- @Isabella_leeo
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
文章摘要: 本文介绍了使用MinerU API将PDF文档批量转换为机器可读格式(如Markdown、JSON)的方法。MinerU是OpenDataLab推出的大模型工具,支持精准解析和轻量解析两种API模式。作者详细演示了从注册API、获取Token到编写Python脚本调用接口的全流程,包括环境配置、PDF文件校验及批量处理限制(如200MB/文件、200页/PDF)。文中提供了完整的代码示
《大数据平台架构》第六章深入解析了分布式数据库HBase的核心特性与应用场景。作为Google BigTable的开源实现,HBase具有PB级存储、稀疏性、多版本等优势,但存在不支持复杂聚合、无二级索引等局限。其四维数据模型(RowKey/列族/列限定符/时间戳)和列式存储机制实现了高效查询。HBase采用主从架构,依赖ZooKeeper实现高可用,通过LSM树将随机写转为顺序写,MemStor
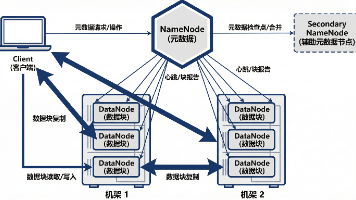
Hadoop 分布式文件系统(HDFS)是 Google File System (GFS) 的开源实现,旨在解决单机文件系统在容量和吞吐量上的物理瓶颈。其核心设计理念是在廉价的商用硬件(Commodity Hardware)上构建高容错系统。
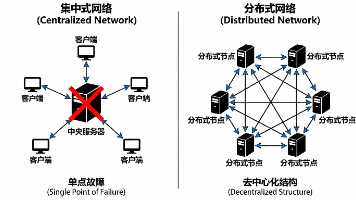
计算机系统的演进史,本质上是算力需求与物理极限博弈的历史。在早期,数据处理主要依赖于集中式系统,即所有的硬件、软件及业务逻辑都高度集中在单一的中央服务器上。这种架构的优势在于设计简单、数据天然一致。然而,随着互联网数据的爆炸式增长,集中式系统遭遇了难以逾越的瓶颈:1.扩展性瓶颈:垂直扩展的边际成本呈指数级上升。2.单点:故障中央节点的瘫痪意味着整个服务的彻底中断。为了解决这一问题,分布式系统应运而
