- @xu624735206
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
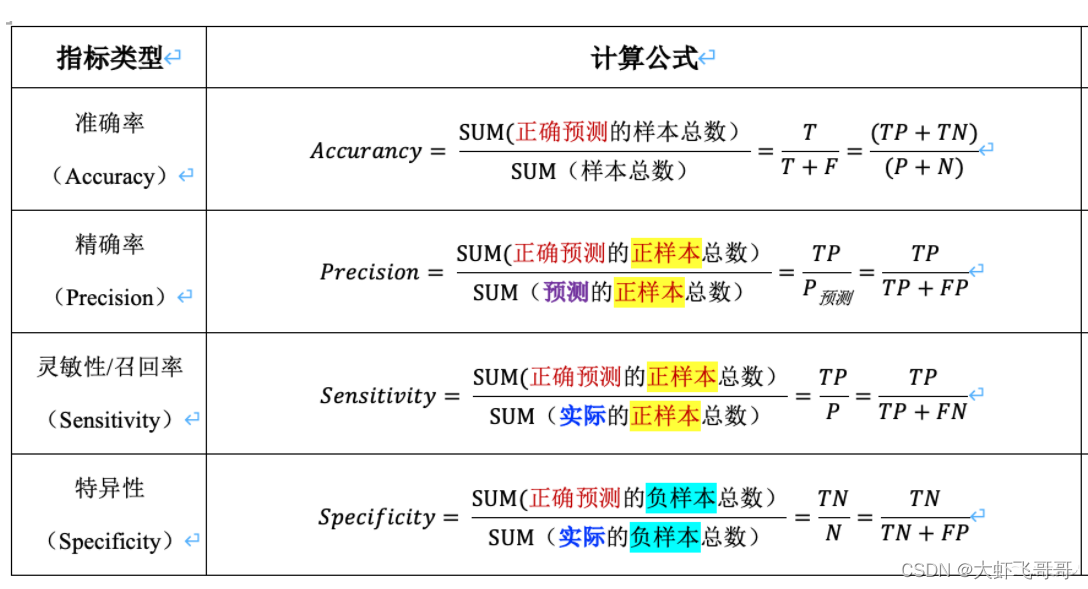
机器学习-准确率、灵敏度、特异度、PPV、NPV、F1计算方法计算方法计算方法
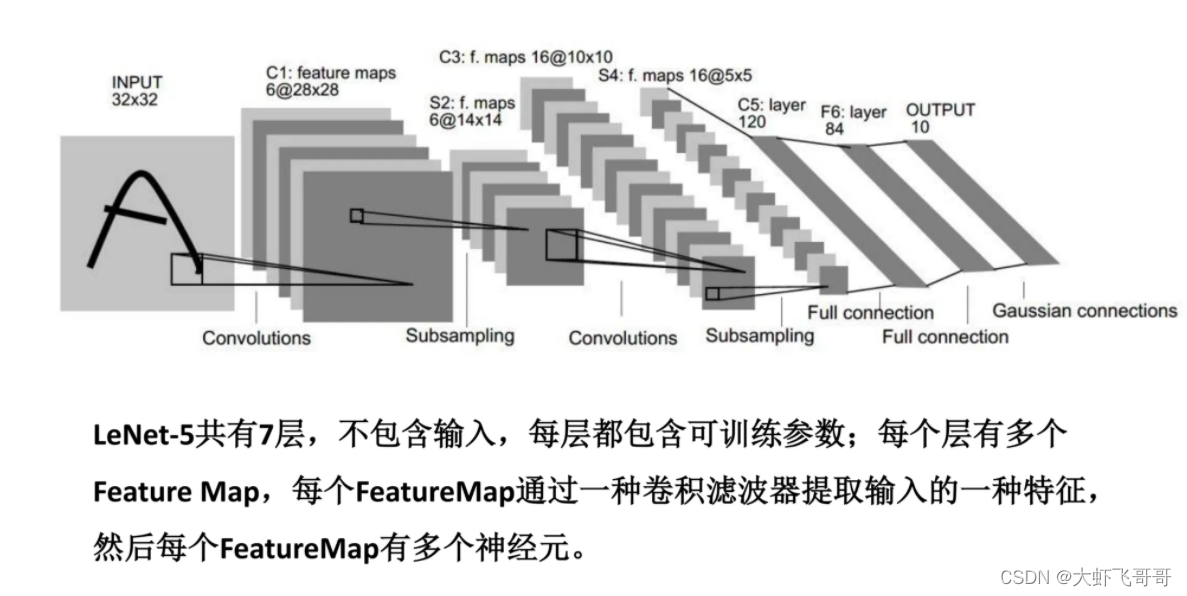
pytorch使用-Lenet实现一、Lenet实现网络图二、创建网络三、定义损失函数四、定义优化器一、Lenet实现网络图二、创建网络import torch.nn as nnimport torch.nn.functional as F# TODO: 构建神经网络class LeNet(nn.Module):def __init__(self):super(LeNet, self).__ini
pytorch设置随机种子 - 保证复现模型所有的训练过程在使用 PyTorch 时,如果希望通过设置随机数种子,在 GPU 或 CPU 上固定每一次的训练结果,则需要在程序执行的开始处添加以下代码:def seed_everything():'''设置整个开发环境的seed:param seed::param device::return:'''import osimport randomimp
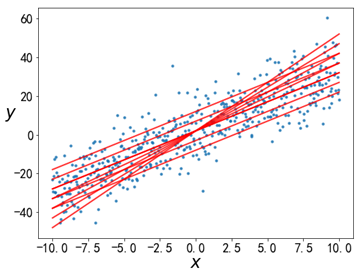
