




- @yaya_jn
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
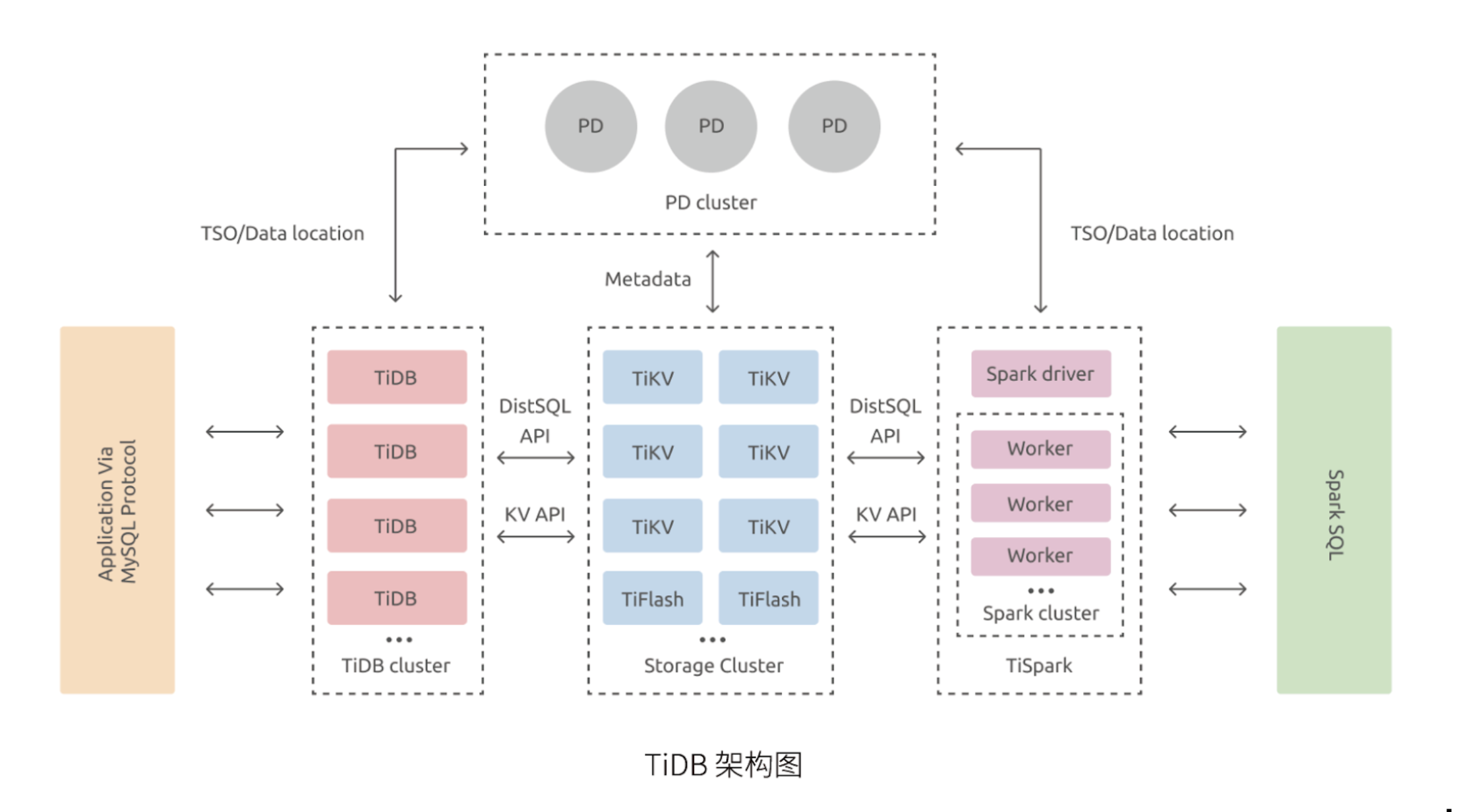
TiDB 是 PingCAP 公司自主设计、研发的开源分布式关系型数据库,是一款同时支持在线事务处理与在线分析处理 (Hybrid Transactional and Analytical Processing, HTAP) 的融合型分布式数据库产品,具备水平扩容或者缩容、金融级高可用、实时 HTAP、云原生的分布式数据库、兼容 MySQL 5.7 协议和 MySQL 生态等重要特性。
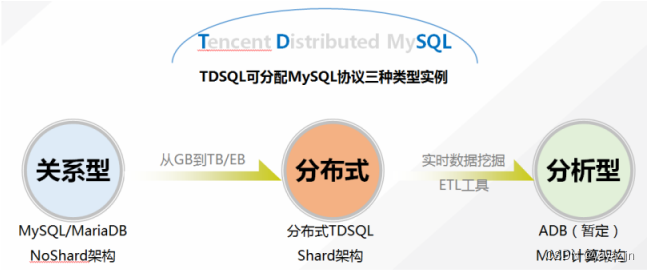
背景2019年公司搭建微服务平台,实现分布式部署,各服务性能及效率得到稳步提升,并已经趋于稳定。为了进一步提升服务性能,经过服务调研需要对Mysql数据服务进行高可用及高性能的升级。之前服务器部署采用服务器单独安装Mysql,经过2周的调研,对阿里云、腾讯云、亚马逊的Mysql服务进行调研比对,发现腾讯云的TDSQL实用性比较高。腾讯云TDSQL简介腾讯云数据库(TDSQL-Tencent Dis
【代码】机器学习---pySpark案例。

