目地址:https://github.com/Narwhal-Lab/MagicSkills很多团队做多 Agent,最先失控的不是模型,而是 skill 管理。同一个 skill 目录,往往既想给 Codex、Cursor、Claude Code 这类 Agent 应用使用,也想给 LangChain、LangGraph 这类框架里创建的多个 agent 使用。

卷积神经网络(Convolutional Neural Network),多用于图像识别,但不仅仅用于图像识别。不过我们在学习卷积神经网络的过程中,可以把图像识别当成假想任务,理解起来会更直观一些。为什么图像数据从多维(图像的原始格式)转化为一维向量(供全连接神经网络处理)时,为何会丢失空间和通道的相关信息,以及可能隐藏的模式信息。想象我们正在处理一张包含蓝天和绿色草地的照片,天空和草地之间有一个

例如,如果父 cgroup 只允许使用 CPU 0 和 CPU 1,那么即使子 cgroup 可以使用所有 CPU,但 cpuset.cpus.effective 也只会显示 CPU 0 和 CPU 1。假设我们有两个 cgroup,“D”和“E”,我们希望“D”获得三倍于“E”的 CPU 时间,但我们还希望限制“D”在 2 秒内只能使用 1 秒的 CPU 时间。这意味着,即使当前 cgroup

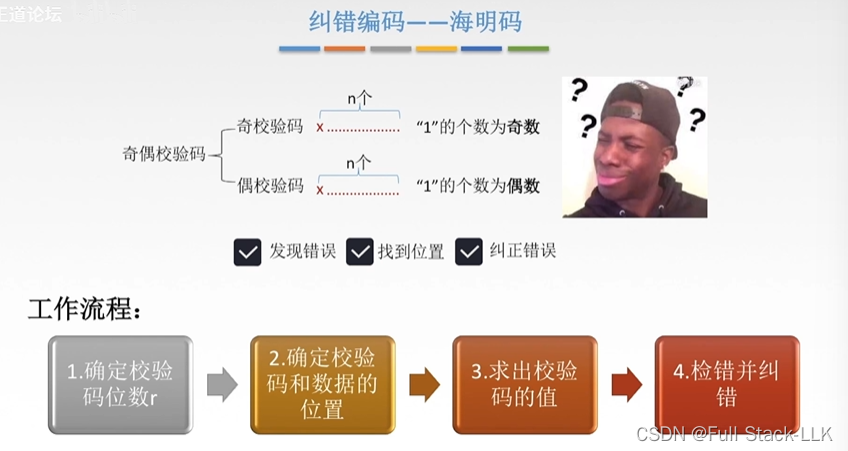
如果码距为2d+1,那么即使发生了d位错误,错误的码字与所有合法码字的最小汉明距离至少为d+1,这意味着接收方可以通过比较接收到的码字与所有合法码字的海明距离来确定最有可能的原始码字。这是因为如果码距为d+1,那么任何d位的错误都会导致编码从一个合法码字变为另一个非合法码字,而不会与任何其他合法码字相同。正确的部分2号校验码2,3,6,7那么没有问题,错误的部分1号和4号校验码的公共部分5,7肯定
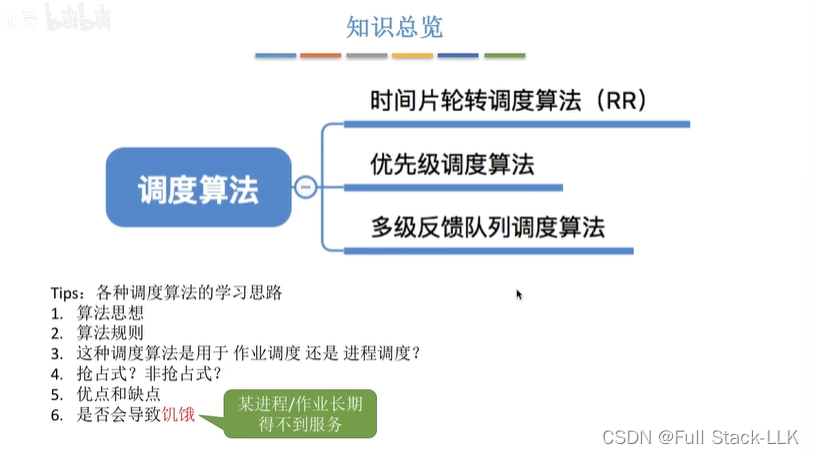
此时第二级队列不为空,P2出队列,运行P2,此时运行一个时间片后,P3进入第一级队列,由于此时第一级队列不为空,此时P2的进程被P1强占,然后P3上处理机。此时第一级队列为空,会给第二级队列分配时间片,第二级队列队头P1出队,此时分配的时间是两个时间片,此时P1的运行时间还没有全部结束,会被放到第三级队列。P0进入第1级队列,第一级队列的时间片大小只有一个时间片大小,P1执行完一个时间片后,此时还
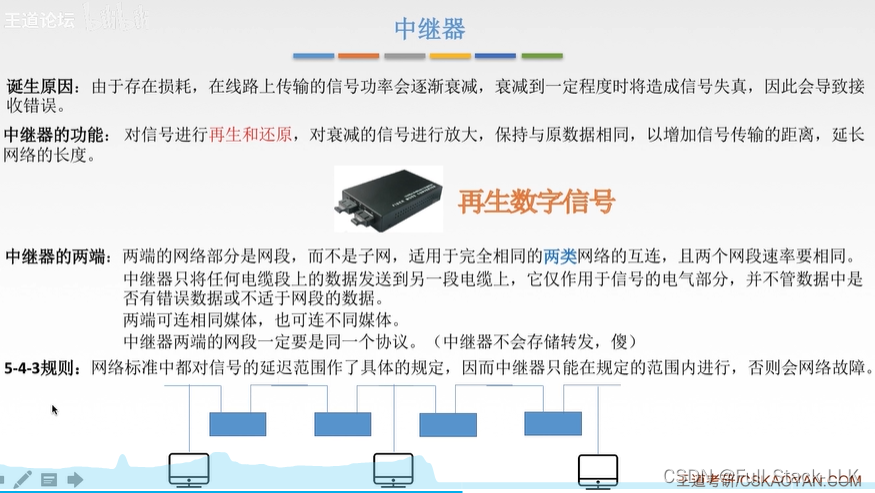
首先,集线器工作在OSI模型的物理层,它的主要功能是对信号进行放大和整形,以延长网络的传输距离。平分带宽:如果一定要同时通信的话,就会使得工作主机平分带宽,即集线器每次广播的带宽大小不变,但是其是由各个工作主机发送的数据组成的。且其各自大小平分带宽。中继器两端的网段必须是同一个协议,这是因为中继器工作在OSI模型的物理层,它的主要功能是放大和整形信号,而不涉及任何高层协议的处理。总的来说,中继器主
宽带信号:基带信号调制后信号频率变高即宽带信号(调制后以放到复杂危险的信道上传输,如声音通过话筒调制发出,声音的频率提高,从而能够应对各种信号的干扰,使得最后接收端能够过滤出开始的基带信号)全零一直翻转,此时接收信号是一直变化的,能区分不同码元所以很好接收,全一一直不变,接收端接收的信号是不变的,不知道接收了多少个码元。每个原始码元被分为两个部分,低电平和高电平两个码元,此时频率增加为原来两倍,对