报错原因,在线安装器需要从sourceforge上面下载文件,但是网络不稳定,99%都会报错。把软件安装在D盘,此时路径为:D:\Program Files\mingw-w64\x86_64-8.1.0-win32-seh-rt_v6-rev0。点击 文件-首选项-设置,进入设置页面后依次选择如下,把运行在终端,运行前保存所有文件,运行前保存当前文件,三个选项勾选。4.2 先用快捷键ctrl+sh

提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档。
本文介绍了如何使用Git管理科研项目,重点讲解如何将本地项目托管到GitHub私有仓库。首先在GitHub创建空仓库,然后通过git init初始化本地项目,配置.gitignore文件排除非代码文件。接着添加文件、提交更改,并将分支重命名为main后推送到远程仓库。文章还提供了日常维护的常用命令,包括查看状态、暂存修改、提交版本和同步远程仓库等操作。最后提醒谨慎使用git checkout .回
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档。
近日,我有幸深入学习了国防科技大学吕欣教授及其团队所著的《数据挖掘》一书,深受启发,收获颇丰。这本书系统性地介绍了数据挖掘的核心理论与经典算法,内容既涵盖基础概念,又深入实战技巧,尤其适合机器学习、数据科学领域的初学者和进阶者阅读。吕欣教授及其团队以其深厚的学术功底和丰富的实践经验,将复杂的数据挖掘知识讲解得条理清晰、通俗易懂。书中不仅有严谨的数学推导,还配有丰富的案例和代码实现,真正做到了理论与
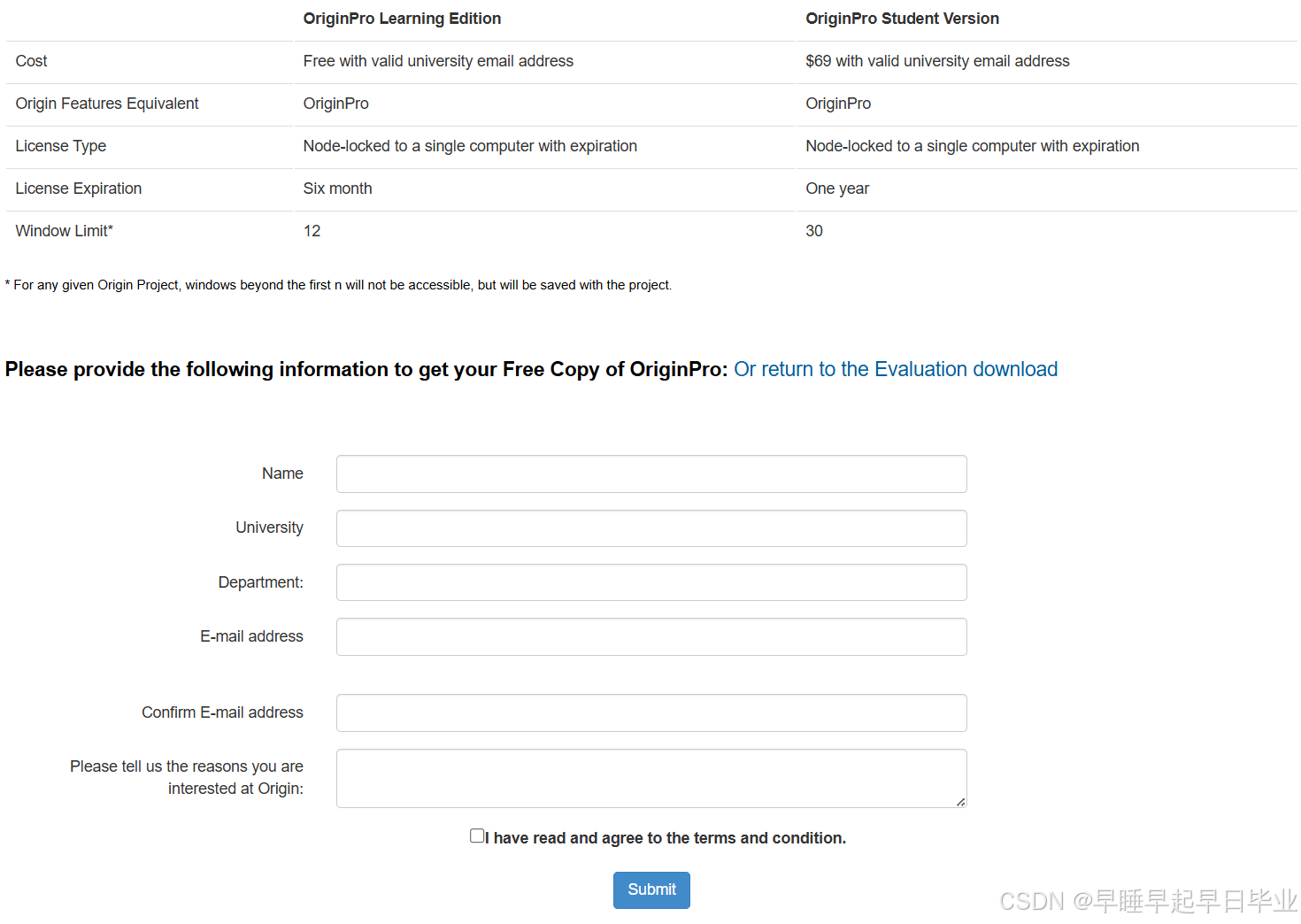
OriginLab学生版过期后,重新激活