机器学习-线性回归一、线性回归概念二、怎样求解回归系数三、最小二乘法四、多元线性回归五、岭回归六、Lasso回归一、线性回归概念首先举个例子,我们去市场买牛肉,一斤牛肉52块钱,两斤牛肉104块钱,三斤牛肉156块钱,以此类推。也是说牛肉的价格随着牛肉斤数的增加而有规律地增加,这种规律可以下图表示:可以看到上述规律可以用一条直线来表述,这就是一个线性模型。用 𝑦𝑦y 表示牛肉斤数,用 $𝑥
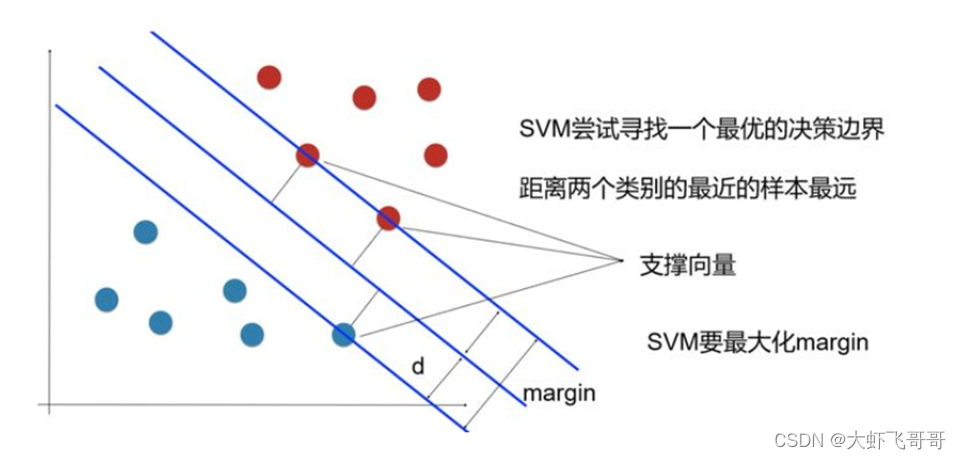
机器学校-SVM一、SVM提出二、SVM最优化问题三、为什么要求对偶问题四、SVM转换为对偶问题五、核函数一、SVM提出这里有两个类别的数据, class1 与class2,要把这两类分开。我们可以找到很多条直线将它们分开,只要位于两类数据之间即可,然而, 我们的目的不只是为了区分现有的两类数据, 我们真正想要达到的目的是: 当模型在现有数据训练完成后, 将其应用到新的数据时,我们仍然可以很好的区
机器学习特征选择方法介绍综述一、过滤法1.方差法二、使用步骤1.引入库2.读入数据总结欢迎使用Markdown编辑器新的改变功能快捷键合理的创建标题,有助于目录的生成如何改变文本的样式插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容居中、居左、居右SmartyPants创建一个自定义列表如何创建一个注脚注释也是必不可少的KaTeX数学公式新的甘特图功能,丰富你的文章U
DataFrame数据遍历一、读取csv内容,格式与数据类型如下二、按行遍历数据:iterrows三、按行遍历数据:itertuples四、按列遍历数据:iteritems四、读取和修改某一个数据五、遍历dataframe中每一个数据一、读取csv内容,格式与数据类型如下data = pd.read_csv('save\LH8888.csv')print(type(data))print(data
