
决策树详解:从信息增益、基尼系数到逐层分裂与预测路径,一文搞懂决策树 C++ 实现(可视化白盒模型)
很多人第一次见决策树,会觉得它"高级",其实它是所有机器学习模型里最好懂的一个:一棵自动学出来的 if-else 判断树。你不用懂复杂的数学,也能直接读出它"为什么这么判",所以它被称为典型的"白盒"模型。(个人主页:https://wobuhuang.com)

一、它长什么样:内部节点 = 提问,叶子 = 类别
以"是否适合户外运动"为例:
- 内部节点:一次提问,比如"天气是什么?"“湿度高吗?”
- 边:提问的答案,比如 晴 / 雨
- 叶子:最终的类别,适合 / 不适合
从根一路问到叶子,就得到预测结果。
二、每个节点该用哪个特征分裂?信息增益 vs 基尼
树长出来的核心问题是:这一层该挑哪个特征来提问? 答案是——挑最能把不同类别区分开的那个。衡量"区分能力"的常见指标有三种:
- 信息增益(ID3):分裂后"纯度"提升了多少,本质是熵下降了多少。
- 信息增益比(C4.5):修正 ID3 偏爱"取值多"特征的毛病。
- 基尼指数(CART):另一种纯度度量,做二叉分裂。
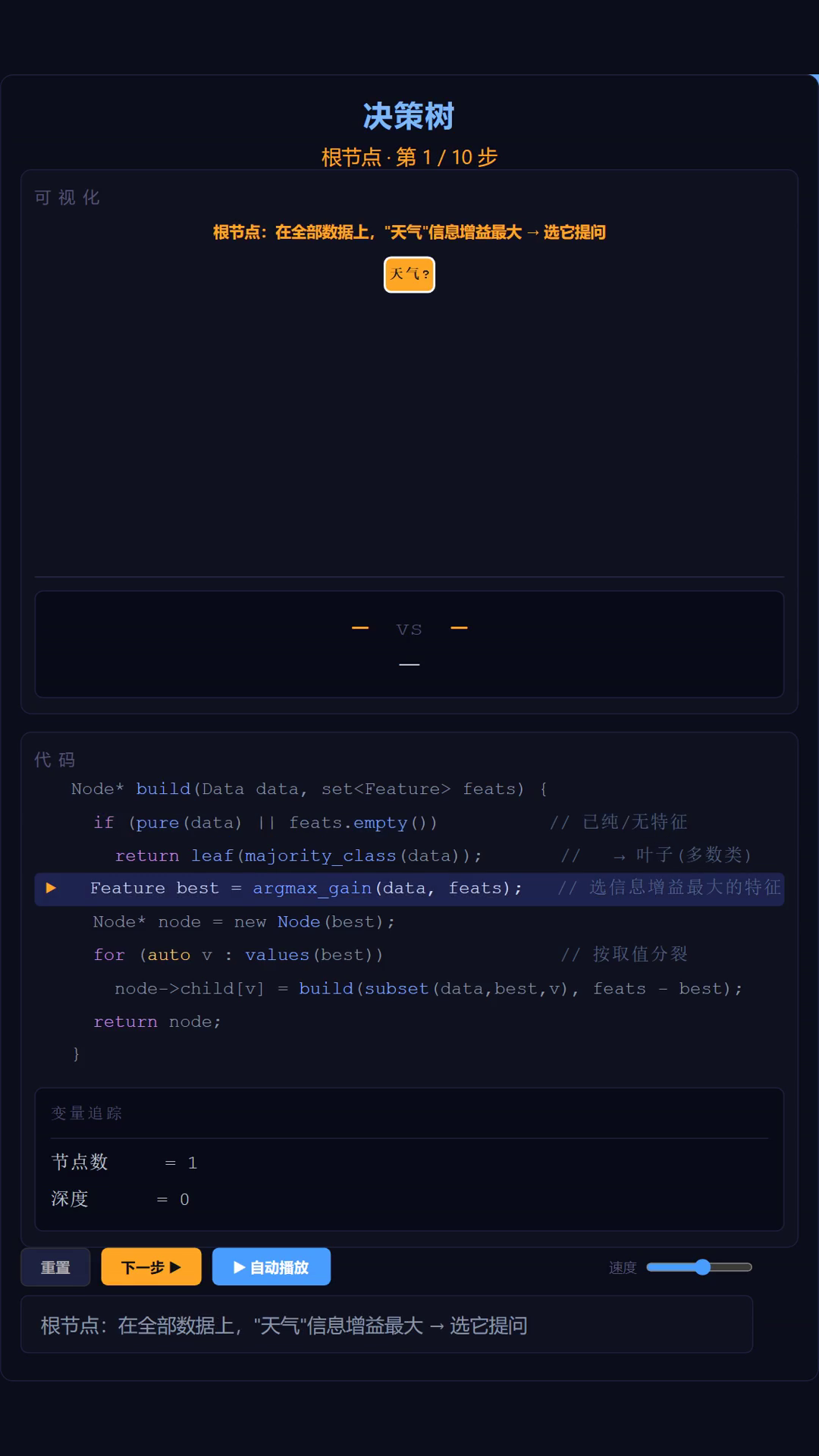
三、逐层分裂,纯度一步步提升