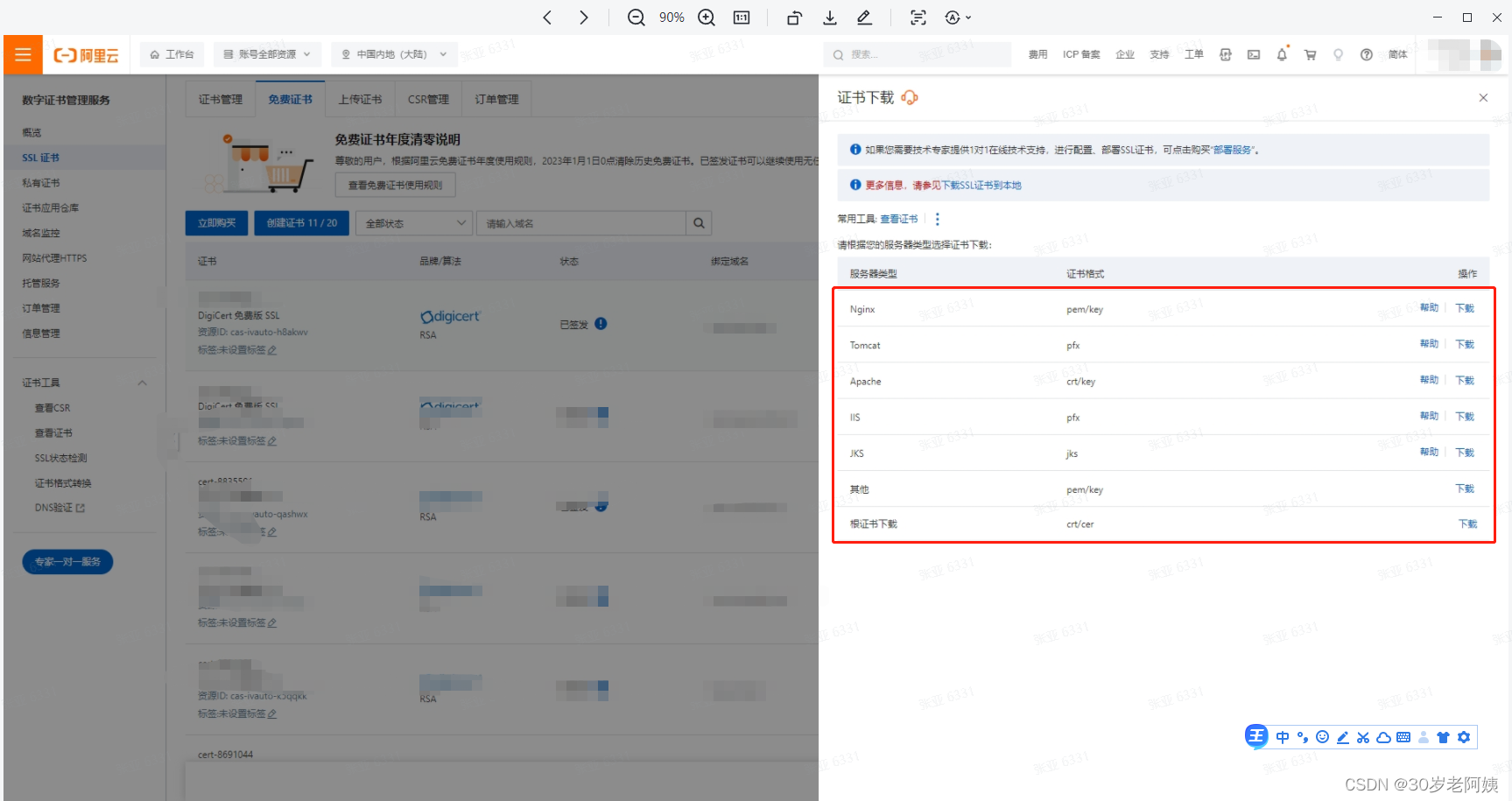
配置完了,发现ws不能使用了,还在研究,各位大神有办法,可以留言,互相学习。下面是下载的别人的案例,然后改了下我的案例,可以做下参考。3、因为netty仅仅支持pkcs8,所以将server.key 通过OpenSSl 生成pkcs8的版本。2、下载类型Tomcat的pfx 证书,在jdk的路径下cmd命令生成server.key文件。将证书放到外面,方便后期更换,毕竟免费的证书是一年一申请的,用
训练模型都会将数据集分为两部分,一般会将0.8比例的数据集作为训练集,将0.2比例的数据集作为测试集,来训练模型。模型过拟合就是训练出来的模型在训练集上表现很好,但是在测试集上表现较差的一种现象,也就是模型对已有的训练集数据拟合的非常好(误差值等于0),对于测试集数据拟合的非常差,模型的泛化能力比较差。训练出模型后,可以在训练集中测试下模型的正确率,在测试集中测试下模型的正确率,如果两者差别很大(
window安装python,配置python环境变量。安装python后,在环境变量path中加入安装的路径,cmd中输入python,检验python是否安装成功。注意:如果使用的是anaconda安装的python环境,建议安装python3.5.x版本,这个版本和spark1.6兼容。如何在anaconda中安装python3.5.x版本的python环境?参考文档:“Anaconda安装

