
写文章




- @am_student
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
神经网络之VGG
经典卷积神经网络的基本组成部分是下面的这个序列:带填充以保持分辨率的卷积层;非线性激活函数,如ReLU;汇聚层,如最大汇聚层。而一个VGG块与之类似,由一系列卷积层组成,后面再加上用于空间下采样的最大汇聚层。在最初的VGG论文中 (),作者使用了带有3×3卷积核、填充为1(保持高度和宽度)的卷积层,和带有2×2汇聚窗口、步幅为2(每个块后的分辨率减半)的最大汇聚层。VGG的全称是视觉几何小组,隶属

ResNet:深度学习中的重要里程碑
首先是什么是残差块:让我们聚焦于神经网络局部:如图所示,假设我们的原始输入为x。左图虚线框中的部分需要直接拟合出该映射f(x),而右图虚线框中的部分则需要拟合出残差映射f(x)−x。残差映射在现实中往往更容易优化。右图是ResNet的基础架构–残差块在残差块中,输入可通过跨层数据线路更快地向前传播。ResNet的核心结构是残差块(residual block),由两个或三个卷积层组成。每个残差块包
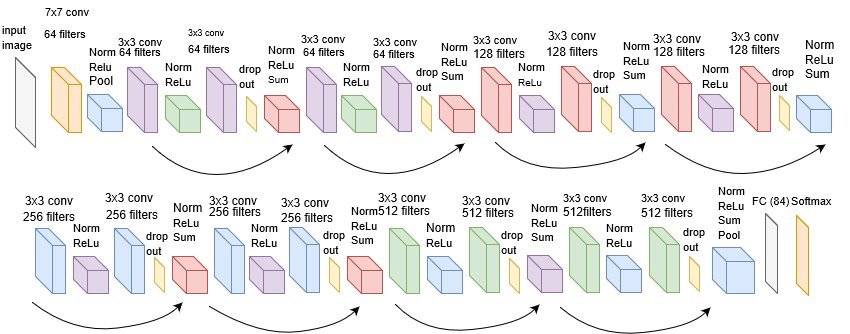

利用百度进行人脸识别
利用百度api进行人脸识别,graphics安装以及百度api的相关操作,判定两张照片是否为同一个人。
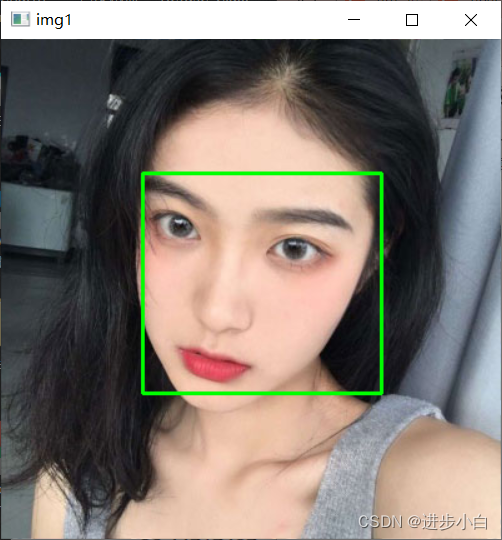
人脸识别-多张人脸检测
人脸识别基础,多张人脸识别检测,但是仅仅现成的模型还是存在很多缺陷。
人脸识别-对数据的训练
人脸识别中的数据处理部分,怎么去训练数据。

人脸识别-对数据的训练
人脸识别中的数据处理部分,怎么去训练数据。
人脸识别-在视频中识别人脸
在视频中进行人脸识别,并标识出来,并输出每一帧。

利用百度进行人脸识别
利用百度api进行人脸识别,graphics安装以及百度api的相关操作,判定两张照片是否为同一个人。