




- @zouyang920
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Web是一种基于互联网的技术和资源的网络服务系统。它是指由许多互连的计算机组成的全球性计算机网络,使用户能够通过浏览器访问和交互式使用各种信息和资源,如网页、文档、图片、视频、音频等。通过Web,用户可以浏览网页、发送电子邮件、参与在线社交网络、进行在线购物等各种活动。Web的核心技术包括超文本传输协议(HTTP),超文本标记语言(HTML)和统一资源定位器(URL)。鸿蒙的应用有时需要集成别的项

Web是一种基于互联网的技术和资源的网络服务系统。它是指由许多互连的计算机组成的全球性计算机网络,使用户能够通过浏览器访问和交互式使用各种信息和资源,如网页、文档、图片、视频、音频等。通过Web,用户可以浏览网页、发送电子邮件、参与在线社交网络、进行在线购物等各种活动。Web的核心技术包括超文本传输协议(HTTP),超文本标记语言(HTML)和统一资源定位器(URL)。鸿蒙的应用有时需要集成别的项
在鸿蒙(HarmonyOS)应用中,乘客输入密码支付的流程通常由华为支付(HUAWEI IAP)SDK内部处理,开发者无需直接编写密码输入界面。

Step 3:主线程实现(UI + 图片选择 + Worker 通信)Step 2:编写 Worker 子线程脚本(滤镜处理逻辑)Step 1:创建项目与配置 Worker。

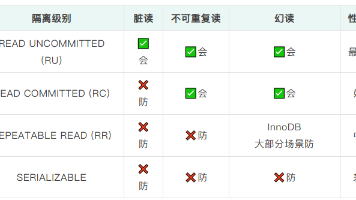
摘要:本文介绍了事务的ACID特性(原子性、一致性、隔离性、持久性),重点分析了隔离性的复杂性,指出完全隔离会降低性能。SQL标准定义了4种隔离级别,不同数据库默认级别不同(MySQL为RR,PostgreSQL/Oracle为RC)。文中提供了查看和修改事务隔离级别的SQL语句示例,并提醒从PG转向MySQL时需注意隔离级别差异。文章内容待进一步补充完善。(149字)
本项目实现一个技术研究员智能体包含两个Agent,分别负责研究最新技术趋势并进行详细分析和撰写报告,并最终调用外部工具把生成的报告以PDF文件保存到本地researcher:role: > 高级技术研究员goal: > 研究 {topic} 的最新技术趋势并进行详细分析。backstory: > 你是该领域的技术专家,擅长探索技术前沿动态,深入挖掘最新技术发展趋势,并能够以简洁明了的方式将其呈现出

本项目实现一个营销战略协作智能体;实现如何让任务以格式化数据输出,如自定义JSON数据格式并最终以JSON格式输出。

本项目实现一个python编码智能体;通过三个角色(高级软件工程师,软件质量控制工程师,首席软件质量控制工程师)完成编码工作。

本文介绍了一个健康档案助手智能体项目,包含两个Agent:一个负责从私有健康档案库中检索内容,另一个负责分析健康数据并生成PDF报告。项目重点讲解了向量数据库的使用方法,包括文本预处理、向量计算和持久化存储到ChromaDB。代码实现了PDF文档的分段处理、向量化计算,以及封装了向量数据库操作类MyVectorDBConnector,提供文档添加和检索功能。通过配置不同API选项(OpenAI或O

crewAI的Pipelines功能实现多CrewAI工作流。(1)将crewai由0.55.2升级为0.74.2,crewai-tools由0.12.0升级为0.13.2(截止2024.10.19),并解决因版本升级出现的问题(2)改写crew.py代码实现crewai的pipelines功能(3)将pipelines功能集成到main服务中对外提供API接口服务,进行接口联调测试CrewAI中
