- @yuezhiheng_hhh
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
码路星球(我不慌–成长杂货铺,https://wobuhuang.com)的 KMP 可视化把主串、模式串逐字符对齐,匹配/失配变色,next 指引模式串跳转的过程逐帧展示,配代码逐行高亮。朴素匹配在失配时把模式串后移一位、主串指针回退,最坏 O(nm)。KMP 利用模式串自身的前缀信息,失配时不回退主串指针,达到 O(n+m)。的最长"相等前后缀"长度。失配时,模式串不必从头开始,而是跳到 ne

快速排序、quick sort、分区 partition、C++、时间复杂度、数据结构、算法可视化
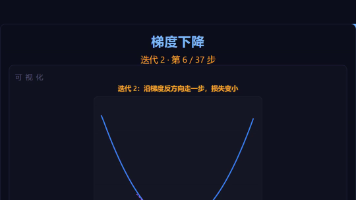
摘要:梯度下降是机器学习模型最小化损失函数的通用方法。其核心思想是沿梯度反方向迭代更新参数,梯度越大步长越大。学习率是关键超参数:太大会导致发散,太小则收敛慢。实际应用中可采用批量、随机或小批量梯度下降进行优化。文章通过C++代码示例演示了梯度下降的实现,并强调学习率调节和局部极值问题是主要挑战。理解梯度下降机制是掌握机器学习模型训练原理的基础。
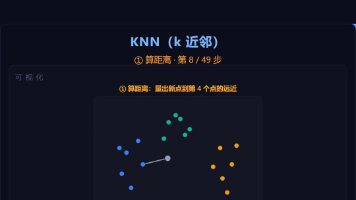
KNN(k近邻)是一种简单直观的有监督分类算法,属于懒惰学习方法。其核心原理是通过计算待分类点与训练数据的距离,选取最近的k个邻居进行投票分类。文章详细介绍了KNN的距离度量(欧氏/曼哈顿距离)、分类四步流程、k值选择对过拟合/欠拟合的影响、决策边界特征,并给出了C++实现代码。文章还分析了KNN的时间复杂度特点(训练快但预测慢)和维度灾难问题,最后总结了KNN简单易理解但计算效率低的特性。通过可
你不用懂复杂的数学,也能直接读出它"为什么这么判",所以它被称为典型的"白盒"模型。(个人主页:https://wobuhuang.com)

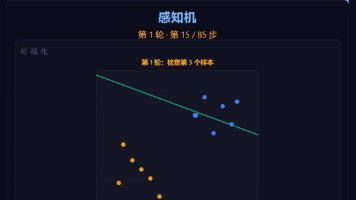
要解决异或这类线性不可分问题,就得叠加多层、引入非线性激活,再用反向传播来训练——这就是**多层感知机(MLP)**和深度学习的起点。引言:感知机诞生于 1958 年,是人们对“神经元”的第一次数学建模,也是今天每一个深度网络神经元的原型。在码路星球的可视化里,一条故意分错很多的初始边界,会一步步旋转纠正,最终全部分对。每遇到一个被分错的点,就把那条线朝它该在的一侧旋转/平移一点,反复几轮,线就稳
想直观看到核心点染色、向外扩张、噪声留灰的全过程,可以在「码路星球」看这套逐行代码高亮 + 动画的可视化讲解,完全免费,做任务还能得成长币。扫到一个核心点,它和邻域里的点一起被染上同一种颜色,一个新簇诞生;可视化用的数据是 28 个点:3 个密集簇 + 4 个离群噪声点,外加几个"靠簇但本身不够核心"的边界点,eps=42、minPts=3,过程清晰可复现。DBSCAN / 密度聚类 / 机器学习

要解决异或这类线性不可分问题,就得叠加多层、引入非线性激活,再用反向传播来训练——这就是**多层感知机(MLP)**和深度学习的起点。引言:感知机诞生于 1958 年,是人们对“神经元”的第一次数学建模,也是今天每一个深度网络神经元的原型。在码路星球的可视化里,一条故意分错很多的初始边界,会一步步旋转纠正,最终全部分对。每遇到一个被分错的点,就把那条线朝它该在的一侧旋转/平移一点,反复几轮,线就稳
摘要:梯度下降是机器学习模型最小化损失函数的通用方法。其核心思想是沿梯度反方向迭代更新参数,梯度越大步长越大。学习率是关键超参数:太大会导致发散,太小则收敛慢。实际应用中可采用批量、随机或小批量梯度下降进行优化。文章通过C++代码示例演示了梯度下降的实现,并强调学习率调节和局部极值问题是主要挑战。理解梯度下降机制是掌握机器学习模型训练原理的基础。
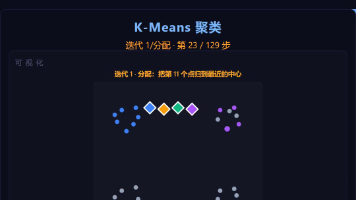
本文全面介绍了K-Means聚类算法的原理与实现。该无监督学习算法通过交替进行「分配」和「更新」两步迭代(将点归到最近中心,再将中心移至簇质心),直至收敛。文章包含算法图解、时间复杂度分析(O(n·k·t))、完整C++代码实现,并重点讨论了关键问题:如何选择K值(肘部法则)、初始值敏感性、球形假设局限性和数据归一化需求。K-Means以其简单高效著称,适用于球形分布且规模相近的簇,但需注意预处理