- @Aision_tean
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
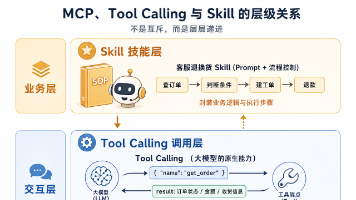
在实际搭建客服系统时,我会先用 MCP 封装订单查询、工单创建、退款等外部能力,再在上层构建 Skill,最后让 LLM 通过工具调用或直接触发 Skill 来完成用户的退换货、咨询等指令。整个架构会清晰很多。模型本身只会生成文本,但我们可以让它输出一种特殊格式的指令,告诉宿主程序:“我想调用这个函数,参数是这些”。到这里,我对 MCP 的理解就一句话:MCP 是一套标准协议,让工具可以被统一发现
AI供应链污染:新型攻击威胁AI生态安全 恶意攻击者正利用AI生态的信任机制发起供应链攻击,通过篡改模型文件、数据集和MCP服务器植入恶意代码。典型手法包括:利用PyTorch的pickle反序列化漏洞在模型加载时执行恶意代码;污染训练数据诱导模型生成后门逻辑;伪装MCP插件窃取AI代理的上下文权限。由于AI社区缺乏安全规范,开发者常盲目信任高分模型或热门工具,导致攻击面扩大。防御建议包括使用Sa

AI供应链污染:新型攻击威胁AI生态安全 恶意攻击者正利用AI生态的信任机制发起供应链攻击,通过篡改模型文件、数据集和MCP服务器植入恶意代码。典型手法包括:利用PyTorch的pickle反序列化漏洞在模型加载时执行恶意代码;污染训练数据诱导模型生成后门逻辑;伪装MCP插件窃取AI代理的上下文权限。由于AI社区缺乏安全规范,开发者常盲目信任高分模型或热门工具,导致攻击面扩大。防御建议包括使用Sa
AI供应链污染:新型攻击威胁AI生态安全 恶意攻击者正利用AI生态的信任机制发起供应链攻击,通过篡改模型文件、数据集和MCP服务器植入恶意代码。典型手法包括:利用PyTorch的pickle反序列化漏洞在模型加载时执行恶意代码;污染训练数据诱导模型生成后门逻辑;伪装MCP插件窃取AI代理的上下文权限。由于AI社区缺乏安全规范,开发者常盲目信任高分模型或热门工具,导致攻击面扩大。防御建议包括使用Sa
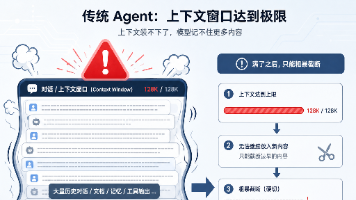
AI安全威胁升级:提示词注入攻击从"诱导输出"演变为"远程代码执行"。最新案例显示,攻击者通过GitHub Issue劫持AI机器人执行恶意代码,影响500万开发者。研究发现三种新型攻击方式:1)网页隐藏指令注入;2)利用AI代理权限执行危险命令;3)绕过人工确认机制。这些攻击的危险性在于,当AI具备行动能力后,提示词注入可导致密钥窃取、恶意软件安装等严重后果。防御建议包括实施最小权限原则、隔离输
本文介绍了数据库的基本概念和主要类型。数据库是组织化的数据集合,通过数据库管理系统(DBMS)和SQL语言进行操作管理。数据库主要分为五种类型:层次型(树状结构)、网状型(多父节点)、关系型(表格形式)、面向对象型(基于对象)和NoSQL型(非关系型)。其中关系型数据库如MySQL、Oracle等应用最广泛。MySQL作为开源关系型数据库,具有高性能、高可靠性等特点,广泛应用于企业数据管理、Web

OpenClaw与Hermes Agent记忆系统对比分析 OpenClaw采用仿生学设计,通过文件系统构建多层记忆结构:长期记忆(MEMORY.md)、每日工作笔记和梦境日记(DREAMS.md),利用"做梦机制"自动筛选重要信息。其特点是空间扩张型设计,鼓励详细记录但可能臃肿。 Hermes则采用极简设计,仅维护两个核心文件(MEMORY.md和USER.md)
在实际搭建客服系统时,我会先用 MCP 封装订单查询、工单创建、退款等外部能力,再在上层构建 Skill,最后让 LLM 通过工具调用或直接触发 Skill 来完成用户的退换货、咨询等指令。整个架构会清晰很多。模型本身只会生成文本,但我们可以让它输出一种特殊格式的指令,告诉宿主程序:“我想调用这个函数,参数是这些”。到这里,我对 MCP 的理解就一句话:MCP 是一套标准协议,让工具可以被统一发现
在实际搭建客服系统时,我会先用 MCP 封装订单查询、工单创建、退款等外部能力,再在上层构建 Skill,最后让 LLM 通过工具调用或直接触发 Skill 来完成用户的退换货、咨询等指令。整个架构会清晰很多。模型本身只会生成文本,但我们可以让它输出一种特殊格式的指令,告诉宿主程序:“我想调用这个函数,参数是这些”。到这里,我对 MCP 的理解就一句话:MCP 是一套标准协议,让工具可以被统一发现
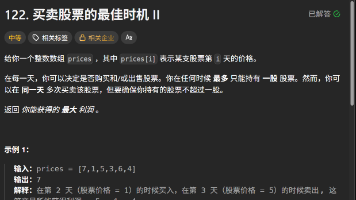
这篇文章讲解了LeetCode第122题"买卖股票的最佳时机II"的两种解法。题目允许无限次买卖股票,但同一时间只能持有一股。核心解法包括:1)贪心算法,通过收集所有上涨日期的差价来获取最大利润;2)动态规划,通过定义持有和不持有股票两种状态,修改买入时的本金计算方式,将单次交易模型扩展为多次交易。两种方法都能高效解决问题,其中动态规划展现了更强的扩展性,为后续更复杂的股票交易