- @2301_78285120
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
前馈神经网络 (Feedforward Neural Network) 是一种最基础的神经网络类型,它的信息流动是单向的,从输入层经过一个或多个隐藏层,最终到达输出层。数据输入格式通常需要与模型的输入接口相匹配,例如,对于文本模型,数据通常需要是字符串格式,并且可能需要经过特定的预处理,如分词、编码等。这种现象通常发生在大型模型中,原因是大型模型具有更高的表示能力和更多的参数,可以更好地捕捉数据中

原理是类似的,embedding 矩阵的初始化方式是 xavier,方差是 1/根号 d,因此乘以根号 d,可以让 embedding 矩阵的方差是 1,从而加速模型的收敛。举个例子:假如输入的原始句子是"我爱机器学习",我们按最简单的基于字的分词,这个样本的单词长度是 6,也就是 ‘我’ ‘爱’ ‘机’ ‘器’ ‘学’ ‘习’,这六个字。所以更深层的原因是,选择根号 d,可以让输入 softma

为了能以兼容openai标准的形式,在中调用国内常用的各种DeepSeek服务源,我们需要基于中的譬如,接入DeepSeek# 示例1:DeepSeek官方api_key='<填入你的key>'# 示例2:火山方舟api_key='<填入你的key>'# 示例1:DeepSeek官方# 这里deepseek-chat对应目前最新的非深度思考模型V3# 示例2:火山方舟'<请填写你在火山方舟控制中创

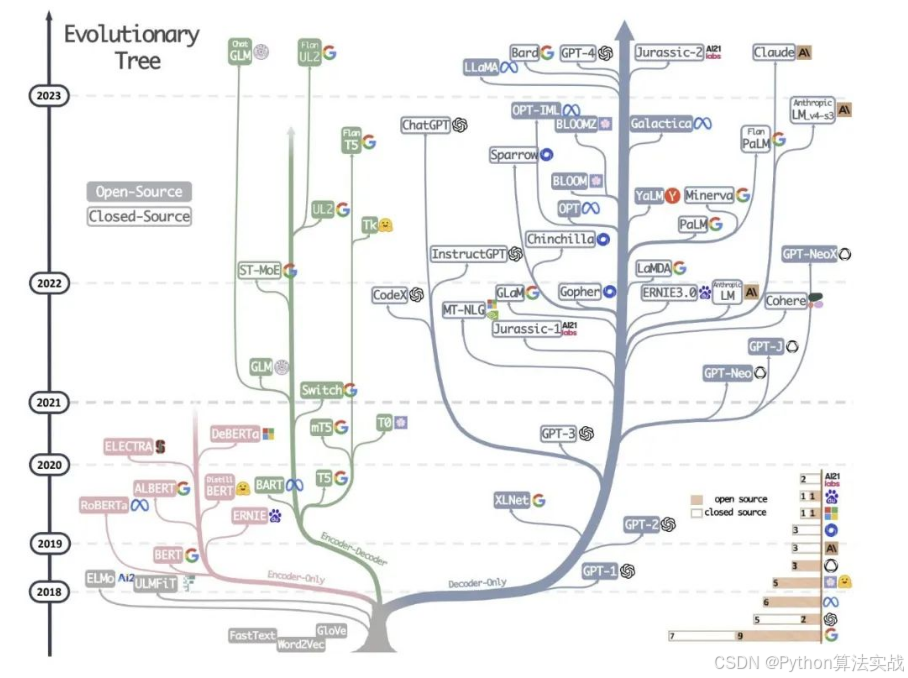
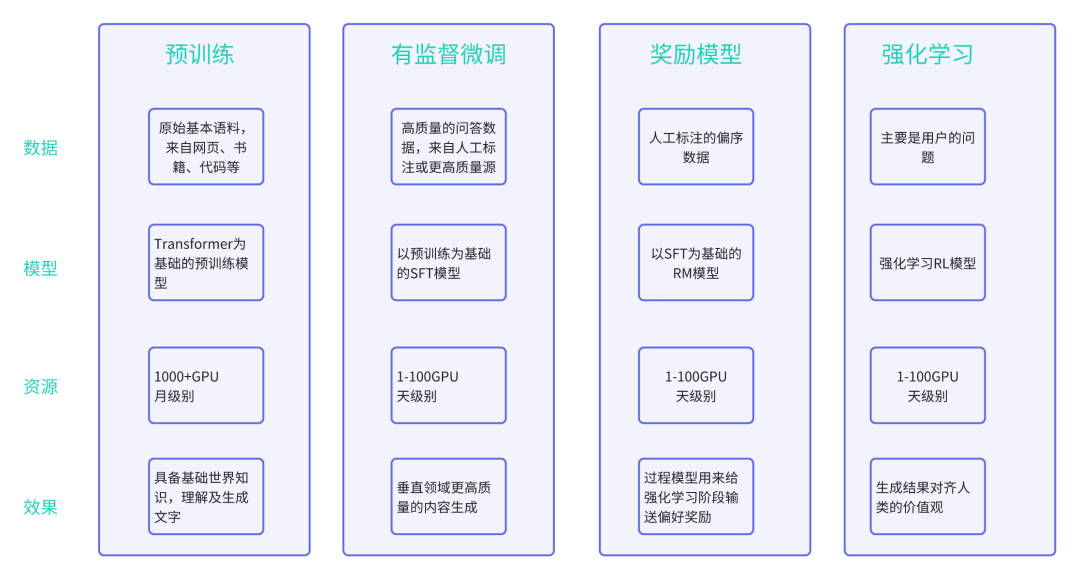
最近已有不少大厂都在秋招宣讲了,也有一些在 Offer 发放阶段。节前,我们邀请了一些互联网大厂朋友、今年参加社招和校招面试的同学。针对新手如何入门算法岗、该如何准备面试攻略、面试常考点、大模型技术趋势、算法项目落地经验分享等热门话题进行了深入的讨论。大语言模型的构建过程一般分为两个阶段,即:预训练、人类对齐(对齐再细分为指令微调+基于人类反馈强化学习)预训练-数据准备流程原始语料库:为了构建功能
最近已有不少大厂开启春招宣讲了。节前,我们邀请了一些互联网大厂朋友、今年参加社招和校招面试的同学。针对新手如何入门算法岗、该如何准备面试攻略、面试常考点、大模型技术趋势、算法项目落地经验分享等热门话题进行了深入的讨论。随着DeepSeek爆火,面试中也越来越高频出现,因此训练营也更新了DeepSeek系列技术的深入拆解。包括MLA、MTP、专家负载均衡、FP8混合精度训练,Dual-Pipe等关键

