




- @Wang_Dou_Dou_
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
关键字:安装MySQL、卸载MySQL、测试MySQL。

关键词:A Simple Framework for Contrastive Learning of Visual Representations 文献研究。

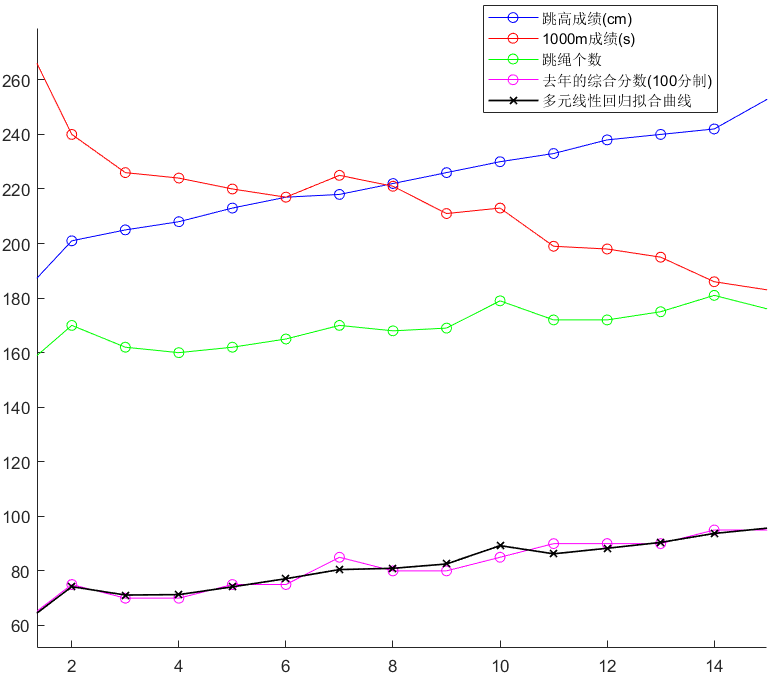
本文旨在能快速地用 matlab 实现基于多元线性回归拟合/分析。小编已将代码都封装好了。在分析样例的同时,也简单地讲解了其原理和相关参数。该系列文章是个人在参加2021年暑假国赛数模的培训,自己记录的心得与体会,意在总结归纳自己的学习成果,也希望能帮助想在数模比赛中施展身手的志同道合者。...
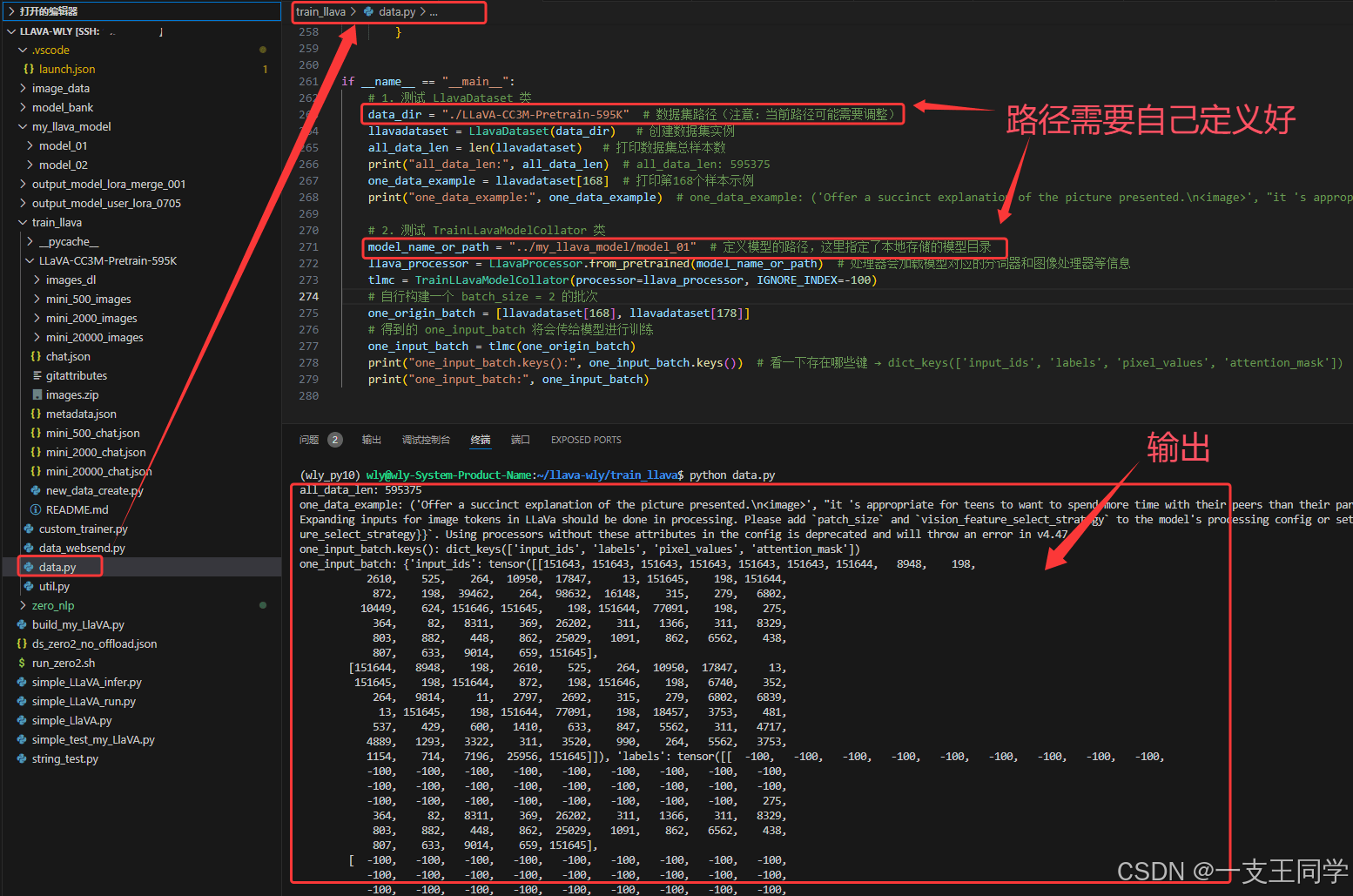
整体文章脉络如下:下载数据集、数据集的读取、辅助工具函数、模型的训练6 轻量数据集的微调训练、加载训练好的模型来推理。
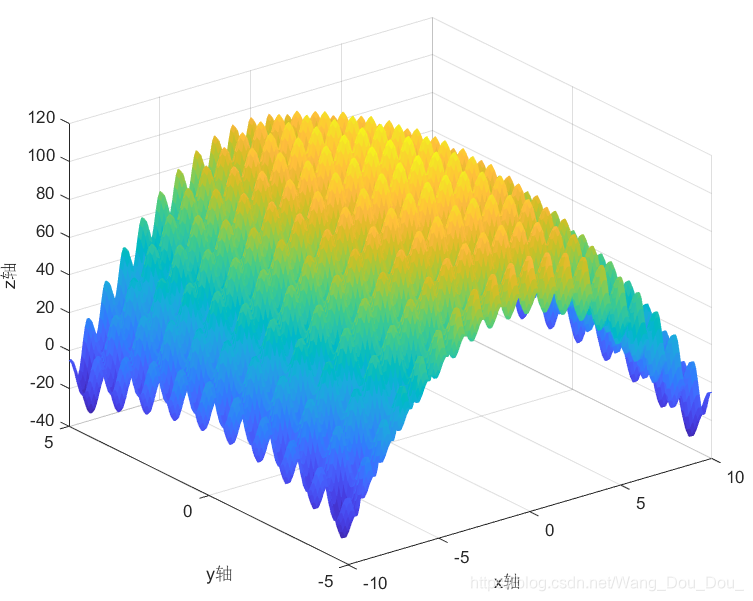
关键字:粒子群优化算法PSO、智能算法、随机搜索、matlab、数学建模
关键字:如何租用云服务器、如何租用网上的GPU、如何把代码上传到云服务器、如何把数据集上传到云服务器、如何在云服务器上训练ResNet50。

