- @Python_paipai
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
大语言模型是自然语言处理(NLP)领域中使用的一种技术,它们通过训练大量文本数据,从而学会理解和生成人类语言。这些模型通常采用深度学习方法,其中最常用的是变形金刚(Transformer)机器学习框架。在机器学习领域,有很多种技术框架可以用来构建和训练这些大语言模型。选择哪个框架通常取决于个人偏好、项目需求以及团队的熟悉程度。每个框架都有其优点和适用场景。一、常用的机器学习框架在人工智能和机器学习

点击上方蓝字关注我们科技发展促进了人工智能技术,改善了我们的生活。AI开发平台为开发者提供工具和资源,激发创新,助力智能应用实现。这些平台作为技术和创意的桥梁,帮助开发者克服挑战,实现智能梦想。AI平台充满潜力,期待开发者挖掘,共同塑造AI未来。它们是智慧源泉,提供破解AI奥秘的工具,开启新领域大门。技术与灵感在此交融,推动社会进步。01/智谱清流1是领先的智能体开发平台,利用大模型技术快速构建与
你知道的数据标注都有哪些?数据标注(Data Annotations)是指对收集到的、未处理的原始数据或初级数据,包括语音、图片、文本、视频等类型的数据进行加工处理,并转换为机器可识别信息的过程。矩形框标注是一种的简单处理方式,常用于等。多边形标注是指在静态图片中,使用多边形框,标注出不规则的目标物体,相对于矩形框标注,**多边形标注能够更精准地框定目标,**同时对于不规则物体,也更具针对性。语义

而他们的底座就是大模型(Large Models),大模型在人工智能领域通常指的是具有大量参数的(通常包含十亿甚至千亿参数)、复杂计算结构和强泛化能力的机器学习模型。其主要特点包括:大量参数:大模型拥有庞大的参数量,通常包含十亿甚至千亿参数,远超过传统的小型模型。使其具备极高的表达能力,能够模拟和学习非常复杂的函数关系。强大的学习能力:由于参数量巨大,这些模型具有强大的学习和泛化能力,能够在各种任
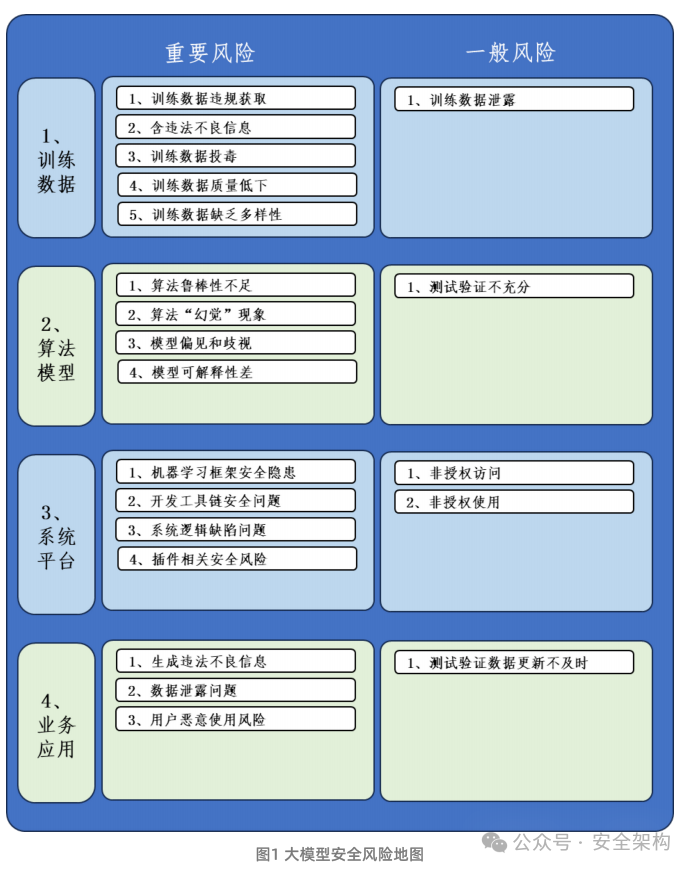
与此同时,参考 ISO/IEC 5338-2023 《人工智能系统生命周期过程》国际标准,将基础大模型系统抽象为训练数据、算法模型、系统平台和业务应用四个重要组成部分,并通过描绘这四个组成部分面临的重要和一般安全风险,形成大模型安全风险地图,其中,重要风险是发生概率高和影响程度大的风险,一般风险则反之。二是攻击者画像方面。内容概要:包括 内网、操作系统、协议、渗透测试、安服、漏洞、注入、XSS、C
一、大模型的组成部分大模型通常指规模巨大、参数数量众多的机器学习模型,尤其在深度学习领域,这种模型一般由以下几个关键部分组成:1.神经网络架构:大模型的基础是复杂且多层次的神经网络架构,如深度前馈神经网络(包括但不限于卷积神经网络CNN、循环神经网络RNN、Transformer等)。2.海量参数:参数规模是衡量模型“大小”的关键指标,大模型往往拥有数百万甚至数十亿级别的参数。这些参数包括各个神经
在人工智能的浩瀚星辰中,大模型犹如璀璨的北极星,引领着技术的前沿方向。它们不仅代表了深度学习领域的最新突破,更成为了推动各行各业智能化转型的关键力量。本文笔者总结了大模型从理论研究到实战落地所需具备的所有知识干货,与大家分享~