构建是一个递归过程:在全部数据上,“天气"信息增益最大 → 选它做根节点的提问;按取值(晴 / 雨)分裂成两堆;每一堆再在自己那份数据上重新挑最好的特征继续问。晴天这支选"湿度”,雨天这支选"有风",直到某堆基本同类(纯),就停下成为叶子。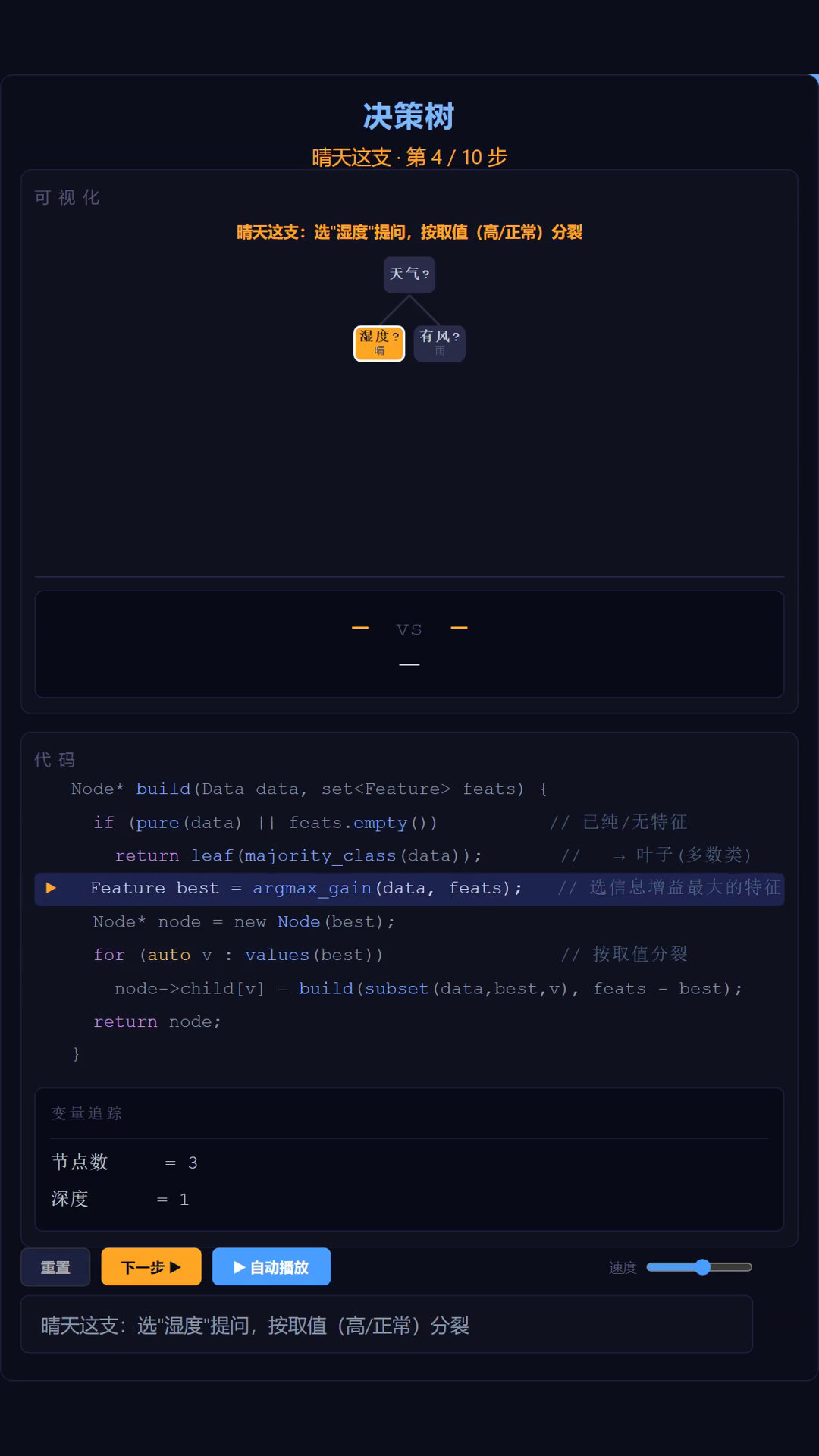
四、预测路径:新样本一路走到叶子
训练完成后预测非常直观:一个新样本"晴 + 湿度正常",沿着树走——天气 = 晴 → 湿度 = 正常 → 落到"适合"这个叶子。整条路径清清楚楚,这就是白盒模型的魅力。
五、完整 C++ 实现(带注释)
// 递归构建一棵决策树
// data:当前节点上的数据;feats:还能用来分裂的特征集合
Node* build(Data data, set<Feature> feats) {
if (pure(data) || feats.empty()) // 已纯 / 无特征可用
return leaf(majority_class(data)); // → 叶子(取多数类)
Feature best = argmax_gain(data, feats); // 选信息增益最大的特征
Node* node = new Node(best);
for (auto v : values(best)) // 按该特征的每个取值分裂
node->child[v] = // 子节点 = 对子集递归构建
