




- @Bit_Coders
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
解决Xinference由于第三方版本兼容性引起的报错。
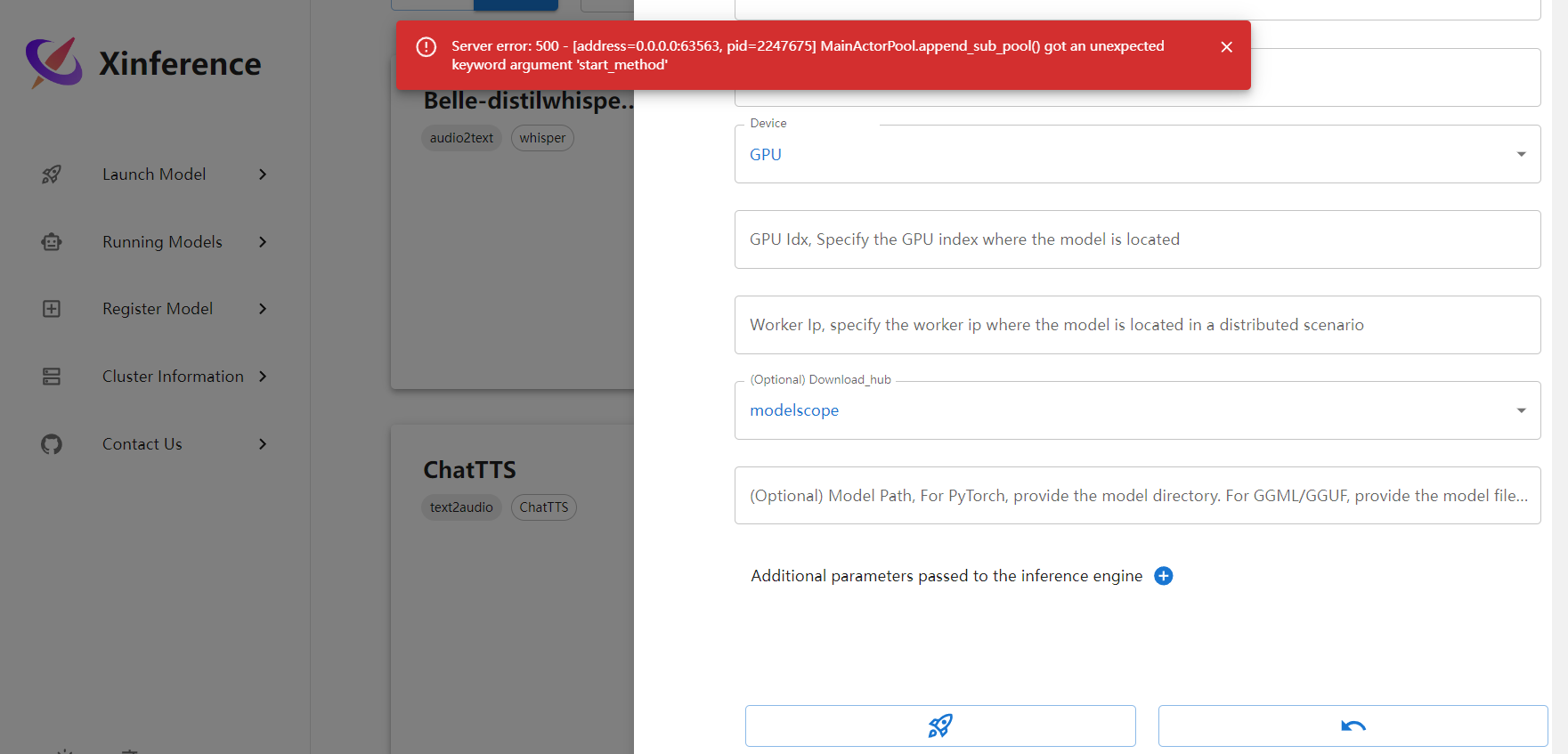
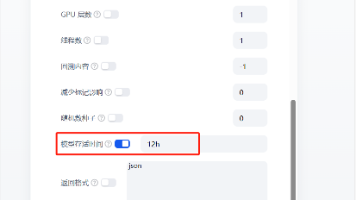
解决 ollama 模型隔一段时间就被释放的问题。
整理下NVIDIA官方文档中列的CUDA常见错误类型。错误类型说明cudaSuccess = 0API调用返回没有错误。对于查询调用,这还意味着要查询的操作已完成(请参阅cudaEventQuery()和cudaStreamQuery())。cudaErrorInvalidValue = 1这表明传递给API调用的一个或多个参数不在可接受的值范围内。cudaErrorMemoryAllocatio
【转】机器学习核心概念完全解析(建议收藏)原文链接:https://mp.weixin.qq.com/s/wEpmF1gdvsIimnvXrxKdRwAI干货知识库刚接触机器学习框架 TensorFlow 的新手们,这篇由 Google 官方出品的常用术语词汇表,一定是你必不可少的入门资料!本术语表列出了基本的机器学习术语和 TensorFlow 专用术语的定义,希望能帮助您快速熟悉 Tensor
基于colormap提取rgb颜色列表、十六进制颜色码组合

