- @xdpcxq1029
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Redis在Linux系统上部署时需要注意多个内核参数优化:1. TCP backlog设置需与系统somaxconn参数匹配;2. 建议启用内存overcommit(vm.overcommit_memory=1);3. 应禁用透明大页(THP)以减少延迟;4. TCP keepalive默认300秒可提前发现异常连接;5. 支持CPU绑定优化性能;6. 通过oom-score-adj参数控制进程
RateLimit这个注解承载了限流的所有配置元数据。/*** 限流阈值 (QPS),默认每秒 5 个*//*** 获取令牌的策略* true: 阻塞模式(直到拿到令牌或超时)* false: 非阻塞模式(拿不到立即失败)*//*** 阻塞等待的超时时间(仅当 block=true 时生效)* 默认 0,表示无限等待*//*** 超时时间单位*//*** 预热时间* 默认 0 (SmoothBur

MySQL 5.6 虽无高版本的元数据原地修改优化,但通过显式指定简单默认值,可大幅降低 DDL 执行时间,是 2000 万行表的最优临时方案;锁表的核心根源并非 DDL 本身,而是MDL 锁等待 + 长事务阻塞,执行前清理锁源是避坑关键;Online DDL 的无锁特性仅存在于MDL 锁获取成功后(executing/copying to tmp table 状态),此阶段脱离锁表风险,后续仅存
做容器化部署时,单靠docker run命令逐个启动 MySQL、Redis、后端、Nginx 容器会非常繁琐 —— 不仅要记大量命令参数,还得手动控制容器启动顺序、配置网络联动,一旦服务器重启,所有容器要重新逐个启动,维护成本极高。是 Docker 官方的多容器编排工具,核心是通过一个配置文件,集中管理所有容器的等所有配置,能完美解决单容器部署的痛点。
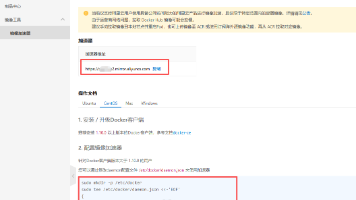
对于 jdbcTemplate transactionManager dataSource bookService 走的是默认命名空间的处理器, IOC标准解析流程, 不再啰嗦了[[Spring IOC 源码学习 XML详细加载流程总结]]i++) {if (node instanceof Element ele) {//是否 是元素标签/*** 处理默认命名空间的标签, 有如下四个*/else
