- @Rikki1013
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
项目的第一部分是基础与概念题,10道题覆盖了Pandas核心知识:两大数据结构Series和DataFrame的区别与应用场景。如何读取CSV、Excel(含多sheet)文件,解决编码问题。数据探索常用方法head()、info()、describe()的使用技巧。时间类型转换及时间特征提取方法。缺失值检测与处理(删除、填充、插值、KNN补全等)。每道题不仅有直接答案,还有详细解释+代码示例+业

盘古大模型相关部门的撤销,意味着组织战略的调整,但并不代表科研成果的消失。以盘古气象大模型为例,它已经开源,任何人都可以基于它展开研究与实践。和鲸社区创作者 @lqy 的项目,则让我们有机会在真实环境中体验它的能力。这也说明了——组织可能会被裁撤整合,但技术将在科研实践与分享中无限延续。
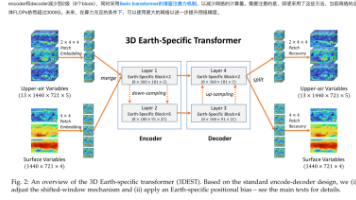
人工智能领域,被许多学习者视为“大模型学习的必修课”,不仅因为课程本身由一流学者讲授,更因为它以为主线,让学习者真正看清楚大模型的底层运作机制。:课程作业要求从零实现完整的模型组件,对基础和细节的掌握缺一不可;:公开的讲义和参考代码碎片化严重,缺乏连贯的学习路径;:很多人被运行环境和训练成本卡住。也正因如此,不少学习者虽然知道CS336的价值,但很难坚持学完。为了解决这些痛点,把课程作业完整地实现

项目的第一部分是基础与概念题,10道题覆盖了Pandas核心知识:两大数据结构Series和DataFrame的区别与应用场景。如何读取CSV、Excel(含多sheet)文件,解决编码问题。数据探索常用方法head()、info()、describe()的使用技巧。时间类型转换及时间特征提取方法。缺失值检测与处理(删除、填充、插值、KNN补全等)。每道题不仅有直接答案,还有详细解释+代码示例+业
秋招面试季,简历上没有拿得出手的项目?面试官问“有没有数据建模经验”,你却只能含糊回答“做过一些课内实验”?看到竞争者展示完整的项目经历、甚至科研成果时,你是不是有点心慌?别急,机会就在眼前——正式开启!这是一场完全免费的线上实战活动,帮你补上简历的“项目经验空白”!

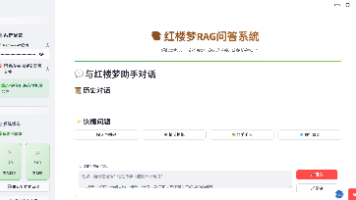
在和鲸社区,创作者 @Blues 分享了一个极具想象力的项目《红楼梦RAG问答系统》。它不是简单的代码演示,而是一次“传统文化 × 人工智能”的结合实践:通过检索增强生成(RAG)技术,这个系统能像一位《红楼梦》研究专家一样,回答你提出的问题。无论是人物关系、情节梳理,还是书中的细节描写,都能即时生成答案。💻系统预览体验地址:https://readrag.streamlit.app/红楼梦ra
临床科研的第一步,常常也是最难的一步。选题、变量、结局、分析流程……每一个环节都需要严谨的设计。课程中,利用AI工具使用的“支点”原则,你只需提供一篇范文、一份规范文档(如STROBE),AI即可生成结构清晰、逻辑完整的设计方案。为了便于理解,课程“以脑中风相关风险因素识别为例”详细展示了利用豆包从前期准备材料、数据清洗到绘制箱线图(探索性分析)、实现t检验、估算样本量、构建模型筛选变量、生成临床

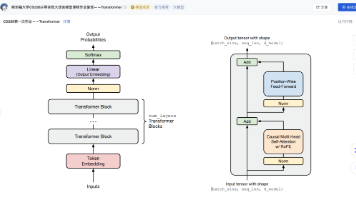
Transformer自2017年提出后,已经成为大语言模型(LLM)的基石。如今GPT、LLaMA、Qwen等主流模型,都在这一架构上不断演化。和鲸社区复现的斯坦福CS336课程作业一中的第三部分就要求从零实现Transformer语言模型,相比直接调用高层API,从零实现能够让学习者真正理解:token如何被嵌入为向量;自注意力如何捕捉上下文依赖;为什么需要位置编码、归一化和残差连接;现代LL
大模型案例教程征稿

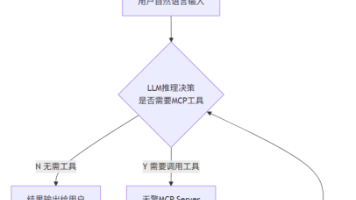
通过MCP+LLM,搭建AI智能体,解决天擎数据查询难问题