




- @z240626191s
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
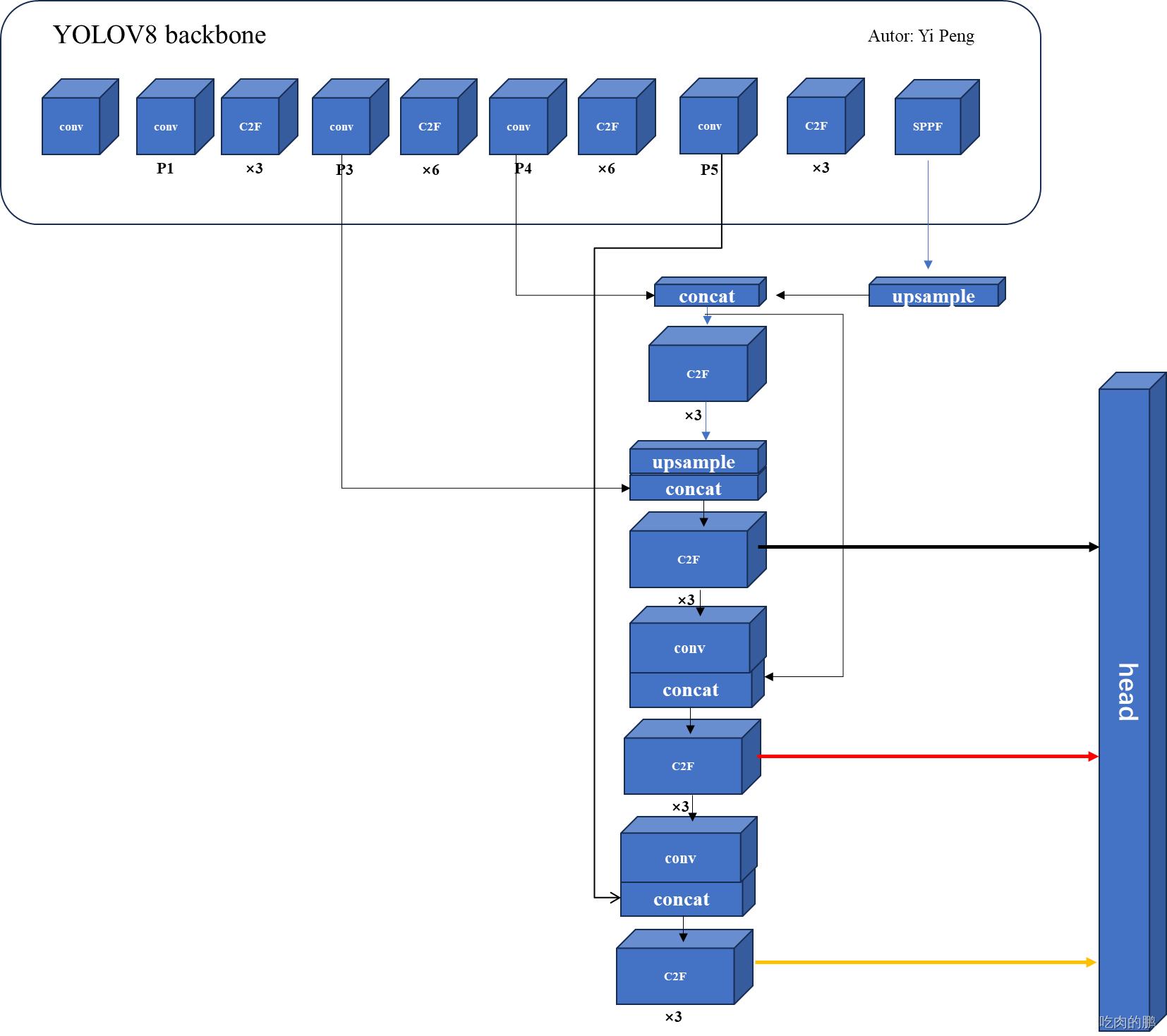
YOLOV8是一种先进的目标检测算法,能够在图像和视频中快速准确地识别多个对象。随着计算机视觉和深度学习技术的不断发展,YOLOV8已成为许多领域中的重要工具,包括智能监控、自动驾驶、工业检测等。然而,由于不同应用场景的差异,,因此对于提高检测精度和适应特定场景至关重要。本教程将向各位介绍,以便更好地满足个性化的目标检测需求。,本文章包含了YOLOV8网络结构图的详解。

Yolov8是2023年1月份开源的。与yolov5一样,支持目标检测、分类、分割任务。Yolov8依旧采用的CSP的思想,不过将Yolov5中的C3模块替换为C2F模块,进一步降低了参数量,同时yolov8依旧采用了yolov5中的SPPF模块;Yolov8依旧采用了PAN思想,只不过是将PAN中的上采样阶段中的卷积结构删除,将C3模块替换为了C2F模块;该方法是采用了YOLOX的head部分,
本项目开发了一个结合目标检测、跟踪和分类技术的学生行为检测系统,主要用于识别学生是否玩手机。系统基于YOLOv8、ResNet50等模型构建,支持图像/视频输入。数据集包含play_phone和person两类,训练集各8378和10422张,测试集各1897和1770张。项目提供完整的训练流程,包括数据预处理、模型训练(支持多种骨干网络)、性能评估(Top-1/Top-5准确率、F1值等)以及可