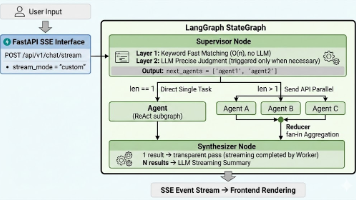
摘要:本文介绍了一个基于LangGraph的多Agent协作旅行助手系统,采用Supervisor+Worker并行架构处理复杂用户请求(如同时查询车次和天气)。系统通过双层路由(关键词匹配+LLM兜底)实现高效任务分发,利用SendAPI实现真正并行执行,并通过自定义Reducer解决状态共享问题。关键技术包括:1) 可视化思考链展示;2) 动态工具注册中心;3) 智能结果聚合策略;4) Pyt
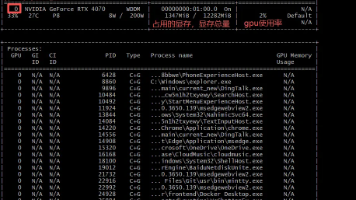
本文介绍了使用RTX 4070显卡和Ollama框架部署大语言模型的实践。主要内容包括:1)利用nvidia-smi工具监控GPU资源;2)通过Ollama部署Qwen3-8B对话模型和嵌入模型,实现按需加载和REST API调用;3)展示function calling功能,使LLM能调用外部工具获取实时数据。实验表明,RTX 4070能有效支持中小型模型的推理任务,显存占用约6GB,适用于交互
本文详细介绍了Oracle数据库密码过期问题的解决方案。主要内容包括:1. 使用SYSDBA权限登录数据库的两种方式;2. 查询和修改密码过期策略(包括全局设置和用户单独配置);3. 排查和处理过期/锁定用户的方法;4. 保留原密码的重置操作和手动修改密码的步骤;5. 生产环境操作注意事项和常见报错解决方案。重点提供了"保留原密码"的重置方案,通过提取sys.user$表中的密
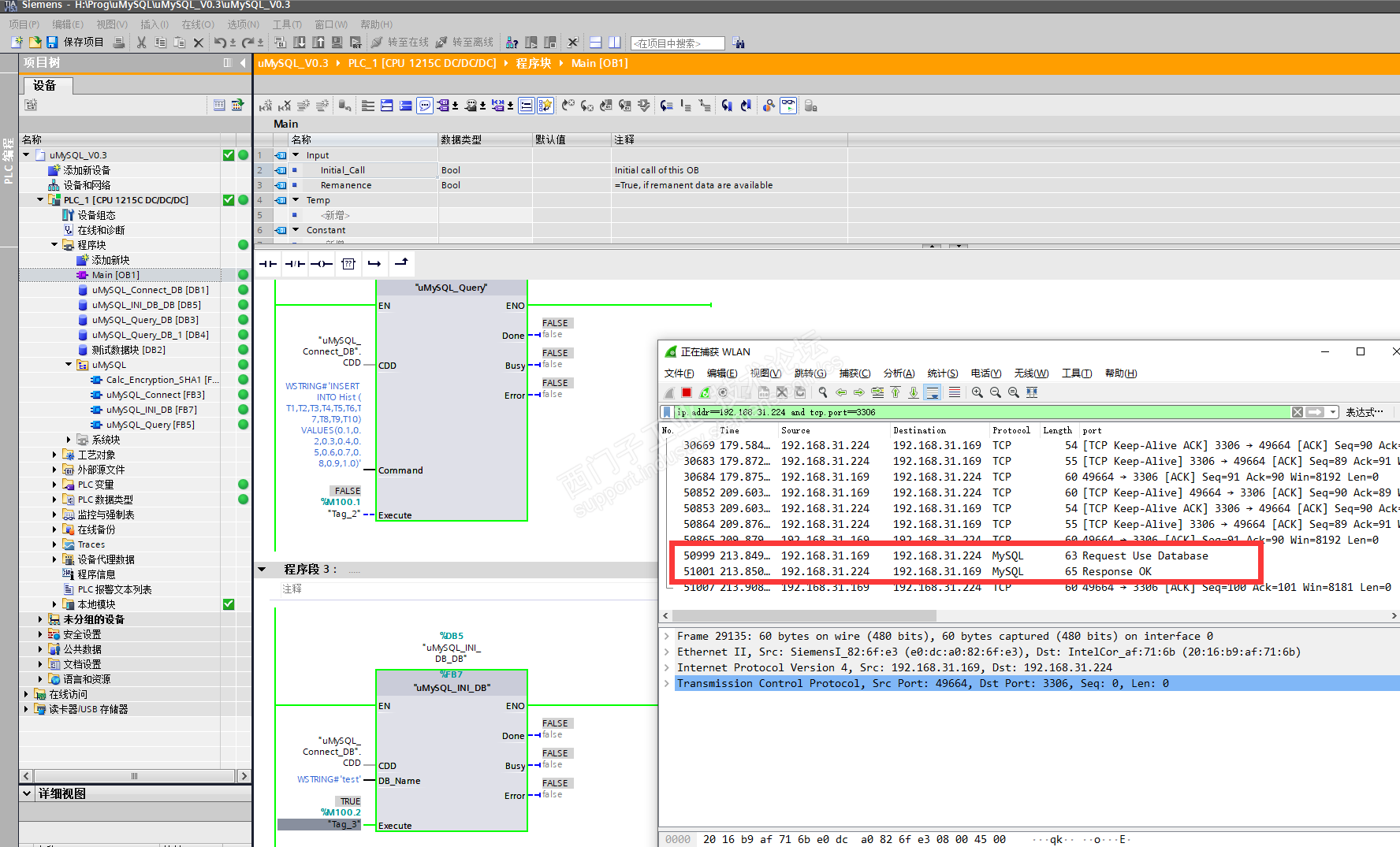
最近项目上有个需求,要把采集的数据存储到数据库中,当前西门子有很多方法,必读IDB,还有通过WINCC的脚本,第三方的软件等等,但是随着发展,有些需求希望设备直接到数据库,比如云端的RDS,可能现场不会有专门的电脑或者触摸屏用来运行脚本或者程序。因为通信还有点问题,待后续完善一下之后会把源文件共享给大家,希望做成一个开源的库文件,供大家使用。最近出图纸,还没时间完善,先打了个包,给大家发出来,可以
本文记录了在Windows系统搭配AMD显卡环境下成功编译ROCm版PyTorch并验证其性能的过程。通过构建一个经典的MNIST手写数字识别CNN模型,测试了ROCm环境下显卡识别、张量运算和模型训练等功能。实验采用包含卷积层和全连接层的简单CNN结构,相比传统全连接网络能更好地保留图像空间特征。测试结果显示,AMD Radeon RX6650XT显卡成功被识别,并在5.61秒内完成了500个b