- @2501_93625077
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
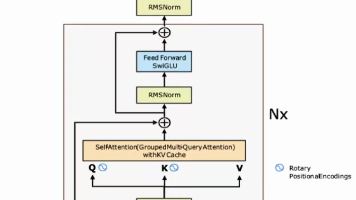
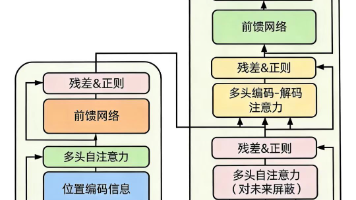
本文介绍了PyTorch中nn.Transformer模块的实现与应用。nn.Transformer包含编码器(TransformerEncoder)、解码器(TransformerDecoder)及多层注意力机制组件,适用于序列任务。文章详细解析了各核心模块的功能,包括多头注意力机制(MultiheadAttention)和层归一化等。通过代码示例展示了如何快速创建标准Transformer模型
本文介绍了一个基于FastAPI和H5的AI智能脑机接口数据分析平台。系统采用前后端分离架构,后端使用FastAPI构建服务,前端采用原生HTML/CSS/JavaScript开发,实现EEG(脑电波)和HRV(心率变异性)数据的上传、分析、AI解读及报告生成功能。平台包含五大核心模块:基础配置、EEG/HRV业务处理、AI调用、联合分析和报告生成,通过异步处理优化性能。前端提供文件上传、功能选择
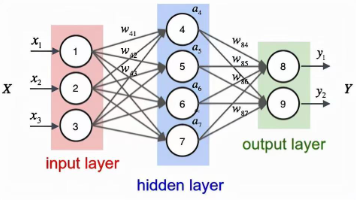
本文介绍了PyTorch中构建神经网络的核心组件和使用方法。主要内容包括:1) torch.nn模块的核心组件(层、损失函数、工具等)及其应用;2) 优化器torch.optim的使用;3) 训练、验证和测试的完整流程;4) 通过单层感知机实现二分类任务的实操示例。文章详细讲解了如何利用PyTorch内置模块构建神经网络模型,包括模型定义、损失函数选择、优化器配置以及训练过程的关键步骤,并提供了完
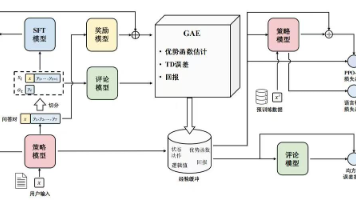
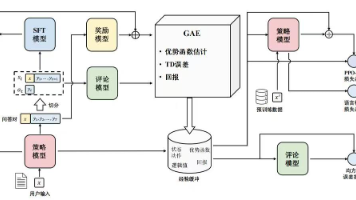
本文系统介绍了人类反馈强化学习(RLHF)的核心架构与实现方法。主要内容包括:1)强化学习基本要素与算法;2)演员-评论家架构的原理与优势;3)近端策略优化(PPO)的改进机制;4)DeepSpeed Chat的三阶段训练流程(SFT、奖励模型训练、策略优化)。文章还提供了RLHF开源数据集列表和代码实操示例,详细展示了Dahoas/rm-static数据集的读取方法。通过结合理论架构与工程实践,
自注意力机制让序列中的每个Token(如单词、字符)都能“关注”到序列中所有其他Token,并根据关联强度分配权重,最终生成融合全局上下文的Token表示。通俗理解:好比阅读时,每个词都会“回头看”全文,重点关注与自己语义相关的词(如“他”会关注前文提到的人名),忽略无关词。核心优势:并行计算(O(n²)时间复杂度,n为序列长度),效率远超RNN的O(n)串行;长距离依赖捕捉能力强(无距离限制,不
本文介绍了一种基于Arduino的智能植物养护系统设计方案。系统通过土壤湿度传感器(A0引脚)监测土壤含水量,采用10次采样取平均值的滤波算法,将原始模拟值转换为0-100%的湿度百分比。控制逻辑采用双阈值设计(35%启动水泵,70%停止),并设置5秒强制停止保护。光照控制通过数字光敏传感器(D3引脚)实现,低电平触发补光灯。硬件配置包括继电器模块(D1控制水泵,D2控制补光灯)和ESP8266

本文设计了一种基于STM32的罐装水泥成分实时检测系统,采用电容传感技术解决传统离线检测的滞后性问题。系统由传感器层、STM32控制层和远程监控层组成,通过DMA模式数据采集和三级滤波算法(3σ准则、滑动平均、归一化)处理高粉尘振动环境下的噪声干扰。引入温湿度补偿模型,建立电容值-水分含量线性关系,并设计趋势分析防误报逻辑。实验表明,系统在模拟工况下静态精度达±0.03%,动态响应0.8秒,24小

本文介绍了PyTorch中构建神经网络的核心组件和使用方法。主要内容包括:1) torch.nn模块的核心组件(层、损失函数、工具等)及其应用;2) 优化器torch.optim的使用;3) 训练、验证和测试的完整流程;4) 通过单层感知机实现二分类任务的实操示例。文章详细讲解了如何利用PyTorch内置模块构建神经网络模型,包括模型定义、损失函数选择、优化器配置以及训练过程的关键步骤,并提供了完
本文系统介绍了人类反馈强化学习(RLHF)的核心架构与实现方法。主要内容包括:1)强化学习基本要素与算法;2)演员-评论家架构的原理与优势;3)近端策略优化(PPO)的改进机制;4)DeepSpeed Chat的三阶段训练流程(SFT、奖励模型训练、策略优化)。文章还提供了RLHF开源数据集列表和代码实操示例,详细展示了Dahoas/rm-static数据集的读取方法。通过结合理论架构与工程实践,
本文介绍了人类反馈强化学习(RLHF)中的奖励模型训练和RLHF微调流程。奖励模型训练核心是通过成对排序学习区分优质和劣质回答,包含模型初始化、数据处理、损失计算等步骤。关键点包括:1)使用LLaMA模型作为基础架构;2)通过v_head将隐藏状态映射为奖励值;3)采用logsigmoid损失函数优化排序效果。RLHF微调阶段采用演员-评论家框架,涉及4个模型协同工作:生成模型(演员)、评论模型(