大模型是指具有数千万甚至数亿参数的深度学习模型。近年来,随着计算机技术和大数据的快速发展,深度学习在各个领域取得了显著的成果,如自然语言处理,图片生成,工业数字化等。为了提高模型的性能,研究者们不断尝试增加模型的参数数量,从而诞生了大模型这一概念。本文讨论的大模型将以平时指向比较多的大语言模型为例来进行相关介绍。
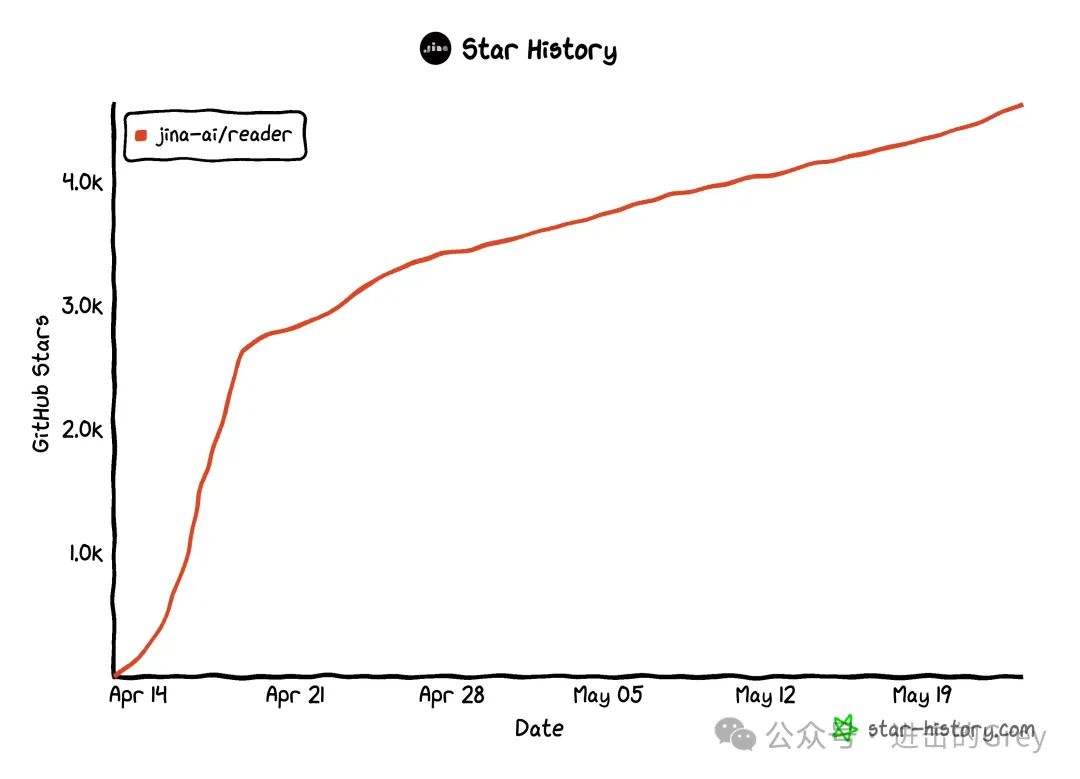
简单地说,网络爬虫就是从网站上抓取数据和内容,然后以 XML、Excel 或 SQL 的形式保存数据。除了潜在客户挖掘、竞争对手监控和市场调研之外,网络爬虫工具还可用于实现数据收集过程的自动化。在人工智能网络爬虫工具的帮助下,可以解决手动或纯粹基于代码的爬虫工具的局限性:动态或非结构化网站现在也可以轻松处理,都无需人工干预。在此,我们将介绍几款开源 AI 网络爬虫工具供您选择。
当前AI领域正在经历一个关键的转折点:从"能说会道"走向"能做善成"。AI Agent的出现和发展,代表了人工智能从"纸上谈兵"到真正解决实际问题的重要跨越。技术层面的机遇将强大的语言理解能力转化为实际的执行能力通过工具集成实现AI能力的无限扩展打造真正能够帮助人类的智能助手降低AI应用的开发门槛应用领域的机遇个人助理:帮助处理日常任务、信息整理、日程管理企业自动化:流程处理、数据分析、客户服务研