- @FontThrone
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在训练神经网络的过程中需要用到很多的工具,最重要的是数据处理、可视化和GPU加速。本章主要介绍PyTorch在这些方面常用的工具模块,合理使用这些工具可以极大地提高编程效率。由于内容较多,本文分成了五篇文章(1)数据处理(2)预训练模型(3)TensorBoard(4)Visdom(5)CUDA与小结。1 数据处理2 预训练模型3 可视化工具3.2 Visdom4 使用GPU加速:CUDA5 小结
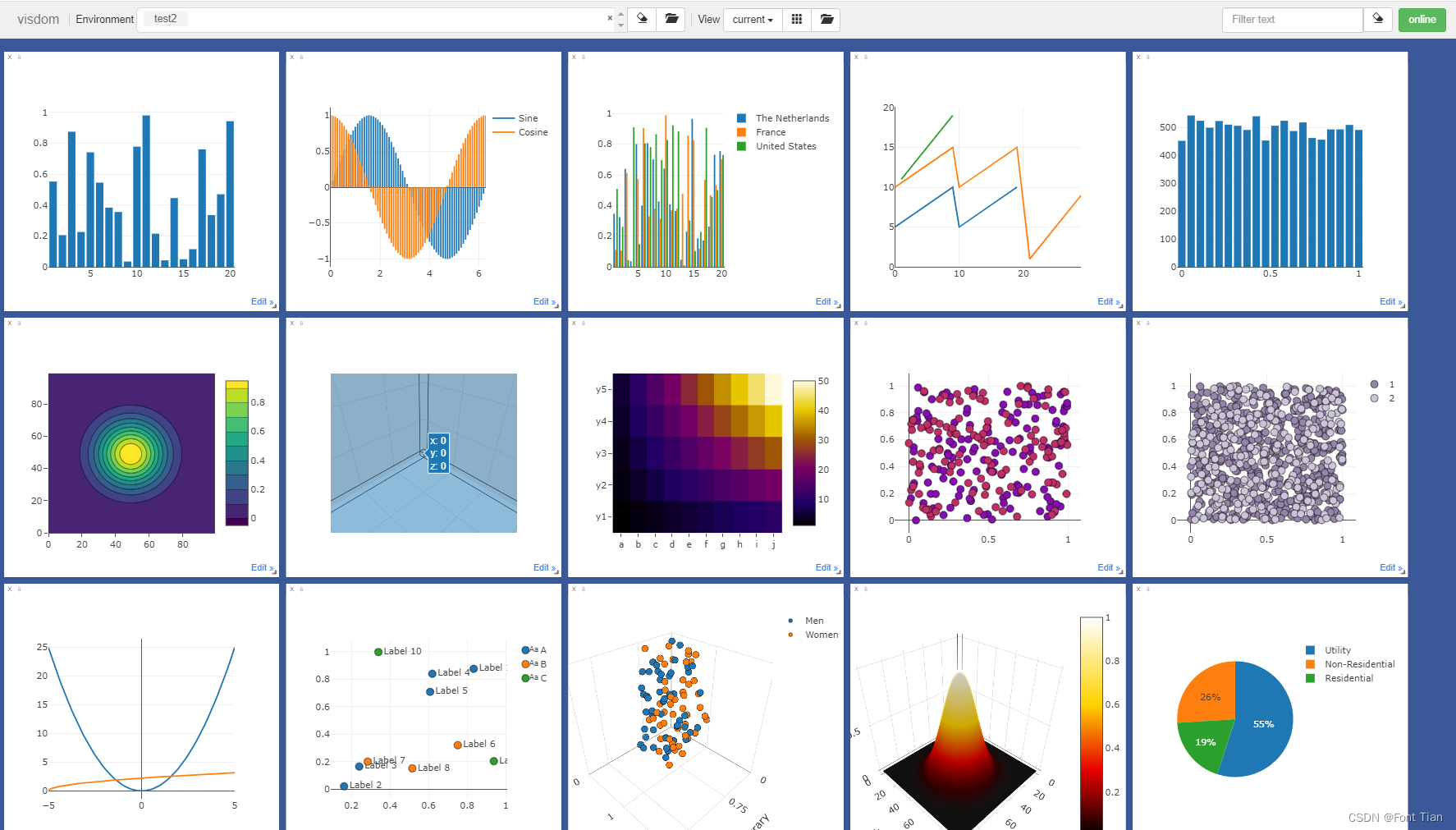
在训练神经网络的过程中需要用到很多的工具,最重要的是数据处理、可视化和GPU加速。本章主要介绍PyTorch在这些方面常用的工具模块,合理使用这些工具可以极大地提高编程效率。由于内容较多,本文分成了五篇文章(1)数据处理(2)预训练模型(3)TensorBoard(4)Visdom(5)CUDA与小结。1 数据处理2 预训练模型3 可视化工具3.2 Visdom4 使用GPU加速:CUDA5 小结
人工智能 (AI) 模型的数据泄露问题指的是模型训练过程中,训练数据的信息被泄露到模型输出中,导致模型对未见过的数据产生偏差或错误预测。