build(subset(data, best, v), // subset:取出该取值的数据
feats - best); // 该特征用过后从集合移除
return node; // 返回构建好的(子)树
}
复杂度:训练约 O(n · 特征数 · 深度),空间 O(节点数)。预测就是从根走到叶子,深度有多深就问几次。
六、过拟合与剪枝
决策树最大的毛病是过拟合:如果让树无限生长,它能把训练集每个样本都背下来,训练误差降到 0,可一到新数据就崩。它还对噪声/小扰动敏感,数据稍变树就可能大变(高方差)。对策:
- 预剪枝:限制最大深度、限制叶子最小样本数,长到一定程度就停。
- 后剪枝:先长全,再把对验证集没帮助的分支砍掉。
七、小结
决策树 = 自动学出来的 if-else,靠信息增益 / 增益比 / 基尼挑分裂特征,逐层分裂提升纯度,预测就是走一条路径到叶子。单棵树往往不够强,实战常用随机森林、GBDT/XGBoost 把很多棵弱树集成起来。
想看决策树一层层长出来、再走一条预测路径的动画?在「码路星球」里全程免费看。(个人主页:https://wobuhuang.com)
决策树 / 机器学习 / 信息增益 / 基尼系数 / C++ / 算法可视化 / CART / ID3
更多推荐

 25
25 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)