- @leonardotu
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
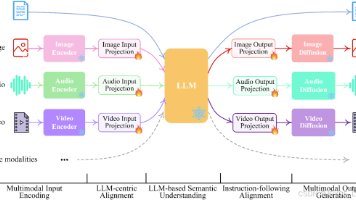
多模态不再局限于单一类型的数据处理,它融合图像、文本和音频等多种信息源。其基础知识涵盖机器学习、深度学习及其在多模态领域的应用。机器学习部分包含分类、回归、聚类和降维等四类算法;深度学习则涉及CNN、RNN和Transformer等多种网络结构;而多模态应用领域则包括计算机视觉、自然语言处理和语音识别等方向。
卷积神经网络(Convolutional Neural Networks,CNN)是深度学习领域中最重要和广泛应用的模型之一。自20世纪80年代提出以来,CNN在图像处理、计算机视觉、自然语言处理等领域取得了显著的成功。本文旨在综述CNN的基本原理、发展历程、主要应用以及未来研究方向,并引用相关文献以支持论述。
可以通过继承 nn.Module 类创建自定义的神经网络层和操作,例如自定义的激活函数、损失函数等。这些功能使得 nn.Module 成为 PyTorch 中构建和组织神经网络的核心工具之一。通过模块化的设计,可以更灵活地搭建、训练和调整复杂的神经网络结构。可以通过继承 torch.optim.Optimizer 类来创建自定义的优化器。# 自定义的优化步骤...优化器是深度学习训练过程中关键的组

深度卷积神经网络(CNN)是一种特殊类型的神经网络,在各种竞赛基准上表现出了当前最优结果。深度 CNN 的超强学习能力主要是通过使用多个非线性特征提取阶段实现的,这些阶段能够从数据中自动学习分层表征。大量数据的可用性和硬件处理单元的改进加速了 CNN 的研究,最近也报道了非常有趣的深度 CNN 架构。近来,深度 CNN 架构在挑战性基准任务比赛中实现的高性能表明,创新的架构理念以及参数优化可以提高

一、优秀的数据预处理;二、合适的模型结构和功能;三、优秀的训练策略和超参数;四、合适的后处理操作;五、严格的结果分析。这几方面都对最终的结果有着举足轻重的影响,这也是目前的数据工程师和学者们的主要工作。但由于这每一方面都十分繁琐,尤其是在构建模型和训练模型上,而大部分情况下,这些工作有无须过深专业知识就能使用起来。所以AutoML主要的作用就是来帮助实现高效的模型构建和超参数调整。例如深度学习网络

训练、验证、测试集在机器学习领域是非常重要的三个内容。三者共同组成了整个项目的性能的上限和走向。训练集:用于模型训练的样本集合,样本占用量是最大的;验证集:用于训练过程中的模型性能评价,跟着性能评价才能更好的调参;测试集:用于最终模型的一次最终评价,直接反应了模型的性能。在划分上,可以分两种情况:1、在样本量有限的情况下,有时候会把验证集和测试集合并。实际中,若划分为三类,那么训练集:验证集:测试

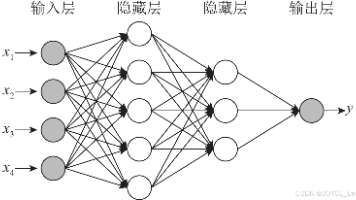
神经网络的层数(深度)是模型复杂性的核心参数,直接影响其表示能力与泛化性能。本文从理论、实验和实际应用角度分析层数与泛化能力的关系,指出层数增加并不影必然导致泛化能力提升,而是需要平衡模型容量、数据规模与正则化策略。通过经典案例与最新研究,揭示深度学习的优化难题与泛化机制,为实践提供指导。
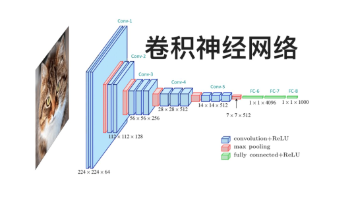
卷积神经网络(Convolutional Neural Network,CNN)是深度学习神经网络经典形式之一,由于其计算过程中包含卷积运算,因此得名。卷积神经网络(CNN)通过使用卷积层来提取图像数据的局部特征,再通过池化层(Pooling Layer)来降低特征的空间维度,最后通过全连接层(Fully Connected Layer)进行分类或回归任务。CNN已经在图像识别、目标检测、图像生成
特征提取是计算机视觉领域经久不衰的研究热点,总的来说,快速、准确、鲁棒的特征点提取是实现上层任务基本要求。特征点是图像中梯度变化较为剧烈的像素,比如:角点、边缘等。FAST(Features from Accelerated Segment Test)是一种高速的角点检测算法;而尺度不变特征变换 SIFT(Scale-invariant feature transform)仍然可能是最著名的传统局

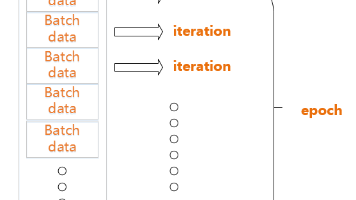
批大小。在深度学习中,一般采用SGD训练,即每次训练在训练集中取batchsize个样本训练。1个iteration等于使用batchsize个样本训练一次。1个epoch等于使用训练集中的全部样本训练一次。训练集有1000个样本,batchsize=10,那么训练完整个样本需要100次iteration,1次epoch。(1)batch数太小,而类别又比较多的时候,可能会导致loss函数震荡而不