这篇文章概述了Deepseek 及其变体,包括 DeepSeek 7B、DeepSeek MoE-16B、DeepSeek V2、DeepSeek V3、DeepSeek R1-Zero 和 DeepSeek R1,还概述了相关的大语言模型,包括 OpenAI GPT、Claude 3.5、LLama 3.1、Qwen 2.5、Gemini 2.0,并将它们进行了系统的比较。

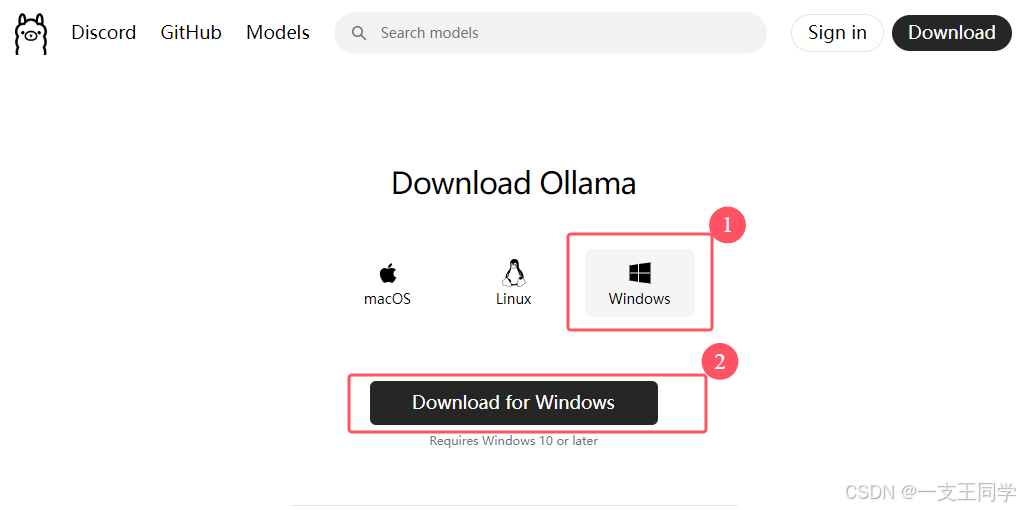
超级简单的傻瓜式部署贴子,包括 Ollama、DeekSeek、Cherry Studio 的下载和安装,并有详细的步骤。
该文分享了如何对中英文问答题进行数据增强的方法【数据预处理工作】,提升了LLMs的推理能力,模型使用的是Llama3-8B。
本文首先介绍了AuroraCap,一种基于大型多模态模型的高效视频细节描述器。通过利用tokens合并策略,在不影响性能的情况下显著降低了计算开销。本文还提出了VDC,一个新的视频详细描述基准,旨在评估视频内容的全面和连贯的文本描述。为了更好地评估,本文提出VDCscore,一种新的基于分而治之策略的LLMs辅助评价指标。对各种视频和图像描述基准的广泛评估表明,AuroraCap取得了有竞争力的结
