- @2301_79097795
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
innoDB使用的是聚集索引,将主键组织到一棵B+树中,而行数据就储存在叶子节点上,若使用"where id = 14"这样的条件查找主键,则按照B+树的检索算法即可查找到对应的叶节点,之后获得行数据。1.1版本中增加了host处理,在HTTP1.0中认为每台服务器都绑定一个唯一的ip地址,因此在URL中并没有传递主机名,但是随着虚拟机技术的发展,可能在一台物理机器上存在多个虚拟主机,并且他们共享

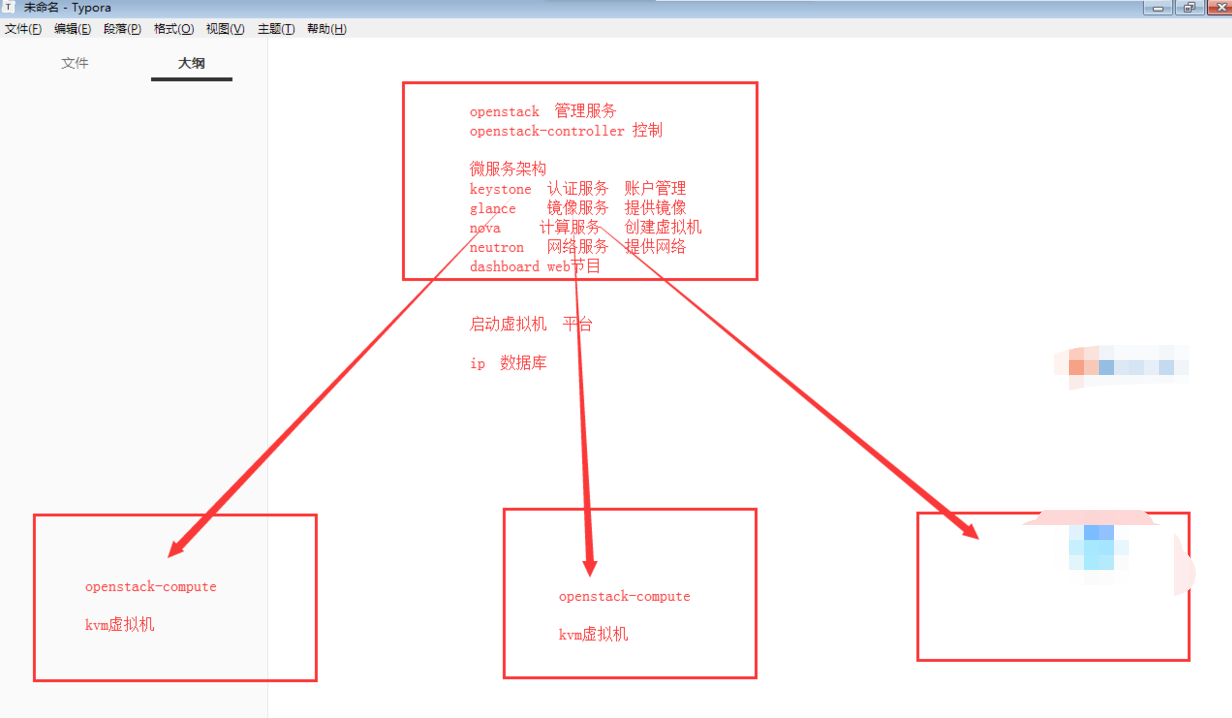
openstack基础架构2. 使用脚本自动化部署openstack M版需要的脚本软件下载链接 提取码: v4nf自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。深知大多数大数据工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵

是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新**(img-OhcTJw6m-1713105555022)]#上传docker_nginx1.15的镜像包,并打标签。#创建k8s_rc2.yaml 配置文件。#检查当前nginx_1.13的版本。#确保标签一样,修改为myweb。#查看svc的两种方法。#查看端口是否暴露成功。#另一