机器学习特征选择方法介绍综述一、过滤法1.方差法二、使用步骤1.引入库2.读入数据总结欢迎使用Markdown编辑器新的改变功能快捷键合理的创建标题,有助于目录的生成如何改变文本的样式插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容居中、居左、居右SmartyPants创建一个自定义列表如何创建一个注脚注释也是必不可少的KaTeX数学公式新的甘特图功能,丰富你的文章U
机器学校-SVM一、SVM提出二、SVM最优化问题三、为什么要求对偶问题四、SVM转换为对偶问题五、核函数一、SVM提出这里有两个类别的数据, class1 与class2,要把这两类分开。我们可以找到很多条直线将它们分开,只要位于两类数据之间即可,然而, 我们的目的不只是为了区分现有的两类数据, 我们真正想要达到的目的是: 当模型在现有数据训练完成后, 将其应用到新的数据时,我们仍然可以很好的区
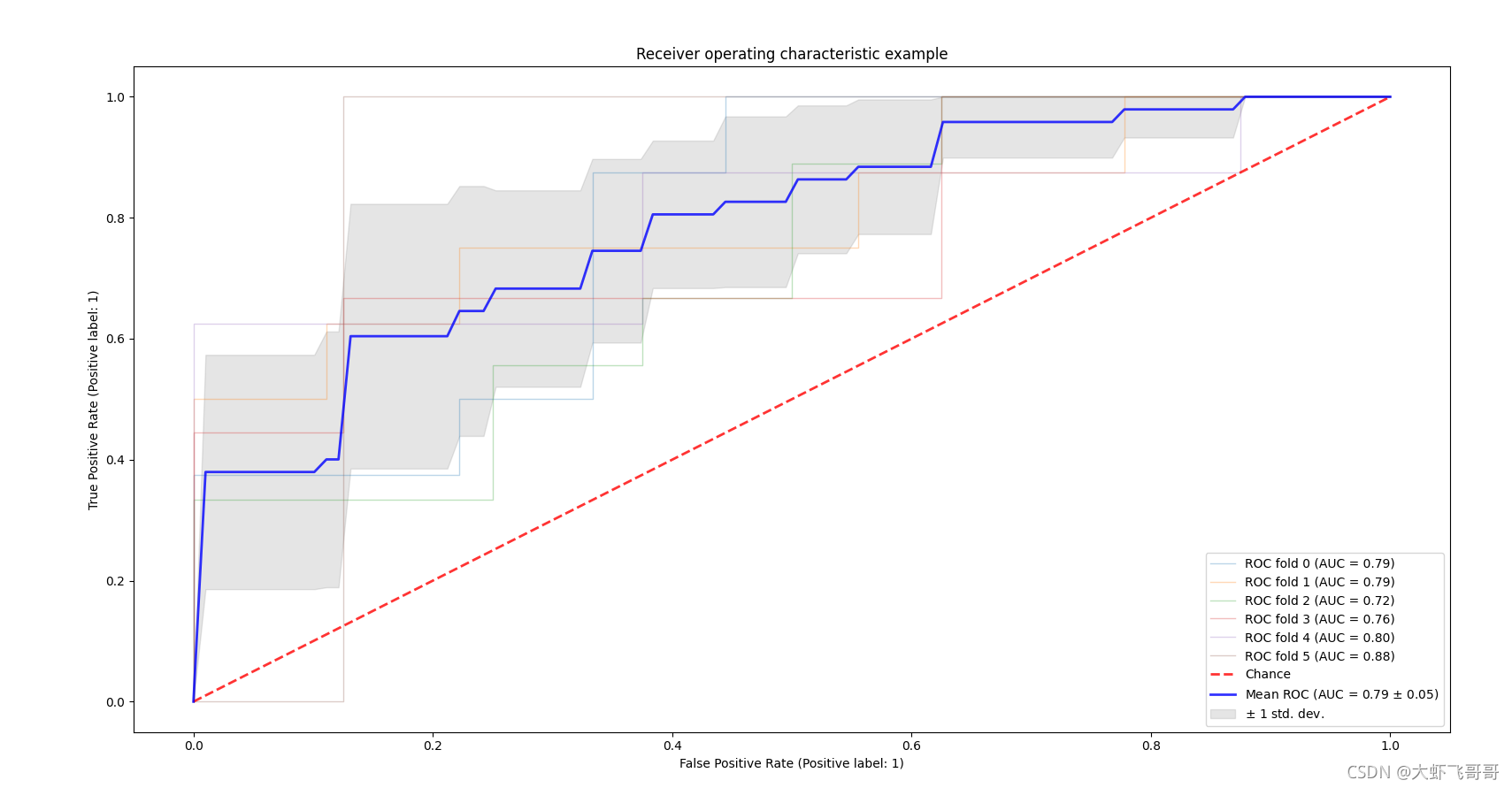
带交叉验证的ROC曲线前言一、程序如下二、效果图前言ROC曲线通常在Y轴上具有真正率(true positive rate),在X轴上具有假正率(false positiverate)。这意味着该图的左上角是“理想”点-误报率为零,而正误报率为1。这不是很现实,但这确实意味着,通常来说,曲线下的区域(AUC面积)越大越好。ROC曲线的“陡峭程度”也很重要,因为理想的是最大程度地提高真正率,同时最小