【代码】机器学习---KNN案例。
要实现广告的精准投放,需要使用聚类找出兴趣一致的用户群体,这样就需要对用户进行聚类找出行为一致的用户,当对所有用户完成聚类之后,再使用关键词分析找出每个聚类群体中的用户的讨论主题,如果主题符合广告内容或者和广告内容相关,那么当前广告就可以推荐给当前用户群体,实现精准投放广告。
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一,有监督算法。该方法的思路是:如果一个样本在特征空间中的k个最相似的样本中的大多数属于某一个类别,则该样本也属于这个类别。KNN算法由你的邻居来推断出你的类别,KNN算法就是用距离来衡量样本之间的相似度。如果K = 3,绿色圆点的最近的3个邻居是2个红色小三角形和1个蓝色小正方
2)、预测道路的拥堵情况受当前道路附近道路拥堵的情况,受这几个道路过去几分钟道路拥堵的情况。预测道路拥堵情况可以根据附近每条道路和当前道路前3分钟道路拥堵的情况来预测。如果模型针对一条本来数据“畅通”分类的数据预测错了,那么预测结果错的情况下就不是只有“拥堵”这个情况,有可能是其他三类的一种,也有一定的概率预测分类为“比较畅通”,那么就相当于提高了模型的抗干扰能力。每条道路的拥堵情况不仅和当前道路