文章目录引言卷积核可视化权重和激活可视化小结引言本文整理了卷积神经网络训练过程中的可视化,便于对训练过程进行分析和检查。有需要的朋友可以马住收藏。卷积核可视化以下代码参考1:# 可视化卷积核#in model.named_parameters():if 'conv' in name and 'weight' in name:in_channels = param.size()[1]out_chan
图像矩通常用于分析、描述分割后的形状。

如果要在每个平台上实现所有模型的框架,会极大增加环境的复杂性,优化不同框架和硬件的所有组合非常耗时。
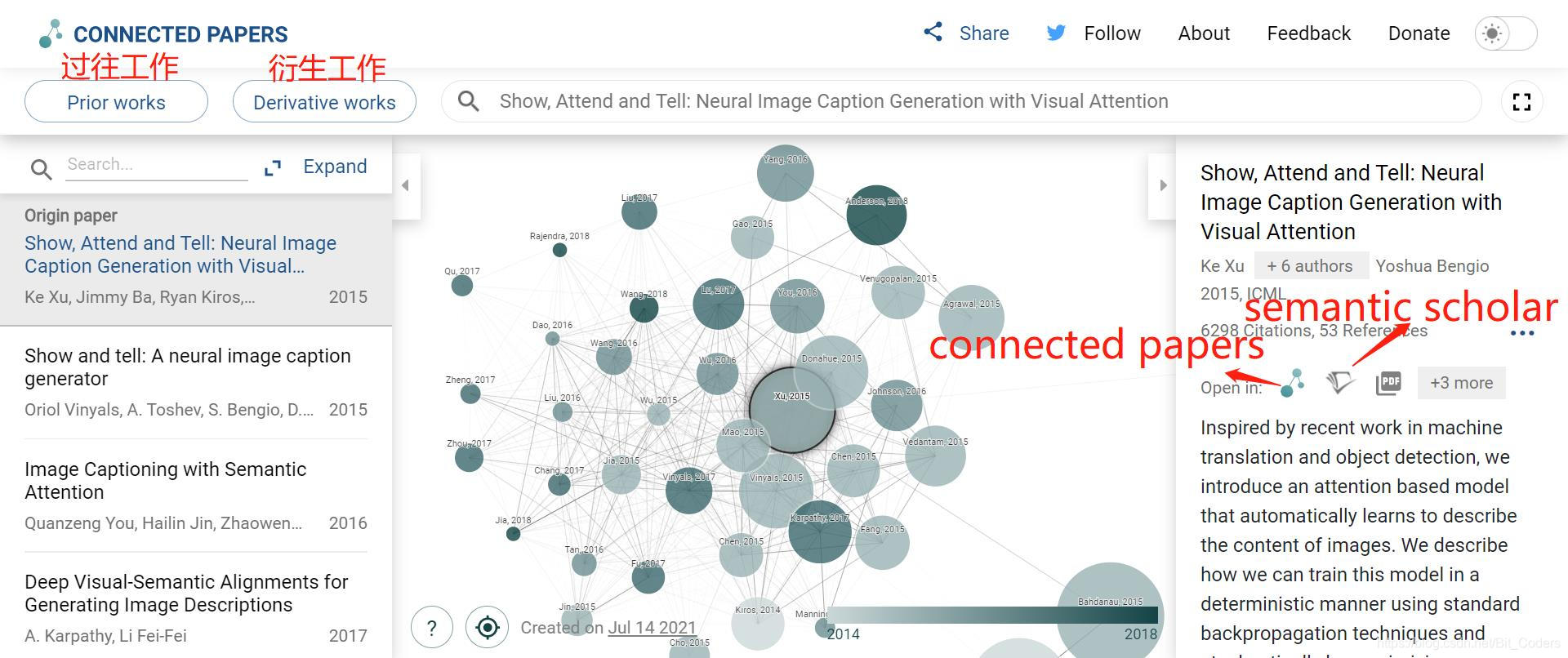
一分钟帮你理清文献脉络:关联文章、历时重要文献、最新文献追踪。
- ASCII简单的7位编码适用于以英语为主的国家。- Unicode是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案。- UTF-8是一种常见的基于Unicode字符集的编码方式。- GB2312是面向简体中文,BIG5是面向繁体中文。- Unicode还在其发展期,Unicode、GB2312以及BIG5等多种编码共存的状况可能在以后较长的时间内都会持续下去。