基于价值迭代的方法只能应用在不连续的、离散的环境下(如围棋或某些游戏领域),对于动作集合规模庞大、动作连续的场景(如机器人控制领域),其很难学习到较好的结果(此时基于策略迭代的方法能够根据设定的策略来选择连续的动作)。策略是其从学到的价值函数里面推算出来的。之前说过Q 函数(Q-Function)表示在状态 s 下采取动作 a 后所能获得的期望累积奖励,也可以理解为当前即使奖励+下一个状态的价值函

在每次互动后,你会更新之前状态下所选择了的行动的Q值,使用一个称为贝尔曼方程的公式。这个公式会考虑之前选择了的行动后的奖励和当前状态的Q值和之前状态的Q值,以更新当前状态下的Q值。这个公式可以简单解释为:当前状态下选择某个行动的Q值等于当前即时奖励加上折扣后的下一状态的最优行动的Q值。在Q学习中,你会记录每个房间的状态、每个行动的奖励以及你对每个行动的期望价值,这个期望价值被称为Q值。当你在迷宫中

项目地址:https://github.com/Narwhal-Lab/MagicSkills很多团队做多 Agent,最先失控的不是模型,而是 skill 管理。同一个 skill 目录,往往既想给 Codex、Cursor、Claude Code 这类 Agent 应用使用,也想给 LangChain、LangGraph 这类框架里创建的多个 agent 使用。