14行:KUBELET_API_SERVER=“–api-servers=http://10.0.0.11:8080”2016年,kubernetes干掉两个对手,docker swarm,mesos1.2版。谷歌15年容器使用经验,borg容器管理平台,使用golang重构borg,kubernetes。22行:KUBE_MASTER=“–master=http://10.0.0.11:8080

外链图片转存中…(img-pINclNOK-1713105649499)][外链图片转存中…(img-F7eWqdzV-1713105649500)][外链图片转存中…(img-5BrGpa1u-1713105649500)][外链图片转存中…(img-G42zUAWN-1713105649500)]
监控告警 | 支持 | 支持 || 是否能暂停和恢复 | 支持暂停,恢复操作 | 不支持 || 是否支持多租户 | 支持,easyscheduler上的用户可以通过租户和hadoop用户实现多对一或一对一的映射关系,这对大数据作业的调度是非常重要的。| 不支持 |

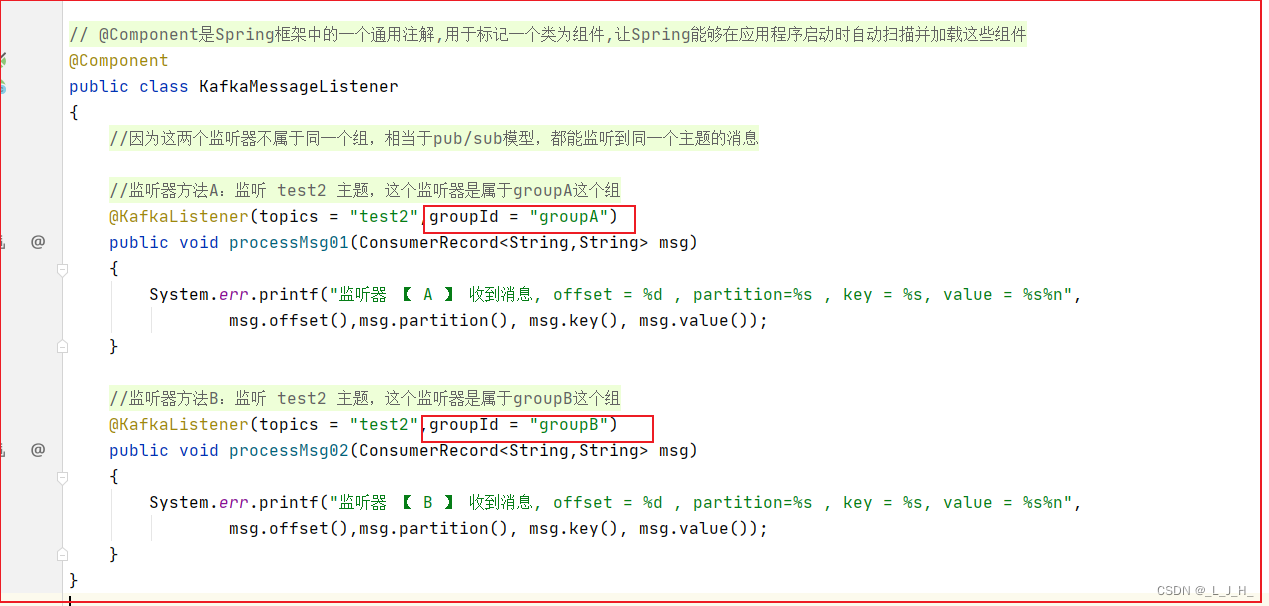
test2 主题有4个分区,然后我们写了两个监听器,那么kafka 就会为这两个监听器分配它们去监听哪个分区的消息,以为分配是以轮询的方法分配的。所以刚好一个监听器被分配去监听2个分区。分区分配规则因为同一个key的消息,无论发送多少条,一般都是发往同一个分区的,和上面说的同一个组的监听器,以轮询的方式监听同一个主题的消息时,两者并不冲突,需要结合具体的消息类型(这里说的是消息的key是否相同)来