本文介绍了在Windows 11系统下远程调用树莓派USB摄像头的方法。首先需要在树莓派上运行一个Flask服务(video_stream.py),该服务通过OpenCV捕获摄像头画面并以MJPEG格式提供视频流。文中提供了完整的Python代码,包括摄像头初始化、帧生成和HTTP服务实现。启动服务后,可通过浏览器访问树莓派IP地址查看实时画面。同时给出了在本地电脑使用OpenCV接收视频流的客户

本文详细介绍了在树莓派4B上安装PyTorch的完整流程及注意事项。重点推荐使用Python3.9+OpenCV4.5.2.54+Torch1.11.0+Numpy1.26.4组合,并建议采用64位Bullseye系统。文章提供了百度网盘资源链接,包含所需镜像文件和安装工具,并分步说明了虚拟环境创建、依赖包安装及测试方法。针对32位系统(Python3.7)也给出了专门的安装指南,包括不同架构版本

当想把自己的一些项目代码开源到github上,这篇文章将会教如何上传自己的代码到github。我这里上传的是行人重识别(ReID).首先在github上注册自己的账号然后在右上角点击New,新建仓。输入你的项目名称(建议不要输入中文)点击下一步。现在回到本地,找到你自己的项目。进入项目文件夹后在空白地方右键,先择Git Bash Here【要在电脑上安装Git,网上下载安装就行,很容易】,因为我的
本文介绍了一个基于深度学习的人脸表情识别系统。该系统采用YOLO进行人脸检测,并使用Mobilenet或ResNet等网络进行表情分类。数据集包含5种表情(愤怒、恐惧、快乐、悲伤、惊讶),共18000张训练图片和2000张测试图片。训练过程支持GPU加速,通过30个epoch的冻结训练和100个epoch的完整训练,最终准确率达到91%。系统提供多种测试功能,包括单独的表情识别、人脸检测+表情识别

在人工智能的推动下,艺术创作正迎来前所未有的变革。风格迁移(Style Transfer)作为计算机视觉领域的一项经典技术,使我们能够在保留原始图像内容的同时,赋予其另一幅画作的独特艺术风格。无论是梵高的《星空》、莫奈的《睡莲》,还是毕加索的立体主义作品,风格迁移都能让普通照片焕发艺术光彩,化身为风格独特的艺术作品。在这篇博客中,我们实现了一个 风格迁移 Demo,旨在为初学者和毕业设计提供一个易
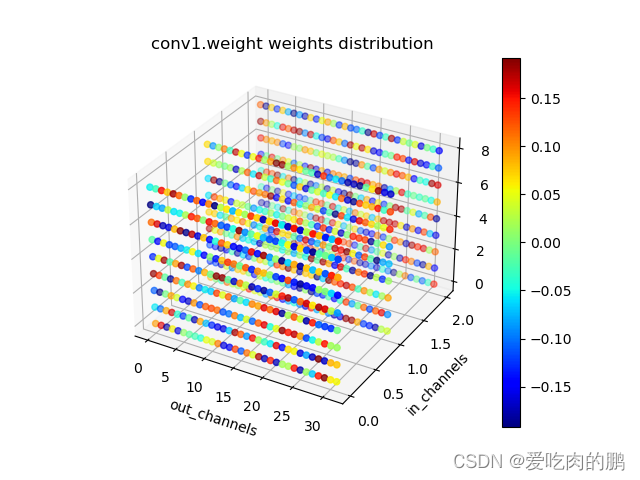
这两天自己手写了一个可以简单实现通道剪枝的代码,在这篇文章中也会对代码进行讲解,方便大家在自己代码中的使用。更新内容:2023.04.21更新内容:对上述剪枝代码进行了整理,同时加入了2D和3D权重的绘制。如果还想学习YOLO系列的剪枝代码,可以参考我其他文章,下面的这些文章都是我根据通道剪枝的论文在YOLO上进行的实现,而本篇文章是我自己写的,也是希望能帮助一些想学剪枝的人入门,希望多多支持:
本教程详细讲解如何在树莓派4B上部署YOLOv5目标检测算法,提供完整的实现方案。内容包括:环境配置指南(Python3.7、PyTorch1.8.1等依赖安装)、性能优化技巧(帧率提升200%+)、完整代码示例及实际效果演示。使用树莓派4B(4GB)+YOLOv5s模型作为演示平台,方法适用于其他型号。所需准备:树莓派4B、16GB TF卡、摄像头模块和基础Linux知识。教程从系统环境搭建开始