以上4个阶段构成了完整的GPT模型训练的pipeline,从中可以看出训练大模型是一个非常艰巨的任务,例如对庞大算力资源的要求、对高质量语料数据的要求。另外,在训练大模型的时候一般需要基于一些优化框架,如DeepSpeed,这些工程化方面的任务也有不少坑。因此,对于一般的企业而言通常不建议自己训练基础大模型,如果必须进行私有化部署,可以根据实际情况选择一款开源大模型,如有必要可基于开源大模型进行微

Qdrant:优点:中规中矩,Qps 相对较高、延迟相对较低。在CPU和磁盘IO方面的利用率较高,能够在处理高负载时提供较好的性能。缺点:在大数据集的加载时间和总体检索精度上略逊于 Milvus,适合对过滤查询有需求但不追求极端性能的场景。对CPU和内存的需求较大,尤其在高并发和复杂查询时可能会出现较高的资源消耗,导致系统负载上升。Chroma:优点:对于较小的数据集,Chroma 更容易上手和集

随着DeepSeek爆火,面试中也越来越高频出现,因此训练营也更新了DeepSeek系列技术的深入拆解。包括MLA、MTP、专家负载均衡、FP8混合精度训练,Dual-Pipe等关键技术,力求做到全网最硬核的解析~本篇文章主要对训练 LLM 以及部署应用时的精度问题进行了一些探讨和实践,读过后应该会对常用的浮点数 FP16,FP32,BF16 有一个更好的理解~

最近已有不少大厂都在秋招宣讲了,也有一些在 Offer 发放阶段。节前,我们邀请了一些互联网大厂朋友、今年参加社招和校招面试的同学。针对新手如何入门算法岗、该如何准备面试攻略、面试常考点、大模型技术趋势、算法项目落地经验分享等热门话题进行了深入的讨论。RAG 是目前大语言模型相关最知名的工具之一,从外部知识库中检索事实,以便为大型语言模型 (LLM) 提供最准确、最新的信息。但 RAG 并不完美,
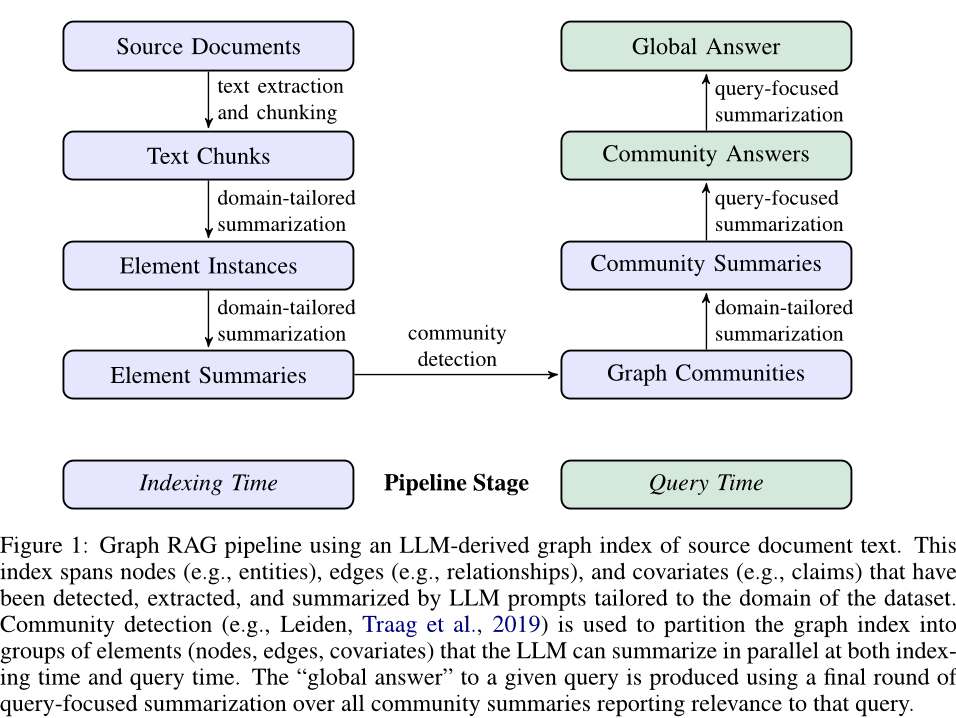
T5 Scale up 到 100B、500B 的难度很大,训练成本的增加远远高于 GPT。因此也许 100B 的 T5 训练 10T tokens 的模型能力比 100B 的 GPT 更强,但为此要支付的算力/时间成本远大于 100B GPT 训练 10T tokens。以至于:没有公司愿意支付这样的代价我还不如支付相同的代价,让 GPT 多训练更多倍的 Tokens;或者训练一个参数量大很多的