- @fenglingguitar
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
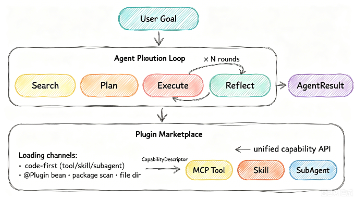
Regnexe 是基于 Spring Boot 的 Java Agent 框架,核心采用 Search→Plan→Execute→Reflect 四步闭环,让 Agent 从"单次答题"升级为"自主完成任务"。与 SDK 不同,它作为 Agent Harness 掌控执行主导权,自动完成能力检索、计划编排、工具调用和结果反思。框架支持多工具注册、Skill 子工作流、Sub-Agent 独立任务、
本文介绍了如何将企业现有的RPC服务快速接入AI Agent系统,重点讲解了j-langchain框架的@AgentTool注解体系。主要内容包括: 背景需求:不改动现有RPC接口,最小化配置即可接入AI Agent,支持Dubbo/Feign等协议统一接入。 参数描述的三种方式: @AgentTool.params内联@ParamDesc(适用于第三方VO) VO字段上的@Param(适用于自有
摘要:j-langchain是一个专为Java开发者设计的AI应用开发框架,无需AI经验即可快速构建基于大模型的问答、RAG知识库等应用。其核心采用链式编排模式,通过Prompt模板、大模型和输出解析器的组合实现功能。框架支持流式输出、JSON结构化返回、事件流调试,并能无缝切换本地模型(如Ollama)。典型用法包括5分钟快速集成、三步构建AI链(Prompt→LLM→Parser)以及实时流式
本文系统对比了四种AI记忆框架:轻量级GraphRAG实现LightRAG、对话记忆中间件Mem0、时态知识图引擎Graphiti和通用AI记忆系统Cognee。LightRAG适合单文档问答,Mem0擅长对话记忆,Graphiti支持时间维度推理,Cognee则提供完整的记忆与知识融合。这些框架展现了AI记忆系统从简单检索向认知增强的演进趋势,未来将融合图结构、语义理解和时间演化能力,构建更智能

本文介绍了如何用Java构建基于ReAct模式的AI Agent。Agent通过循环执行推理(Reasoning)和行动(Acting),能主动调用工具完成任务。文章详细讲解了工具定义、ReAct Prompt模板设计、推理循环构建和工具执行逻辑的实现方法,并提供了完整示例。相比Python的LangChain,j-langchain采用显式构建方式,更透明且易于调试。这种模式适用于需要主动获取信
本文介绍了Java开发者如何通过j-langchain框架实现LLM与TTS(语音合成)的集成。文章首先阐述了语音合成在智能助手、内容播报等场景的必要性,随后详细讲解了核心数据结构TtsCard(同步结果)和TtsCardChunk(流式结果)的设计,支持文字与音频的同步输出。开发者可通过同步调用或流式输出两种方式实现语音合成,并支持豆包(字节跳动)和阿里云两种TTS供应商的无缝切换。最后提供了完
IndexTTS2 是 B 站团队推出的第二代大规模自回归 Text-to-Speech(TTS)模型。功能macOS 支持情况DeepSpeed❌ 完全不支持❌ 没 CUDAGPU(Metal 加速)✔ PyTorch 支持 MetalFP16✔️ 推荐开启WebUI✔ 正常运行模型推理✔ 速度尚可,音质优所以 mac 上跑 IndexTTS2 完全没问题,只要避开 DeepSpeed。AI 数

摘要:本文介绍Java实现AI流式输出的6种方式,适用于实时对话场景。核心包括直接流式调用LLM(llm.stream())、链式流式处理(chainActor.stream())、中断生成(chainActor.stop())、流式JSON解析(JsonOutputParser)以及事件流监控(streamEvent())。重点对比了同步与流式模式的用户体验差异,并提供了Spring Boot集
本文介绍 j-langchain 中 Proposer-Critic 多轮辩论模式:两个纯 LLM Agent 通过 loop() 迭代协作,Proposer 以高 temperature 生成方案,Critic 以低 temperature 严格评审,输出 [APPROVED]/[CRITIQUE] 结构化信号驱动循环,无需任何工具依赖,是"生成-评审-改进"场景最轻量的多 Agent 实现方案
本文介绍了如何使用 McpAgentExecutor 简化 Java 开发中的 MCP 工具调用流程。通过封装 Function Calling 循环逻辑,开发者只需配置模型、工具组和系统提示,即可实现多步推理任务。相比手动实现减少了 80% 代码量,同时提供工具调用和结果回调功能。文章包含最简示例、执行效果展示、参数说明及实用建议,适用于需要将 AI 与企业系统集成的 Java 开发者。相关代码