Ollama 简明使用指南 核心功能: 基础命令:run/pull/list/rm 管理模型 常用模型:llama3/deepseek-coder/qwen等 交互命令:/set//clear//bye调整会话 支持自定义模型和API调用(默认端口11434) 使用注意: 首次运行自动下载模型(2-4GB) Windows需管理员权限 可修改存储路径和环境变量 包含模型管理、交互控制、API调用和
2025年云计算技术进入理性发展阶段,行业呈现三大趋势:Kubernetes回归调度本质,OpenStack聚焦特定场景,虚拟化重获价值认可。技术发展不再追求"统一云"的宏大叙事,而是强调清晰的边界划分和务实定位。成本约束、安全合规和AI需求重塑了技术优先级,财务模型和运维可控性取代了早期的技术理想主义。这一年云计算行业集体降速,从追求技术先进性转向注重工程实用性,展现出成熟领

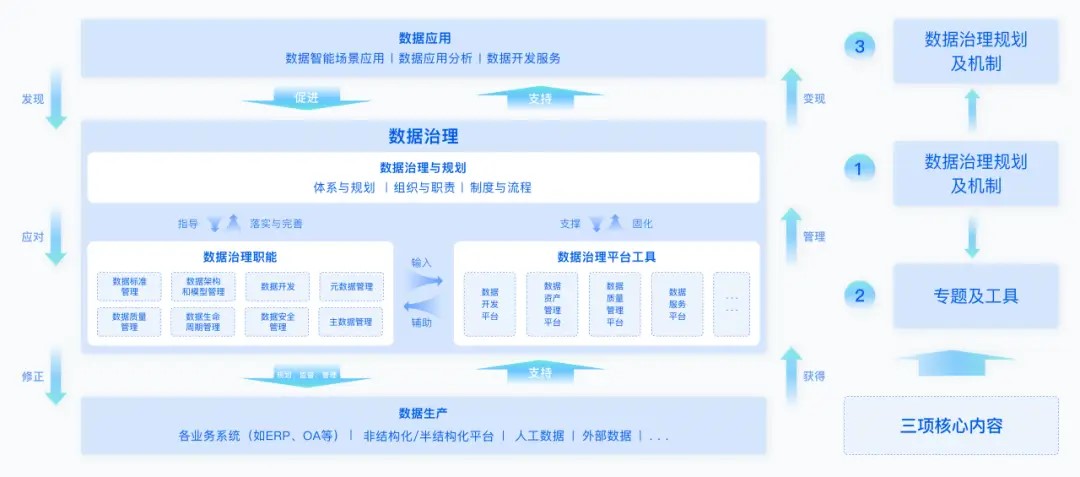
随着数据时代的到来,数据治理、数据素养和数据质量管理成为组织数据管理中的三大核心概念。本文基于相关研究与实践,对这三个领域进行全面综述,探讨它们的定义、相互关系及其在数据中台与AI数据服务中的体现。通过结合中国互联网企业的实践,提出数据中台作为现代数据治理的重要工具,其在数据治理、数据挖掘及智能化应用方面的优势。
Docker 是一个开源的应用容器引擎,容器不同于虚拟机,更简单的架构使其无需创建臃肿的操作系统就能够创建一个隔离的应用环境。利用Docker我们也就可以快速的部署各类服务,而无需复杂的安装过程。

译者注内容有部分增加与补充,阅读原文请点击这里原作者的文章其实更利于读者对卷积本身的理解,但是实际上作者对卷积的现实意义的理解并没有解释的十分清楚,甚至可能不利于堵着的理解,也正因为如此我在翻译过程中可能对原文进行了比较大的改动,希望这对你有帮助.实际上上卷积神经网络是来自神经学的研究,其计算过程实际上模拟了视觉神经系统的运算过程.这一部分内容其翻阅其他文章....
本文详细对比了7款热门AI工具在开源协议、商用许可、专利申请、二次开发与AI适配性及国际化支持等多维度的信息。文章深入解析了Dify、FastGPT、Langflow、Rasa、PySpur、Flowise和LangChain等工具的核心能力及适用场景,从企业级中台建设到低代码原型开发,为技术团队和企业决策者提供了清晰的参考。选型建议涵盖复杂对话系统、多模态代理及高精度文档解析等应用场景,旨在帮助
自动化机器学习就是能够自动建立机器学习模型的方法,其主要包含三个方面:方面一,超参数优化;方面二,自动特征工程与机器学习算法自动选择;方面三,神经网络结构搜索。本文侧重于方面三,神级网络结构搜索。自动化机器学习的前两个部分,都有一个特点——只对现在已有的算法进行搜索,而不创造新的算法。一般而言机器学习专家在开发机器学习应用或者构建机器学习模型时,都不太可能从头造轮子,直接创造一个新的算法。但是到了