




- @2301_76901778
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
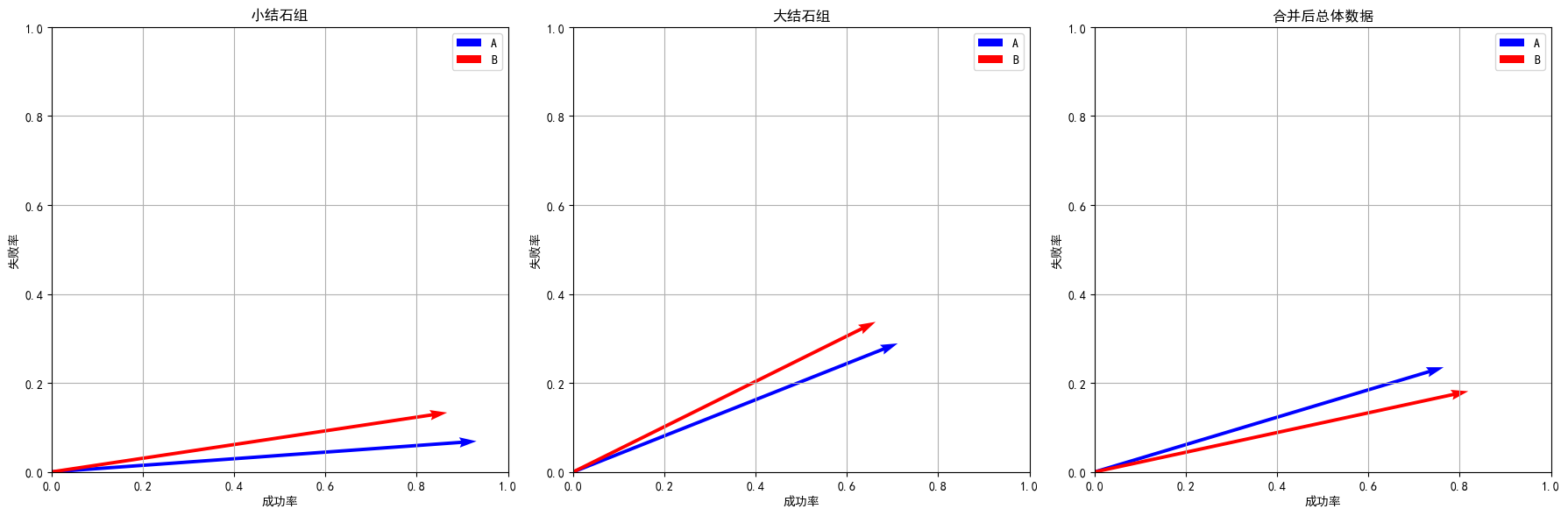
辛普森悖论(Simpson’s Paradox)指的是在分组数据中,各组内呈现某一趋势或结论,但当将所有组的数据合并后,整体数据却呈现相反趋势的现象。这种现象通常说明在数据聚合过程中,存在混杂或隐含的影响因素,使得分组内的真实关系被整体数据的权重分布所扭曲。假设在两组人群中比较两种治疗方法 A 和 B,分组统计显示在每个子组中治疗 A 的成功率均高于治疗 B;但将两个子组数据合并后,治疗 B 的总
超级详细的部署Hadoop,包括部署前的所有安装准备,克隆虚拟机、免密登录、JDK的安装、伪分布部署和完全分布式部署

词袋模型是一种将文本表示成向量把一个文本视作“装满单词的袋子”,忽略单词出现的顺序和语法信息构造一个词汇表(词典),然后统计文档中每个词汇出现的次数得到的向量维度等于词典中不同词的数量,向量的每个元素通常代表相应单词的词频(TF,Term Frequency)忽略了单词之间的顺序和上下文信息对常见无意义词(例如停用词)的区分能力较差。
K-Means 聚类是一种基于质心(centroid)的无监督学习方法,用于将 n 个样本划分到 K 个簇(cluster)中,使得同一簇内的样本彼此相似度高,不同簇间的样本差异大。选择折线图的拐点变缓处(降低的幅度变小的)作为最佳K值(详细如何选择可查看下文的“2.6 肘部法”,这里查看上图可选择3或4),这里可以根据SSE的变化趋势选择拐点,也可以根据其他评估指标选择最佳K值。M越大,客户越重

Excel计数函数(count、counta、countif、countblank、countifs)、求和函数(sum、sumif、sumifs、sumproduct)、统计函数(average、average、averageif、averageifs)、计算类函数(min、max、mod、rank、round、floor、rand、int、randbetween、stdev、var、large
大数据Hadoop中MapReduce的介绍包括编程模型、工作原理(MapReduce、MapTask、ReduceTask、Shuffle工作原理)通俗易懂的学习笔记

在实际的开发环境中,服务器每天都会产生大量的日志文件,这些日志文件会记录服务器的运行状态。当服务器宕机时,可以从日志文件中查找服务器宕机原因,从而尽快让服务器恢复正常运行。这个案例演示如何通过Shell脚本周期性的将Hadoop的日志文件上传到HDFS。

随机变量取值设随机变量XXXX1表示成功(例如“正面”、“合格”等)0表示失败(例如“反面”、“不合格”)X=1,& \text{表示成功(例如“正面”、“合格”等) } \\0, & \text{表示失败(例如“反面”、“不合格”)}X10表示成功(例如正面合格等)表示失败(例如反面不合格参数成功的概率记为ppp(其中0≤p≤100≤p≤100≤p≤10),失败的概率则为1−p1−p1−p。
优势比反映的是在两种条件下某事件发生与不发生的比值之比,是病例对照研究中常用的指标。患病不患病暴露ab不暴露cd\begin{array}{c|cc} & \text{患病} & \text{不患病} \\ \hline \text{暴露} & a & b \\ \text{不暴露} & c & d \\ \end{array}暴露不暴露患病ac不患病bdaaa表示既暴露又患病的人数,b
算法类型扫描方向优点缺点正向最大匹配从左向右实现简单、速度快易产生歧义,依赖词典完整性逆向最大匹配从右向左能在部分情况避免正向匹配的歧义同样依赖词典,部分情况下分词结果也可能不准确双向最大匹配双向对比综合两者优点,结果更合理算法复杂度高,仍受词典质量影响注意:三种算法都依赖于词典,词典不全或质量较低都会影响分词结果。分词过程中的歧义问题往往需要结合上下文或引入统计信息、机器学习方法(如 HMM、C